 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemHC: Manifold-Constrained Hyper-Connections
Dec 31, 2025Recently, studies exemplified by Hyper-Connections (HC) have extended the ubiquitous residual connection paradigm established over the past decade by expanding the residual stream width and diversifying connectivity patterns. While yielding substantial performance gains, this diversification fundamentally compromises the identity mapping property intrinsic to the residual connection, which causes severe training instability and restricted scalability, and additionally incurs notable memory access overhead. To address these challenges, we propose Manifold-Constrained Hyper-Connections (mHC), a general framework that projects the residual connection space of HC onto a specific manifold to restore the identity mapping property, while incorporating rigorous infrastructure optimization to ensure efficiency. Empirical experiments demonstrate that mHC is effective for training at scale, offering tangible performance improvements and superior scalability. We anticipate that mHC, as a flexible and practical extension of HC, will contribute to a deeper understanding of topological architecture design and suggest promising directions for the evolution of foundational models.
A Multi-Power Law for Loss Curve Prediction Across Learning Rate Schedules
Mar 17, 2025Training large models is both resource-intensive and time-consuming, making it crucial to understand the quantitative relationship between model performance and hyperparameters. In this paper, we present an empirical law that describes how the pretraining loss of large language models evolves under different learning rate schedules, such as constant, cosine, and step decay schedules. Our proposed law takes a multi-power form, combining a power law based on the sum of learning rates and additional power laws to account for a loss reduction effect induced by learning rate decay. We extensively validate this law on various model sizes and architectures, and demonstrate that after fitting on a few learning rate schedules, the law accurately predicts the loss curves for unseen schedules of different shapes and horizons. Moreover, by minimizing the predicted final pretraining loss across learning rate schedules, we are able to find a schedule that outperforms the widely used cosine learning rate schedule. Interestingly, this automatically discovered schedule bears some resemblance to the recently proposed Warmup-Stable-Decay (WSD) schedule (Hu et al, 2024) but achieves a slightly lower final loss. We believe these results could offer valuable insights for understanding the dynamics of pretraining and designing learning rate schedules to improve efficiency.
EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents
Jan 21, 2025



Multimodal Large Language Models (MLLMs) have shown significant advancements, providing a promising future for embodied agents. Existing benchmarks for evaluating MLLMs primarily utilize static images or videos, limiting assessments to non-interactive scenarios. Meanwhile, existing embodied AI benchmarks are task-specific and not diverse enough, which do not adequately evaluate the embodied capabilities of MLLMs. To address this, we propose EmbodiedEval, a comprehensive and interactive evaluation benchmark for MLLMs with embodied tasks. EmbodiedEval features 328 distinct tasks within 125 varied 3D scenes, each of which is rigorously selected and annotated. It covers a broad spectrum of existing embodied AI tasks with significantly enhanced diversity, all within a unified simulation and evaluation framework tailored for MLLMs. The tasks are organized into five categories: navigation, object interaction, social interaction, attribute question answering, and spatial question answering to assess different capabilities of the agents. We evaluated the state-of-the-art MLLMs on EmbodiedEval and found that they have a significant shortfall compared to human level on embodied tasks. Our analysis demonstrates the limitations of existing MLLMs in embodied capabilities, providing insights for their future development. We open-source all evaluation data and simulation framework at https://github.com/thunlp/EmbodiedEval.
ACDiT: Interpolating Autoregressive Conditional Modeling and Diffusion Transformer
Dec 10, 2024The recent surge of interest in comprehensive multimodal models has necessitated the unification of diverse modalities. However, the unification suffers from disparate methodologies. Continuous visual generation necessitates the full-sequence diffusion-based approach, despite its divergence from the autoregressive modeling in the text domain. We posit that autoregressive modeling, i.e., predicting the future based on past deterministic experience, remains crucial in developing both a visual generation model and a potential unified multimodal model. In this paper, we explore an interpolation between the autoregressive modeling and full-parameters diffusion to model visual information. At its core, we present ACDiT, an Autoregressive blockwise Conditional Diffusion Transformer, where the block size of diffusion, i.e., the size of autoregressive units, can be flexibly adjusted to interpolate between token-wise autoregression and full-sequence diffusion. ACDiT is easy to implement, as simple as creating a Skip-Causal Attention Mask (SCAM) during training. During inference, the process iterates between diffusion denoising and autoregressive decoding that can make full use of KV-Cache. We verify the effectiveness of ACDiT on image and video generation tasks. We also demonstrate that benefitted from autoregressive modeling, ACDiT can be seamlessly used in visual understanding tasks despite being trained on the diffusion objective. The analysis of the trade-off between autoregressive modeling and diffusion demonstrates the potential of ACDiT to be used in long-horizon visual generation tasks. These strengths make it promising as the backbone of future unified models.
