 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECO: Sparse Mixture-of-Experts with Dense-Comparable Performance on End-Side Devices
May 11, 2026While Mixture-of-Experts (MoE) scales model capacity without proportionally increasing computation, its massive total parameter footprint creates significant storage and memory-access bottlenecks, which hinder efficient end-side deployment that simultaneously requires high performance, low computational cost, and small storage overhead. To achieve these properties, we present DECO, a sparse MoE architecture designed to match the performance of dense Transformers under identical total parameter budgets and training tokens. DECO utilizes the differentiable and flexible ReLU-based routing enhanced by learnable expert-wise scaling, which adaptively balances the contributions of routed and shared experts. Furthermore, we introduce NormSiLU, an activation function that normalizes inputs prior to SiLU operators, producing a more stable trend of routed-expert activation ratio and a higher intrinsic sparsity level. We also identify an empirical advantage in using non-gated MLP experts with ReLU-based routing, indicating the possibility of MoE architecture simplification. Experiments demonstrate that DECO, activating only 20% of experts, matches dense performance and outperforms established MoE baselines. Our specialized acceleration kernel delivers a 3.00$\times$ speedup on real hardware compared with dense inference. Codes and checkpoints will be released.
Student-in-the-Loop Chain-of-Thought Distillation via Generation-Time Selection
Apr 03, 2026Large reasoning models achieve strong performance on complex tasks through long chain-of-thought (CoT) trajectories, but directly transferring such reasoning processes to smaller models remains challenging. A key difficulty is that not all teacher-generated reasoning trajectories are suitable for student learning. Existing approaches typically rely on post-hoc filtering, selecting trajectories after full generation based on heuristic criteria. However, such methods cannot control the generation process itself and may still produce reasoning paths that lie outside the student's learning capacity. To address this limitation, we propose Gen-SSD (Generation-time Self-Selection Distillation), a student-in-the-loop framework that performs generation-time selection. Instead of passively consuming complete trajectories, the student evaluates candidate continuations during the teacher's sampling process, guiding the expansion of only learnable reasoning paths and enabling early pruning of unhelpful branches. Experiments on mathematical reasoning benchmarks demonstrate that Gen-SSD consistently outperforms standard knowledge distillation and recent baselines, with improvements of around 5.9 points over Standard KD and up to 4.7 points over other baselines. Further analysis shows that Gen-SSD produces more stable and learnable reasoning trajectories, highlighting the importance of incorporating supervision during generation for effective distillation.
MiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
Feb 12, 2026The evolution of large language models (LLMs) towards applications with ultra-long contexts faces challenges posed by the high computational and memory costs of the Transformer architecture. While existing sparse and linear attention mechanisms attempt to mitigate these issues, they typically involve a trade-off between memory efficiency and model performance. This paper introduces MiniCPM-SALA, a 9B-parameter hybrid architecture that integrates the high-fidelity long-context modeling of sparse attention (InfLLM-V2) with the global efficiency of linear attention (Lightning Attention). By employing a layer selection algorithm to integrate these mechanisms in a 1:3 ratio and utilizing a hybrid positional encoding (HyPE), the model maintains efficiency and performance for long-context tasks. Furthermore, we introduce a cost-effective continual training framework that transforms pre-trained Transformer-based models into hybrid models, which reduces training costs by approximately 75% compared to training from scratch. Extensive experiments show that MiniCPM-SALA maintains general capabilities comparable to full-attention models while offering improved efficiency. On a single NVIDIA A6000D GPU, the model achieves up to 3.5x the inference speed of the full-attention model at the sequence length of 256K tokens and supports context lengths of up to 1M tokens, a scale where traditional full-attention 8B models fail because of memory constraints.
