 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Apr 14, 2026On-policy distillation (OPD) has become a core technique in the post-training of large language models, yet its training dynamics remain poorly understood. This paper provides a systematic investigation of OPD dynamics and mechanisms. We first identify that two conditions govern whether OPD succeeds or fails: (i) the student and teacher should share compatible thinking patterns; and (ii) even with consistent thinking patterns and higher scores, the teacher must offer genuinely new capabilities beyond what the student has seen during training. We validate these findings through weak-to-strong reverse distillation, showing that same-family 1.5B and 7B teachers are distributionally indistinguishable from the student's perspective. Probing into the token-level mechanism, we show that successful OPD is characterized by progressive alignment on high-probability tokens at student-visited states, a small shared token set that concentrates most of the probability mass (97%-99%). We further propose two practical strategies to recover failing OPD: off-policy cold start and teacher-aligned prompt selection. Finally, we show that OPD's apparent free lunch of dense token-level reward comes at a cost, raising the question of whether OPD can scale to long-horizon distillation.
The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models
Jan 21, 2026Diffusion Large Language Models (dLLMs) break the rigid left-to-right constraint of traditional LLMs, enabling token generation in arbitrary orders. Intuitively, this flexibility implies a solution space that strictly supersets the fixed autoregressive trajectory, theoretically unlocking superior reasoning potential for general tasks like mathematics and coding. Consequently, numerous works have leveraged reinforcement learning (RL) to elicit the reasoning capability of dLLMs. In this paper, we reveal a counter-intuitive reality: arbitrary order generation, in its current form, narrows rather than expands the reasoning boundary of dLLMs. We find that dLLMs tend to exploit this order flexibility to bypass high-uncertainty tokens that are crucial for exploration, leading to a premature collapse of the solution space. This observation challenges the premise of existing RL approaches for dLLMs, where considerable complexities, such as handling combinatorial trajectories and intractable likelihoods, are often devoted to preserving this flexibility. We demonstrate that effective reasoning is better elicited by intentionally forgoing arbitrary order and applying standard Group Relative Policy Optimization (GRPO) instead. Our approach, JustGRPO, is minimalist yet surprisingly effective (e.g., 89.1% accuracy on GSM8K) while fully retaining the parallel decoding ability of dLLMs. Project page: https://nzl-thu.github.io/the-flexibility-trap
Thinking with Blueprints: Assisting Vision-Language Models in Spatial Reasoning via Structured Object Representation
Jan 05, 2026Spatial reasoning -- the ability to perceive and reason about relationships in space -- advances vision-language models (VLMs) from visual perception toward spatial semantic understanding. Existing approaches either revisit local image patches, improving fine-grained perception but weakening global spatial awareness, or mark isolated coordinates, which capture object locations but overlook their overall organization. In this work, we integrate the cognitive concept of an object-centric blueprint into VLMs to enhance spatial reasoning. Given an image and a question, the model first constructs a JSON-style blueprint that records the positions, sizes, and attributes of relevant objects, and then reasons over this structured representation to produce the final answer. To achieve this, we introduce three key techniques: (1) blueprint-embedded reasoning traces for supervised fine-tuning to elicit basic reasoning skills; (2) blueprint-aware rewards in reinforcement learning to encourage the blueprint to include an appropriate number of objects and to align final answers with this causal reasoning; and (3) anti-shortcut data augmentation that applies targeted perturbations to images and questions, discouraging reliance on superficial visual or linguistic cues. Experiments show that our method consistently outperforms existing VLMs and specialized spatial reasoning models.