Stuffed Mamba: State Collapse and State Capacity of RNN-Based Long-Context Modeling
Oct 09, 2024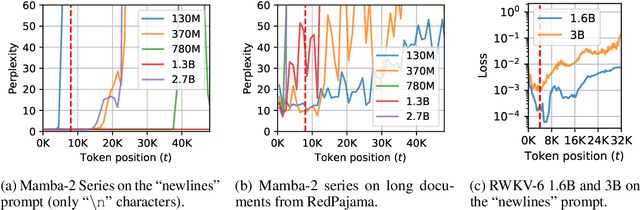
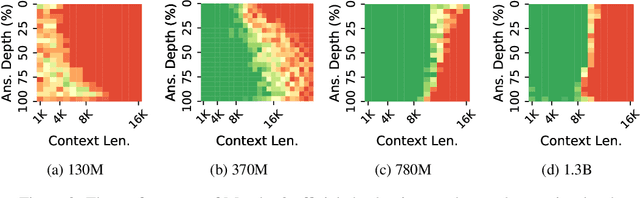
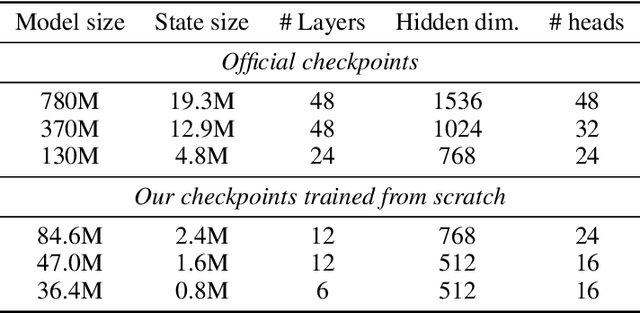
One essential advantage of recurrent neural networks (RNNs) over transformer-based language models is their linear computational complexity concerning the sequence length, which makes them much faster in handling long sequences during inference. However, most publicly available RNNs (e.g., Mamba and RWKV) are trained on sequences with less than 10K tokens, and their effectiveness in longer contexts remains largely unsatisfying so far. In this paper, we study the cause of the inability to process long context for RNNs and suggest critical mitigations. We examine two practical concerns when applying state-of-the-art RNNs to long contexts: (1) the inability to extrapolate to inputs longer than the training length and (2) the upper bound of memory capacity. Addressing the first concern, we first investigate *state collapse* (SC), a phenomenon that causes severe performance degradation on sequence lengths not encountered during training. With controlled experiments, we attribute this to overfitting due to the recurrent state being overparameterized for the training length. For the second concern, we train a series of Mamba-2 models on long documents to empirically estimate the recurrent state capacity in language modeling and passkey retrieval. Then, three SC mitigation methods are proposed to improve Mamba-2's length generalizability, allowing the model to process more than 1M tokens without SC. We also find that the recurrent state capacity in passkey retrieval scales exponentially to the state size, and we empirically train a Mamba-2 370M with near-perfect passkey retrieval accuracy on 256K context length. This suggests a promising future for RNN-based long-context modeling.
DecorateLM: Data Engineering through Corpus Rating, Tagging, and Editing with Language Models
Oct 08, 2024



The performance of Large Language Models (LLMs) is substantially influenced by the pretraining corpus, which consists of vast quantities of unsupervised data processed by the models. Despite its critical role in model performance, ensuring the quality of this data is challenging due to its sheer volume and the absence of sample-level quality annotations and enhancements. In this paper, we introduce DecorateLM, a data engineering method designed to refine the pretraining corpus through data rating, tagging and editing. Specifically, DecorateLM rates texts against quality criteria, tags texts with hierarchical labels, and edits texts into a more formalized format. Due to the massive size of the pretraining corpus, adopting an LLM for decorating the entire corpus is less efficient. Therefore, to balance performance with efficiency, we curate a meticulously annotated training corpus for DecorateLM using a large language model and distill data engineering expertise into a compact 1.2 billion parameter small language model (SLM). We then apply DecorateLM to enhance 100 billion tokens of the training corpus, selecting 45 billion tokens that exemplify high quality and diversity for the further training of another 1.2 billion parameter LLM. Our results demonstrate that employing such high-quality data can significantly boost model performance, showcasing a powerful approach to enhance the quality of the pretraining corpus.
