 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024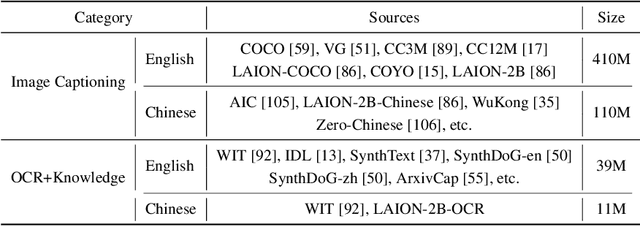

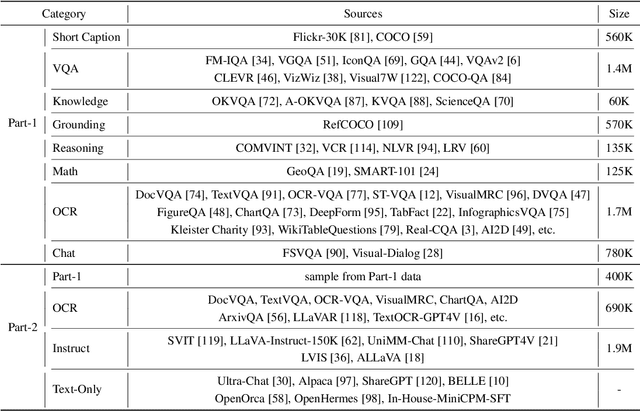
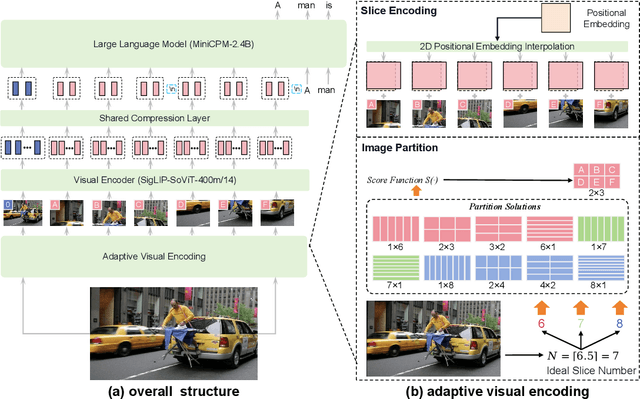
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
Discovering Sounding Objects by Audio Queries for Audio Visual Segmentation
Sep 18, 2023



Audio visual segmentation (AVS) aims to segment the sounding objects for each frame of a given video. To distinguish the sounding objects from silent ones, both audio-visual semantic correspondence and temporal interaction are required. The previous method applies multi-frame cross-modal attention to conduct pixel-level interactions between audio features and visual features of multiple frames simultaneously, which is both redundant and implicit. In this paper, we propose an Audio-Queried Transformer architecture, AQFormer, where we define a set of object queries conditioned on audio information and associate each of them to particular sounding objects. Explicit object-level semantic correspondence between audio and visual modalities is established by gathering object information from visual features with predefined audio queries. Besides, an Audio-Bridged Temporal Interaction module is proposed to exchange sounding object-relevant information among multiple frames with the bridge of audio features. Extensive experiments are conducted on two AVS benchmarks to show that our method achieves state-of-the-art performances, especially 7.1% M_J and 7.6% M_F gains on the MS3 setting.