Process Reinforcement through Implicit Rewards
Feb 03, 2025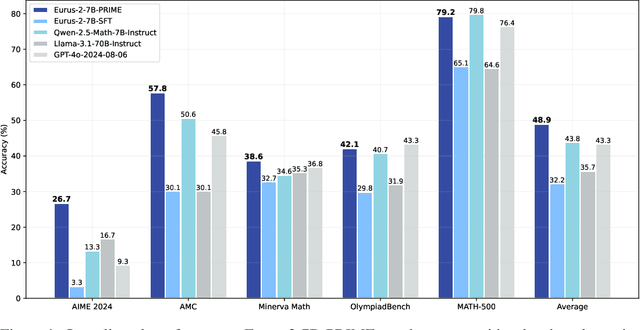

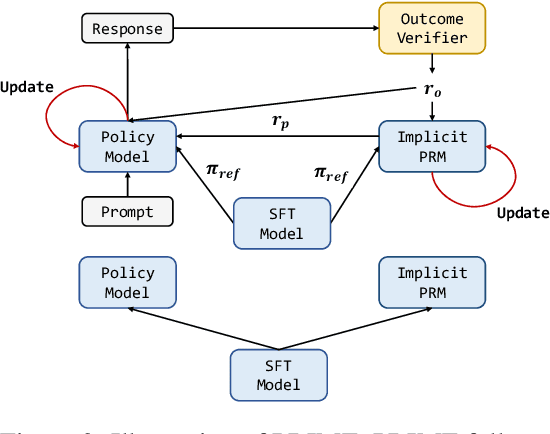
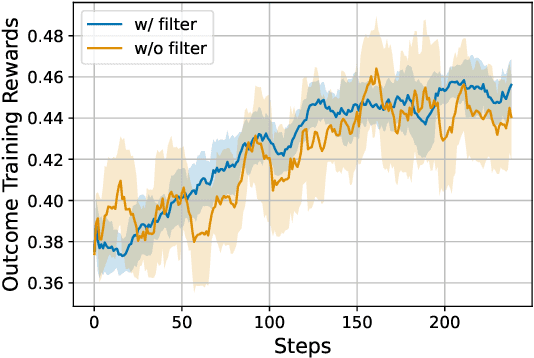
Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents
Jan 21, 2025



Multimodal Large Language Models (MLLMs) have shown significant advancements, providing a promising future for embodied agents. Existing benchmarks for evaluating MLLMs primarily utilize static images or videos, limiting assessments to non-interactive scenarios. Meanwhile, existing embodied AI benchmarks are task-specific and not diverse enough, which do not adequately evaluate the embodied capabilities of MLLMs. To address this, we propose EmbodiedEval, a comprehensive and interactive evaluation benchmark for MLLMs with embodied tasks. EmbodiedEval features 328 distinct tasks within 125 varied 3D scenes, each of which is rigorously selected and annotated. It covers a broad spectrum of existing embodied AI tasks with significantly enhanced diversity, all within a unified simulation and evaluation framework tailored for MLLMs. The tasks are organized into five categories: navigation, object interaction, social interaction, attribute question answering, and spatial question answering to assess different capabilities of the agents. We evaluated the state-of-the-art MLLMs on EmbodiedEval and found that they have a significant shortfall compared to human level on embodied tasks. Our analysis demonstrates the limitations of existing MLLMs in embodied capabilities, providing insights for their future development. We open-source all evaluation data and simulation framework at https://github.com/thunlp/EmbodiedEval.
Euclid: Supercharging Multimodal LLMs with Synthetic High-Fidelity Visual Descriptions
Dec 11, 2024Multimodal large language models (MLLMs) have made rapid progress in recent years, yet continue to struggle with low-level visual perception (LLVP) -- particularly the ability to accurately describe the geometric details of an image. This capability is crucial for applications in areas such as robotics, medical image analysis, and manufacturing. In this paper, we first introduce Geoperception, a benchmark designed to evaluate an MLLM's ability to accurately transcribe 2D geometric information from an image. Using this benchmark, we demonstrate the limitations of leading MLLMs, and then conduct a comprehensive empirical study to explore strategies for improving their performance on geometric tasks. Our findings highlight the benefits of certain model architectures, training techniques, and data strategies, including the use of high-fidelity synthetic data and multi-stage training with a data curriculum. Notably, we find that a data curriculum enables models to learn challenging geometry understanding tasks which they fail to learn from scratch. Leveraging these insights, we develop Euclid, a family of models specifically optimized for strong low-level geometric perception. Although purely trained on synthetic multimodal data, Euclid shows strong generalization ability to novel geometry shapes. For instance, Euclid outperforms the best closed-source model, Gemini-1.5-Pro, by up to 58.56% on certain Geoperception benchmark tasks and 10.65% on average across all tasks.