Hybrid Linear Attention Done Right: Efficient Distillation and Effective Architectures for Extremely Long Contexts
Jan 29, 2026Hybrid Transformer architectures, which combine softmax attention blocks and recurrent neural networks (RNNs), have shown a desirable performance-throughput tradeoff for long-context modeling, but their adoption and studies are hindered by the prohibitive cost of large-scale pre-training from scratch. Some recent studies have shown that pre-trained softmax attention blocks can be converted into RNN blocks through parameter transfer and knowledge distillation. However, these transfer methods require substantial amounts of training data (more than 10B tokens), and the resulting hybrid models also exhibit poor long-context performance, which is the scenario where hybrid models enjoy significant inference speedups over Transformer-based models. In this paper, we present HALO (Hybrid Attention via Layer Optimization), a pipeline for distilling Transformer models into RNN-attention hybrid models. We then present HypeNet, a hybrid architecture with superior length generalization enabled by a novel position encoding scheme (named HyPE) and various architectural modifications. We convert the Qwen3 series into HypeNet using HALO, achieving performance comparable to the original Transformer models while enjoying superior long-context performance and efficiency. The conversion requires just 2.3B tokens, less than 0.01% of their pre-training data
StateX: Enhancing RNN Recall via Post-training State Expansion
Sep 26, 2025While Transformer-based models have demonstrated remarkable language modeling performance, their high complexities result in high costs when processing long contexts. In contrast, recurrent neural networks (RNNs) such as linear attention and state space models have gained popularity due to their constant per-token complexities. However, these recurrent models struggle with tasks that require accurate recall of contextual information from long contexts, because all contextual information is compressed into a constant-size recurrent state. Previous works have shown that recall ability is positively correlated with the recurrent state size, yet directly training RNNs with larger recurrent states results in high training costs. In this paper, we introduce StateX, a training pipeline for efficiently expanding the states of pre-trained RNNs through post-training. For two popular classes of RNNs, linear attention and state space models, we design post-training architectural modifications to scale up the state size with no or negligible increase in model parameters. Experiments on models up to 1.3B parameters demonstrate that StateX efficiently enhances the recall and in-context learning ability of RNNs without incurring high post-training costs or compromising other capabilities.
Cost-Optimal Grouped-Query Attention for Long-Context LLMs
Mar 12, 2025Building effective and efficient Transformer-based large language models (LLMs) has recently become a research focus, requiring maximizing model language capabilities and minimizing training and deployment costs. Existing efforts have primarily described complex relationships among model performance, parameter size, and data size, as well as searched for the optimal compute allocation to train LLMs. However, they overlook the impacts of context length and attention head configuration (the number of query and key-value heads in grouped-query attention) on training and inference. In this paper, we systematically compare models with different parameter sizes, context lengths, and attention head configurations in terms of model performance, computational cost, and memory cost. Then, we extend the existing scaling methods, which are based solely on parameter size and training compute, to guide the construction of cost-optimal LLMs during both training and inference. Our quantitative scaling studies show that, when processing sufficiently long sequences, a larger model with fewer attention heads can achieve a lower loss while incurring lower computational and memory costs. Our findings provide valuable insights for developing practical LLMs, especially in long-context processing scenarios. We will publicly release our code and data.