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024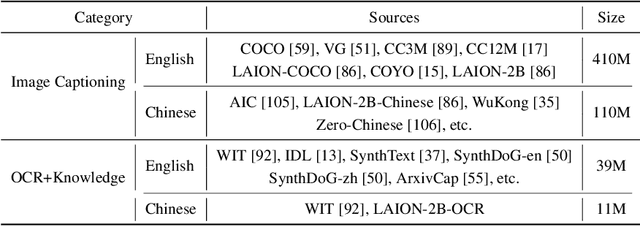

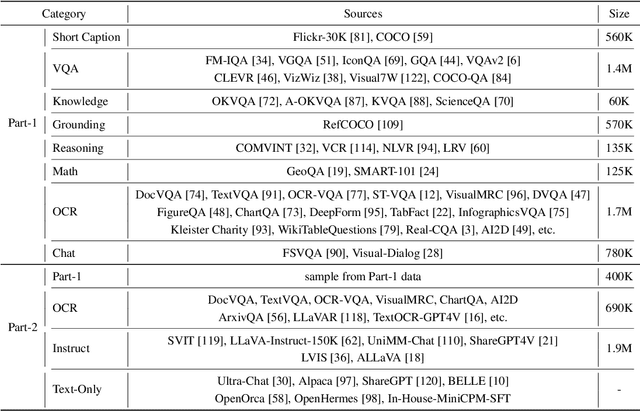
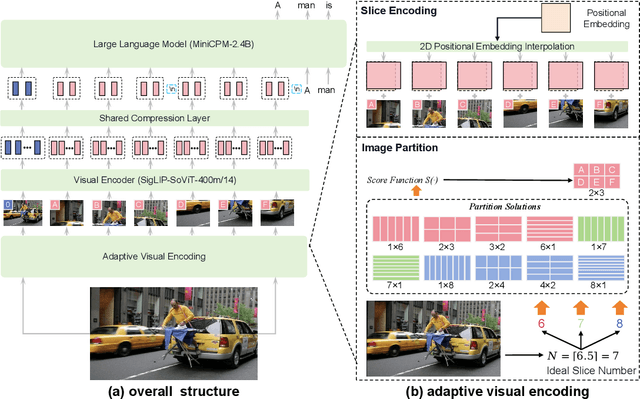
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
States Hidden in Hidden States: LLMs Emerge Discrete State Representations Implicitly
Jul 16, 2024



Large Language Models (LLMs) exhibit various emergent abilities. Among these abilities, some might reveal the internal working mechanisms of models. In this paper, we uncover a novel emergent capability in models: the intrinsic ability to perform extended sequences of calculations without relying on chain-of-thought step-by-step solutions. Remarkably, the most advanced models can directly output the results of two-digit number additions with lengths extending up to 15 addends. We hypothesize that the model emerges Implicit Discrete State Representations (IDSRs) within its hidden states and performs symbolic calculations internally. To test this hypothesis, we design a sequence of experiments that look into the hidden states. Specifically, we first confirm that IDSRs exist. Then, we provide interesting observations about the formation of IDSRs from layer, digit, and sequence perspectives. Finally, we confirm that models indeed use IDSRs to produce the final answers. However, we also discover that these state representations are far from lossless in current open-sourced models, leading to inaccuracies in their final performance. Our work presents a novel exploration of LLMs' symbolic calculation abilities and the underlying mechanisms.