A Topic-level Self-Correctional Approach to Mitigate Hallucinations in MLLMs
Nov 26, 2024



Aligning the behaviors of Multimodal Large Language Models (MLLMs) with human preferences is crucial for developing robust and trustworthy AI systems. While recent attempts have employed human experts or powerful auxiliary AI systems to provide more accurate preference feedback, such as determining the preferable responses from MLLMs or directly rewriting hallucination-free responses, extensive resource overhead compromise the scalability of the feedback collection. In this work, we introduce Topic-level Preference Overwriting (TPO), a self-correctional approach that guide the model itself to mitigate its own hallucination at the topic level. Through a deconfounded strategy that replaces each topic within the response with the best or worst alternatives generated by the model itself, TPO creates more contrasting pairwise preference feedback, enhancing the feedback quality without human or proprietary model intervention. Notably, the experimental results demonstrate proposed TPO achieves state-of-the-art performance in trustworthiness, significantly reducing the object hallucinations by 92% and overall hallucinations by 38%. Code, model and data will be released.
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024

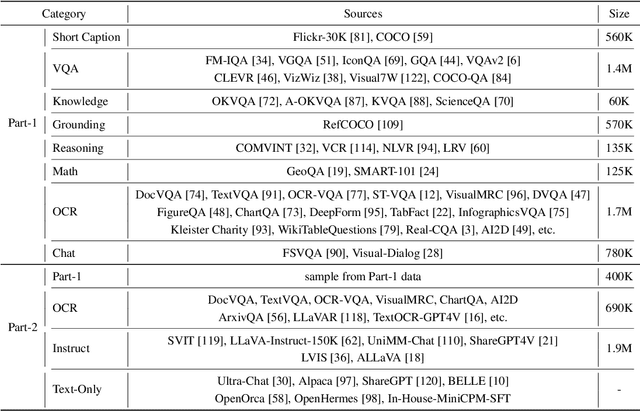
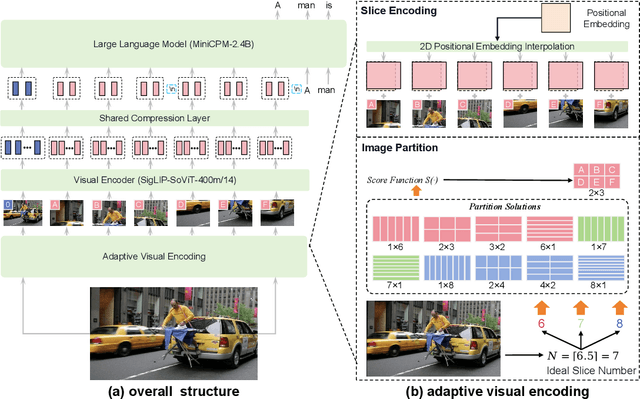
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness
May 27, 2024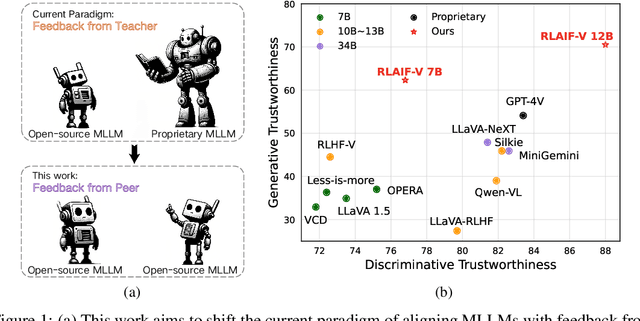
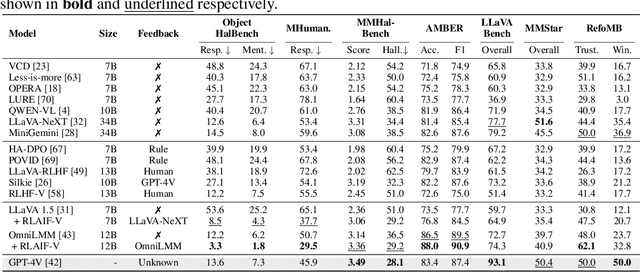
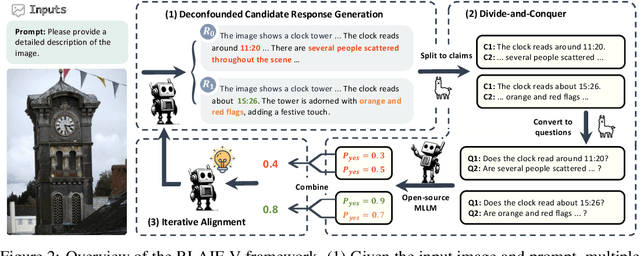
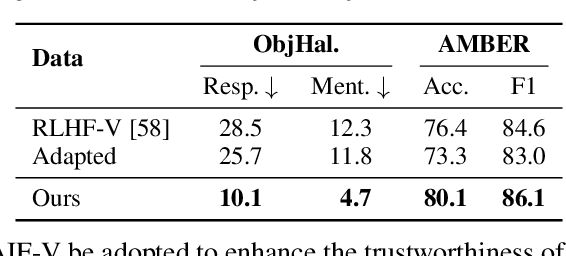
Learning from feedback reduces the hallucination of multimodal large language models (MLLMs) by aligning them with human preferences. While traditional methods rely on labor-intensive and time-consuming manual labeling, recent approaches employing models as automatic labelers have shown promising results without human intervention. However, these methods heavily rely on costly proprietary models like GPT-4V, resulting in scalability issues. Moreover, this paradigm essentially distills the proprietary models to provide a temporary solution to quickly bridge the performance gap. As this gap continues to shrink, the community is soon facing the essential challenge of aligning MLLMs using labeler models of comparable capability. In this work, we introduce RLAIF-V, a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. RLAIF-V maximally exploits the open-source feedback from two perspectives, including high-quality feedback data and online feedback learning algorithm. Extensive experiments on seven