Sparsing Law: Towards Large Language Models with Greater Activation Sparsity
Nov 04, 2024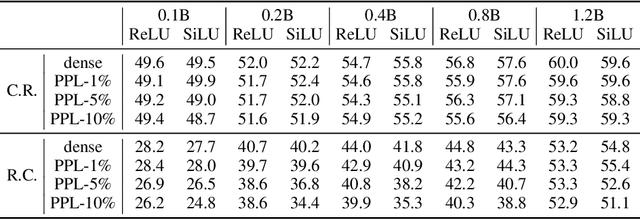
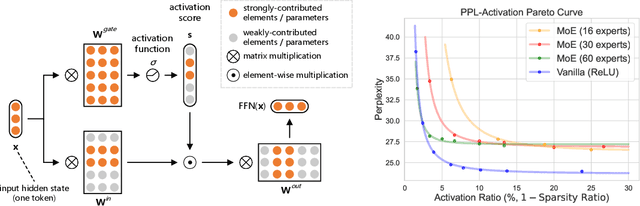

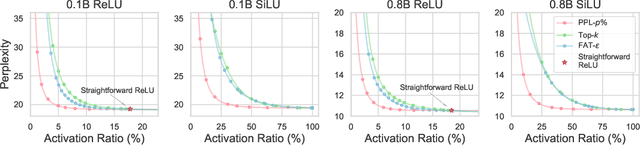
Activation sparsity denotes the existence of substantial weakly-contributed elements within activation outputs that can be eliminated, benefiting many important applications concerned with large language models (LLMs). Although promoting greater activation sparsity within LLMs deserves deep studies, existing works lack comprehensive and quantitative research on the correlation between activation sparsity and potentially influential factors. In this paper, we present a comprehensive study on the quantitative scaling properties and influential factors of the activation sparsity within decoder-only Transformer-based LLMs. Specifically, we propose PPL-$p\%$ sparsity, a precise and performance-aware activation sparsity metric that is applicable to any activation function. Through extensive experiments, we find several important phenomena. Firstly, different activation functions exhibit comparable performance but opposite training-time sparsity trends. The activation ratio (i.e., $1-\mathrm{sparsity\ ratio}$) evolves as a convergent increasing power-law and decreasing logspace power-law with the amount of training data for SiLU-activated and ReLU-activated LLMs, respectively. These demonstrate that ReLU is more efficient as the activation function than SiLU and can leverage more training data to improve activation sparsity. Secondly, the activation ratio linearly increases with the width-depth ratio below a certain bottleneck point, indicating the potential advantage of a deeper architecture at a fixed parameter scale. Finally, at similar width-depth ratios, we surprisingly find that the limit value of activation sparsity varies weakly with the parameter scale, i.e., the activation patterns within LLMs are insensitive to the parameter scale. These empirical laws towards LLMs with greater activation sparsity have important implications for making LLMs more efficient and interpretable.
Stuffed Mamba: State Collapse and State Capacity of RNN-Based Long-Context Modeling
Oct 09, 2024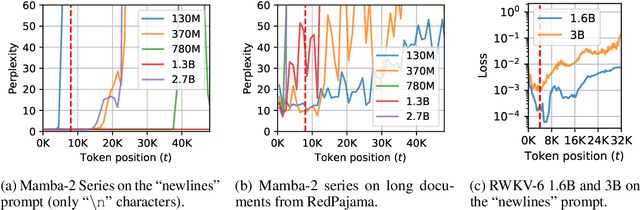
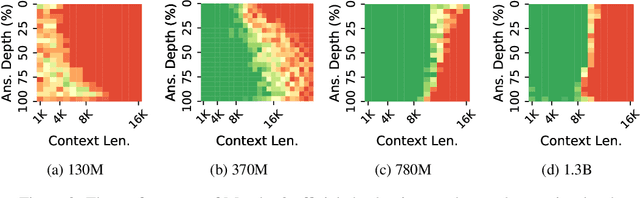
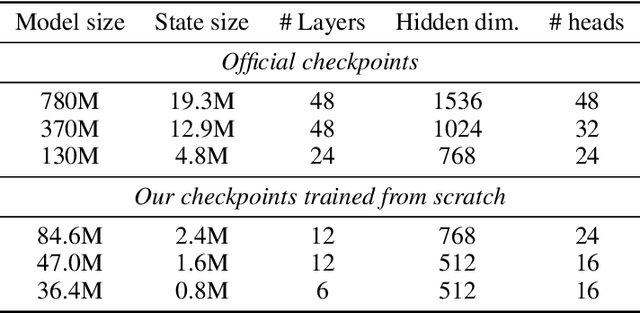
One essential advantage of recurrent neural networks (RNNs) over transformer-based language models is their linear computational complexity concerning the sequence length, which makes them much faster in handling long sequences during inference. However, most publicly available RNNs (e.g., Mamba and RWKV) are trained on sequences with less than 10K tokens, and their effectiveness in longer contexts remains largely unsatisfying so far. In this paper, we study the cause of the inability to process long context for RNNs and suggest critical mitigations. We examine two practical concerns when applying state-of-the-art RNNs to long contexts: (1) the inability to extrapolate to inputs longer than the training length and (2) the upper bound of memory capacity. Addressing the first concern, we first investigate *state collapse* (SC), a phenomenon that causes severe performance degradation on sequence lengths not encountered during training. With controlled experiments, we attribute this to overfitting due to the recurrent state being overparameterized for the training length. For the second concern, we train a series of Mamba-2 models on long documents to empirically estimate the recurrent state capacity in language modeling and passkey retrieval. Then, three SC mitigation methods are proposed to improve Mamba-2's length generalizability, allowing the model to process more than 1M tokens without SC. We also find that the recurrent state capacity in passkey retrieval scales exponentially to the state size, and we empirically train a Mamba-2 370M with near-perfect passkey retrieval accuracy on 256K context length. This suggests a promising future for RNN-based long-context modeling.
