 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
Feb 12, 2026The evolution of large language models (LLMs) towards applications with ultra-long contexts faces challenges posed by the high computational and memory costs of the Transformer architecture. While existing sparse and linear attention mechanisms attempt to mitigate these issues, they typically involve a trade-off between memory efficiency and model performance. This paper introduces MiniCPM-SALA, a 9B-parameter hybrid architecture that integrates the high-fidelity long-context modeling of sparse attention (InfLLM-V2) with the global efficiency of linear attention (Lightning Attention). By employing a layer selection algorithm to integrate these mechanisms in a 1:3 ratio and utilizing a hybrid positional encoding (HyPE), the model maintains efficiency and performance for long-context tasks. Furthermore, we introduce a cost-effective continual training framework that transforms pre-trained Transformer-based models into hybrid models, which reduces training costs by approximately 75% compared to training from scratch. Extensive experiments show that MiniCPM-SALA maintains general capabilities comparable to full-attention models while offering improved efficiency. On a single NVIDIA A6000D GPU, the model achieves up to 3.5x the inference speed of the full-attention model at the sequence length of 256K tokens and supports context lengths of up to 1M tokens, a scale where traditional full-attention 8B models fail because of memory constraints.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
PyBench: Evaluating LLM Agent on various real-world coding tasks
Jul 23, 2024



The LLM Agent, equipped with a code interpreter, is capable of automatically solving real-world coding tasks, such as data analysis and image editing. However, existing benchmarks primarily focus on either simplistic tasks, such as completing a few lines of code, or on extremely complex and specific tasks at the repository level, neither of which are representative of various daily coding tasks. To address this gap, we introduce \textbf{PyBench}, a benchmark encompassing five main categories of real-world tasks, covering more than 10 types of files. Given a high-level user query and related files, the LLM Agent needs to reason and execute Python code via a code interpreter for a few turns before making a formal response to fulfill the user's requirements. Successfully addressing tasks in PyBench demands a robust understanding of various Python packages, superior reasoning capabilities, and the ability to incorporate feedback from executed code. Our evaluations indicate that current open-source LLMs are struggling with these tasks. Hence, we conduct analysis and experiments on four kinds of datasets proving that comprehensive abilities are needed for PyBench. Our fine-tuned 8B size model: \textbf{PyLlama3} achieves an exciting performance on PyBench which surpasses many 33B and 70B size models. Our Benchmark, Training Dataset, and Model are available at: \href{https://github.com/Mercury7353/PyBench}{https://github.com/Mercury7353/PyBench}
DebugBench: Evaluating Debugging Capability of Large Language Models
Jan 11, 2024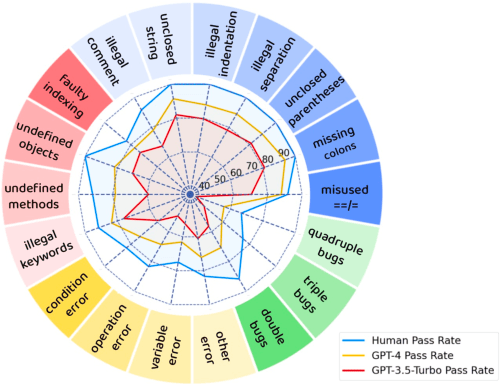

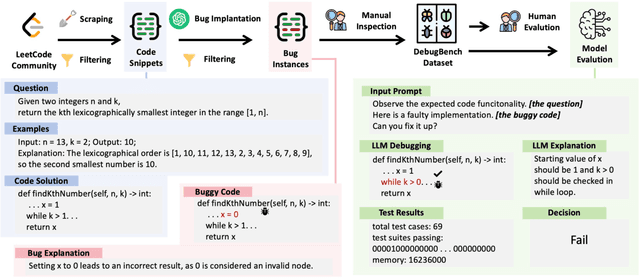

Large Language Models (LLMs) have demonstrated exceptional coding capability. However, as another critical component of programming proficiency, the debugging capability of LLMs remains relatively unexplored. Previous evaluations of LLMs' debugging ability are significantly limited by the risk of data leakage, the scale of the dataset, and the variety of tested bugs. To overcome these deficiencies, we introduce `DebugBench', an LLM debugging benchmark consisting of 4,253 instances. It covers four major bug categories and 18 minor types in C++, Java, and Python. To construct DebugBench, we collect code snippets from the LeetCode community, implant bugs into source data with GPT-4, and assure rigorous quality checks. We evaluate two commercial and three open-source models in a zero-shot scenario. We find that (1) while closed-source models like GPT-4 exhibit inferior debugging performance compared to humans, open-source models such as Code Llama fail to attain any pass rate scores; (2) the complexity of debugging notably fluctuates depending on the bug category; (3) incorporating runtime feedback has a clear impact on debugging performance which is not always helpful. As an extension, we also compare LLM debugging and code generation, revealing a strong correlation between them for closed-source models. These findings will benefit the development of LLMs in debugging.
Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
Aug 23, 2023