benchmarks in both automatic and human evaluation show that RLAIF-V substantially enhances the trustworthiness of models without sacrificing performance on other tasks. Using a 34B model as labeler, RLAIF-V 7B model reduces object hallucination by 82.9\% and overall hallucination by 42.1\%, outperforming the labeler model. Remarkably, RLAIF-V also reveals the self-alignment potential of open-source MLLMs, where a 12B model can learn from the feedback of itself to achieve less than 29.5\% overall hallucination rate, surpassing GPT-4V (45.9\%) by a large margin. The results shed light on a promising route to enhance the efficacy of leading-edge MLLMs.
UltraWiki: Ultra-fine-grained Entity Set Expansion with Negative Seed Entities
Mar 07, 2024



Entity Set Expansion (ESE) aims to identify new entities belonging to the same semantic class as a given set of seed entities. Traditional methods primarily relied on positive seed entities to represent a target semantic class, which poses challenge for the representation of ultra-fine-grained semantic classes. Ultra-fine-grained semantic classes are defined based on fine-grained semantic classes with more specific attribute constraints. Describing it with positive seed entities alone cause two issues: (i) Ambiguity among ultra-fine-grained semantic classes. (ii) Inability to define "unwanted" semantic. Due to these inherent shortcomings, previous methods struggle to address the ultra-fine-grained ESE (Ultra-ESE). To solve this issue, we first introduce negative seed entities in the inputs, which belong to the same fine-grained semantic class as the positive seed entities but differ in certain attributes. Negative seed entities eliminate the semantic ambiguity by contrast between positive and negative attributes. Meanwhile, it provide a straightforward way to express "unwanted". To assess model performance in Ultra-ESE, we constructed UltraWiki, the first large-scale dataset tailored for Ultra-ESE. UltraWiki encompasses 236 ultra-fine-grained semantic classes, where each query of them is represented with 3-5 positive and negative seed entities. A retrieval-based framework RetExpan and a generation-based framework GenExpan are proposed to comprehensively assess the efficacy of large language models from two different paradigms in Ultra-ESE. Moreover, we devised three strategies to enhance models' comprehension of ultra-fine-grained entities semantics: contrastive learning, retrieval augmentation, and chain-of-thought reasoning. Extensive experiments confirm the effectiveness of our proposed strategies and also reveal that there remains a large space for improvement in Ultra-ESE.