 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Scalable Model Editing for Large Language Models
Mar 26, 2024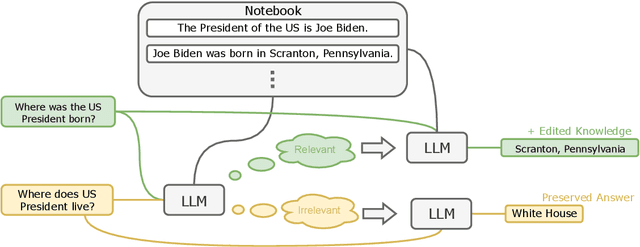


Large language models (LLMs) can make predictions using parametric knowledge--knowledge encoded in the model weights--or contextual knowledge--knowledge presented in the context. In many scenarios, a desirable behavior is that LLMs give precedence to contextual knowledge when it conflicts with the parametric knowledge, and fall back to using their parametric knowledge when the context is irrelevant. This enables updating and correcting the model's knowledge by in-context editing instead of retraining. Previous works have shown that LLMs are inclined to ignore contextual knowledge and fail to reliably fall back to parametric knowledge when presented with irrelevant context. In this work, we discover that, with proper prompting methods, instruction-finetuned LLMs can be highly controllable by contextual knowledge and robust to irrelevant context. Utilizing this feature, we propose EREN (Edit models by REading Notes) to improve the scalability and robustness of LLM editing. To better evaluate the robustness of model editors, we collect a new dataset, that contains irrelevant questions that are more challenging than the ones in existing datasets. Empirical results show that our method outperforms current state-of-the-art methods by a large margin. Unlike existing techniques, it can integrate knowledge from multiple edits, and correctly respond to syntactically similar but semantically unrelated inputs (and vice versa). The source code can be found at https://github.com/thunlp/EREN.
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models
Feb 27, 2024Activation sparsity refers to the existence of considerable weakly-contributed elements among activation outputs. As a prevalent property of the models using the ReLU activation function, it has been proven a promising paradigm to boost model inference efficiency. Nevertheless, most large language models (LLMs) adopt activation functions without intrinsic activation sparsity (e.g., GELU and Swish). Some recent efforts have explored introducing ReLU or its variants as the substitutive activation function to help LLMs achieve activation sparsity and inference acceleration, but few can simultaneously obtain high sparsity and comparable model performance. This paper introduces an effective sparsification method named "ProSparse" to push LLMs for higher activation sparsity without decreasing model performance. Specifically, after substituting the activation function of LLMs with ReLU, ProSparse adopts progressive sparsity regularization with a factor smoothly increasing along sine curves in multiple stages. This can enhance activation sparsity and alleviate performance degradation by avoiding radical shifts in activation distribution. With ProSparse, we obtain high sparsity of 89.32% and 88.80% for LLaMA2-7B and LLaMA2-13B, respectively, achieving comparable performance to their original Swish-activated versions. Our inference acceleration experiments further demonstrate the practical acceleration brought by higher activation sparsity.
ConPET: Continual Parameter-Efficient Tuning for Large Language Models
Sep 26, 2023Continual learning necessitates the continual adaptation of models to newly emerging tasks while minimizing the catastrophic forgetting of old ones. This is extremely challenging for large language models (LLMs) with vanilla full-parameter tuning due to high computation costs, memory consumption, and forgetting issue. Inspired by the success of parameter-efficient tuning (PET), we propose Continual Parameter-Efficient Tuning (ConPET), a generalizable paradigm for continual task adaptation of LLMs with task-number-independent training complexity. ConPET includes two versions with different application scenarios. First, Static ConPET can adapt former continual learning methods originally designed for relatively smaller models to LLMs through PET and a dynamic replay strategy, which largely reduces the tuning costs and alleviates the over-fitting and forgetting issue. Furthermore, to maintain scalability, Dynamic ConPET adopts separate PET modules for different tasks and a PET module selector for dynamic optimal selection. In our extensive experiments, the adaptation of Static ConPET helps multiple former methods reduce the scale of tunable parameters by over 3,000 times and surpass the PET-only baseline by at least 5 points on five smaller benchmarks, while Dynamic ConPET gains its advantage on the largest dataset. The codes and datasets are available at https://github.com/Raincleared-Song/ConPET.