Recently there has been a significant surge in multimodal learning in terms of both image-to-text and text-to-image generation. However, the success is typically limited to English, leaving other languages largely behind. Building a competitive counterpart in other languages is highly challenging due to the low-resource nature of non-English multimodal data (i.e., lack of large-scale, high-quality image-text data). In this work, we propose MPM, an effective training paradigm for training large multimodal models in low-resource languages. MPM demonstrates that Multilingual language models can Pivot zero-shot Multimodal learning across languages. Specifically, based on a strong multilingual large language model, multimodal models pretrained on English-only image-text data can well generalize to other languages in a zero-shot manner for both image-to-text and text-to-image generation, even surpassing models trained on image-text data in native languages. Taking Chinese as a practice of MPM, we build large multimodal models VisCPM in image-to-text and text-to-image generation, which achieve state-of-the-art (open-source) performance in Chinese. To facilitate future research, we open-source codes and model weights at https://github.com/OpenBMB/VisCPM.git.
ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
Oct 14, 2022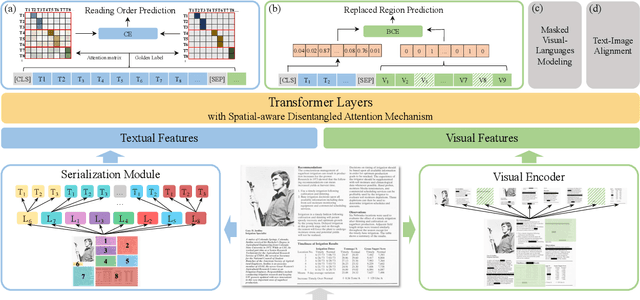



Recent years have witnessed the rise and success of pre-training techniques in visually-rich document understanding. However, most existing methods lack the systematic mining and utilization of layout-centered knowledge, leading to sub-optimal performances. In this paper, we propose ERNIE-Layout, a novel document pre-training solution with layout knowledge enhancement in the whole workflow, to learn better representations that combine the features from text, layout, and image. Specifically, we first rearrange input sequences in the serialization stage, and then present a correlative pre-training task, reading order prediction, to learn the proper reading order of documents. To improve the layout awareness of the model, we integrate a spatial-aware disentangled attention into the multi-modal transformer and a replaced regions prediction task into the pre-training phase. Experimental results show that ERNIE-Layout achieves superior performance on various downstream tasks, setting new state-of-the-art on key information extraction, document image classification, and document question answering datasets. The code and models are publicly available at http://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout.
ERNIE-mmLayout: Multi-grained MultiModal Transformer for Document Understanding
Sep 18, 2022


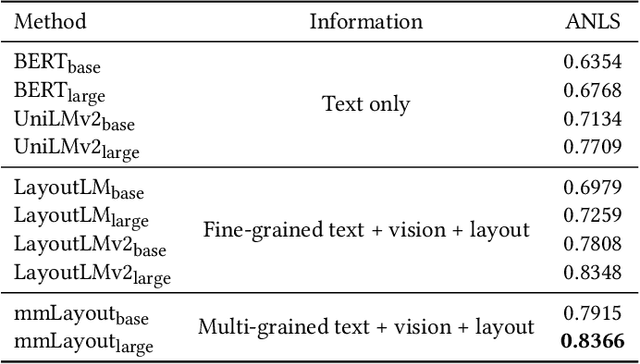
Recent efforts of multimodal Transformers have improved Visually Rich Document Understanding (VrDU) tasks via incorporating visual and textual information. However, existing approaches mainly focus on fine-grained elements such as words and document image patches, making it hard for them to learn from coarse-grained elements, including natural lexical units like phrases and salient visual regions like prominent image regions. In this paper, we attach more importance to coarse-grained elements containing high-density information and consistent semantics, which are valuable for document understanding. At first, a document graph is proposed to model complex relationships among multi-grained multimodal elements, in which salient visual regions are detected by a cluster-based method. Then, a multi-grained multimodal Transformer called mmLayout is proposed to incorporate coarse-grained information into existing pre-trained fine-grained multimodal Transformers based on the graph. In mmLayout, coarse-grained information is aggregated from fine-grained, and then, after further processing, is fused back into fine-grained for final prediction. Furthermore, common sense enhancement is introduced to exploit the semantic information of natural lexical units. Experimental results on four tasks, including information extraction and document question answering, show that our method can improve the performance of multimodal Transformers based on fine-grained elements and achieve better performance with fewer parameters. Qualitative analyses show that our method can capture consistent semantics in coarse-grained elements.