Configurable Foundation Models: Building LLMs from a Modular Perspective
Sep 04, 2024



Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.
Multi-Modal Multi-Granularity Tokenizer for Chu Bamboo Slip Scripts
Sep 02, 2024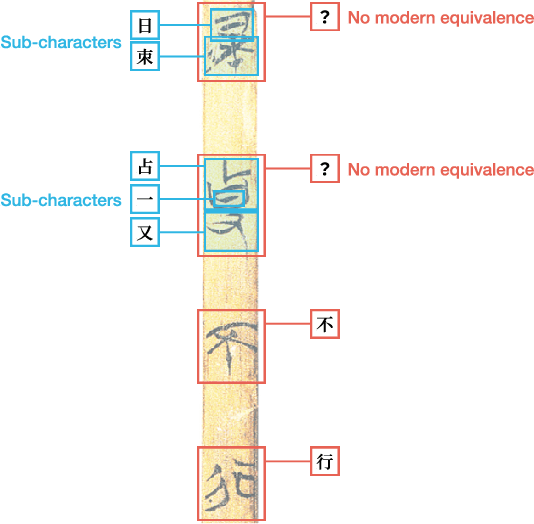
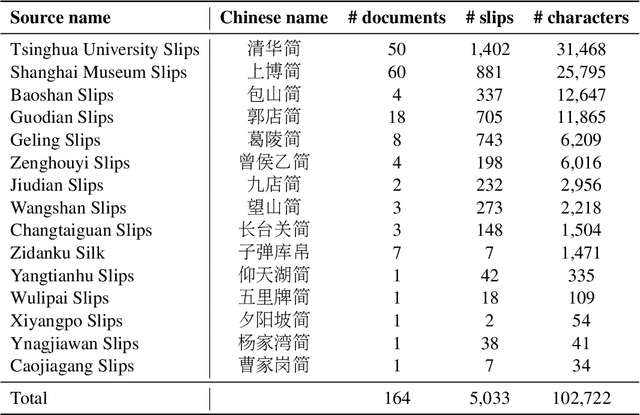
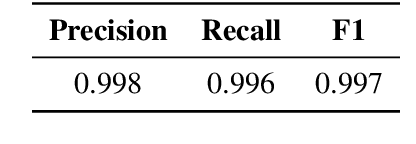
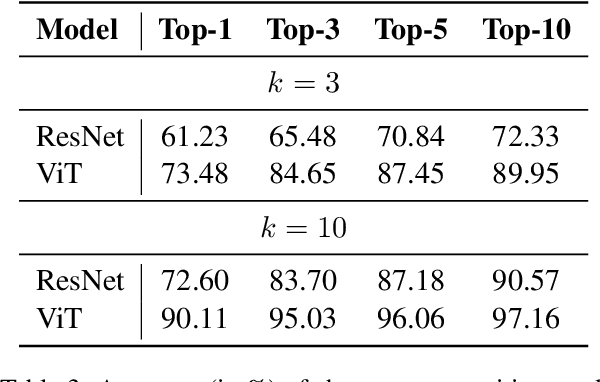
This study presents a multi-modal multi-granularity tokenizer specifically designed for analyzing ancient Chinese scripts, focusing on the Chu bamboo slip (CBS) script used during the Spring and Autumn and Warring States period (771-256 BCE) in Ancient China. Considering the complex hierarchical structure of ancient Chinese scripts, where a single character may be a combination of multiple sub-characters, our tokenizer first adopts character detection to locate character boundaries, and then conducts character recognition at both the character and sub-character levels. Moreover, to support the academic community, we have also assembled the first large-scale dataset of CBSs with over 100K annotated character image scans. On the part-of-speech tagging task built on our dataset, using our tokenizer gives a 5.5% relative improvement in F1-score compared to mainstream sub-word tokenizers. Our work not only aids in further investigations of the specific script but also has the potential to advance research on other forms of ancient Chinese scripts.