Beyond the Turn-Based Game: Enabling Real-Time Conversations with Duplex Models
Jun 22, 2024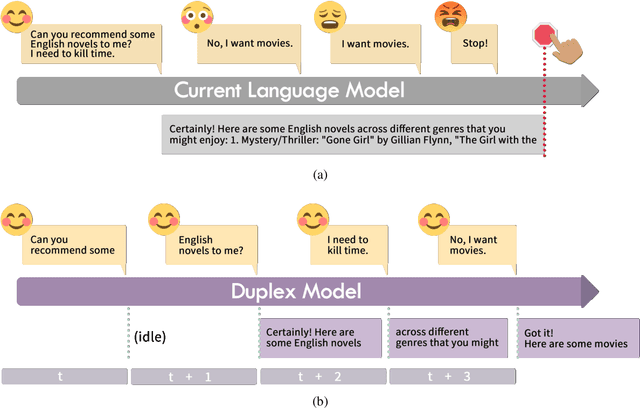
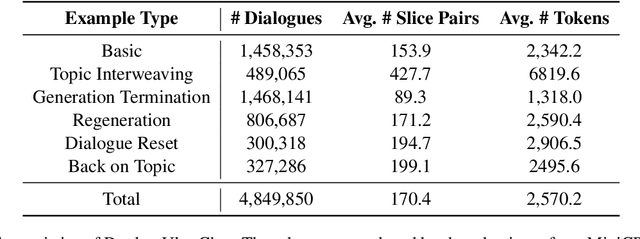

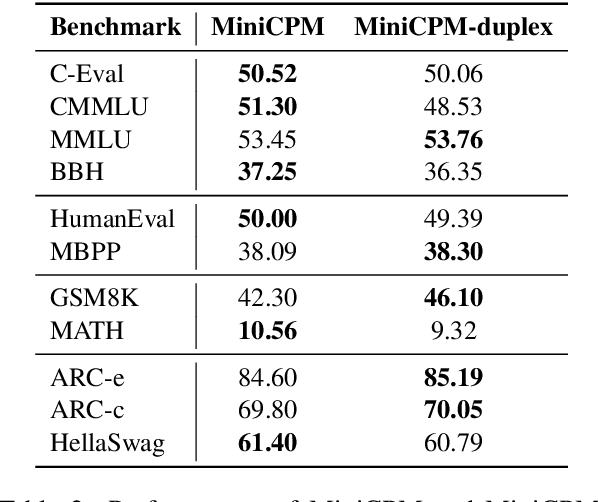
As large language models (LLMs) increasingly permeate daily lives, there is a growing demand for real-time interactions that mirror human conversations. Traditional turn-based chat systems driven by LLMs prevent users from verbally interacting with the system while it is generating responses. To overcome these limitations, we adapt existing LLMs to \textit{duplex models} so that these LLMs can listen for users while generating output and dynamically adjust themselves to provide users with instant feedback. % such as in response to interruptions. Specifically, we divide the queries and responses of conversations into several time slices and then adopt a time-division-multiplexing (TDM) encoding-decoding strategy to pseudo-simultaneously process these slices. Furthermore, to make LLMs proficient enough to handle real-time conversations, we build a fine-tuning dataset consisting of alternating time slices of queries and responses as well as covering typical feedback types in instantaneous interactions. Our experiments show that although the queries and responses of conversations are segmented into incomplete slices for processing, LLMs can preserve their original performance on standard benchmarks with a few fine-tuning steps on our dataset. Automatic and human evaluation indicate that duplex models make user-AI interactions more natural and human-like, and greatly improve user satisfaction compared to vanilla LLMs. Our duplex model and dataset will be released.
LEGENT: Open Platform for Embodied Agents
Apr 28, 2024
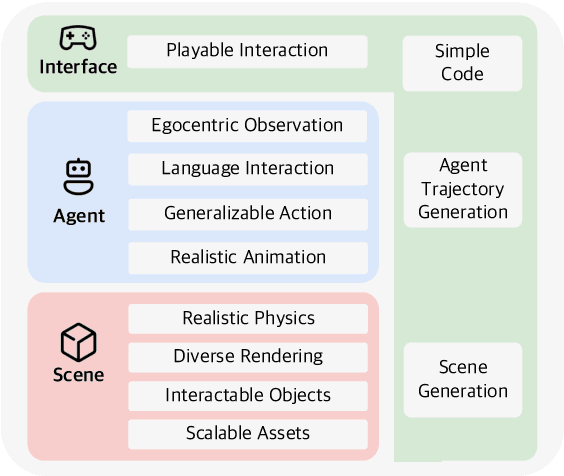


Despite advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), their integration into language-grounded, human-like embodied agents remains incomplete, hindering complex real-life task performance in physical environments. Existing integrations often feature limited open sourcing, challenging collective progress in this field. We introduce LEGENT, an open, scalable platform for developing embodied agents using LLMs and LMMs. LEGENT offers a dual approach: a rich, interactive 3D environment with communicable and actionable agents, paired with a user-friendly interface, and a sophisticated data generation pipeline utilizing advanced algorithms to exploit supervision from simulated worlds at scale. In our experiments, an embryonic vision-language-action model trained on LEGENT-generated data surpasses GPT-4V in embodied tasks, showcasing promising generalization capabilities.