 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Can Learn from Verbal Feedback Without Scalar Rewards
Sep 26, 2025
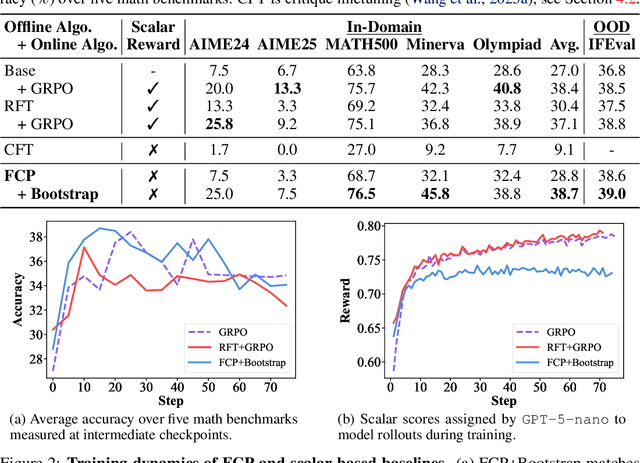
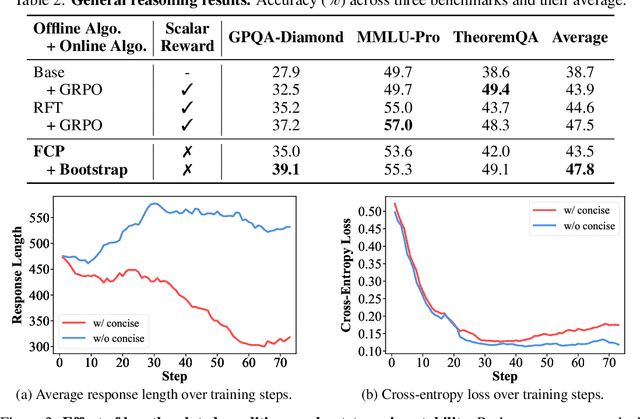
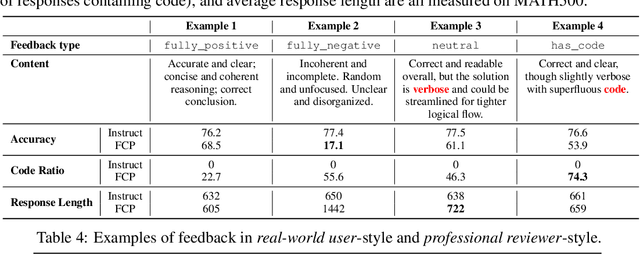
LLMs are often trained with RL from human or AI feedback, yet such methods typically compress nuanced feedback into scalar rewards, discarding much of their richness and inducing scale imbalance. We propose treating verbal feedback as a conditioning signal. Inspired by language priors in text-to-image generation, which enable novel outputs from unseen prompts, we introduce the feedback-conditional policy (FCP). FCP learns directly from response-feedback pairs, approximating the feedback-conditional posterior through maximum likelihood training on offline data. We further develop an online bootstrapping stage where the policy generates under positive conditions and receives fresh feedback to refine itself. This reframes feedback-driven learning as conditional generation rather than reward optimization, offering a more expressive way for LLMs to directly learn from verbal feedback. Our code is available at https://github.com/sail-sg/feedback-conditional-policy.
Through the Valley: Path to Effective Long CoT Training for Small Language Models
Jun 09, 2025Long chain-of-thought (CoT) supervision has become a common strategy to enhance reasoning in language models. While effective for large models, we identify a phenomenon we call Long CoT Degradation, in which small language models (SLMs; <=3B parameters) trained on limited long CoT data experience significant performance deterioration. Through extensive experiments on the Qwen2.5, LLaMA3 and Gemma3 families, we demonstrate that this degradation is widespread across SLMs. In some settings, models trained on only 8k long CoT examples lose up to 75% of their original performance before fine-tuning. Strikingly, we further observe that for some particularly small models, even training on 220k long CoT examples fails to recover or surpass their original performance prior to fine-tuning. Our analysis attributes this effect to error accumulation: while longer responses increase the capacity for multi-step reasoning, they also amplify the risk of compounding mistakes. Furthermore, we find that Long CoT Degradation may negatively impacts downstream reinforcement learning (RL), although this can be alleviated by sufficiently scaled supervised fine-tuning (SFT). Our findings challenge common assumptions about the benefits of long CoT training for SLMs and offer practical guidance for building more effective small-scale reasoning models.
UltraEval: A Lightweight Platform for Flexible and Comprehensive Evaluation for LLMs
Apr 11, 2024



Evaluation is pivotal for honing Large Language Models (LLMs), pinpointing their capabilities and guiding enhancements. The rapid development of LLMs calls for a lightweight and easy-to-use framework for swift evaluation deployment. However, due to the various implementation details to consider, developing a comprehensive evaluation platform is never easy. Existing platforms are often complex and poorly modularized, hindering seamless incorporation into researcher's workflows. This paper introduces UltraEval, a user-friendly evaluation framework characterized by lightweight, comprehensiveness, modularity, and efficiency. We identify and reimplement three core components of model evaluation (models, data, and metrics). The resulting composability allows for the free combination of different models, tasks, prompts, and metrics within a unified evaluation workflow. Additionally, UltraEval supports diverse models owing to a unified HTTP service and provides sufficient inference acceleration. UltraEval is now available for researchers publicly~\footnote{Website is at \url{https://github.com/OpenBMB/UltraEval}}.
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems
Feb 21, 2024



Recent advancements have seen Large Language Models (LLMs) and Large Multimodal Models (LMMs) surpassing general human capabilities in various tasks, approaching the proficiency level of human experts across multiple domains. With traditional benchmarks becoming less challenging for these models, new rigorous challenges are essential to gauge their advanced abilities. In this work, we present OlympiadBench, an Olympiad-level bilingual multimodal scientific benchmark, featuring 8,952 problems from Olympiad-level mathematics and physics competitions, including the Chinese college entrance exam. Each problem is detailed with expert-level annotations for step-by-step reasoning. Evaluating top-tier models on OlympiadBench, we implement a comprehensive assessment methodology to accurately evaluate model responses. Notably, the best-performing model, GPT-4V, attains an average score of 17.23% on OlympiadBench, with a mere 11.28% in physics, highlighting the benchmark rigor and the intricacy of physical reasoning. Our analysis orienting GPT-4V points out prevalent issues with hallucinations, knowledge omissions, and logical fallacies. We hope that our challenging benchmark can serve as a valuable resource for helping future AGI research endeavors.