 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZebra-CoT: A Dataset for Interleaved Vision Language Reasoning
Jul 22, 2025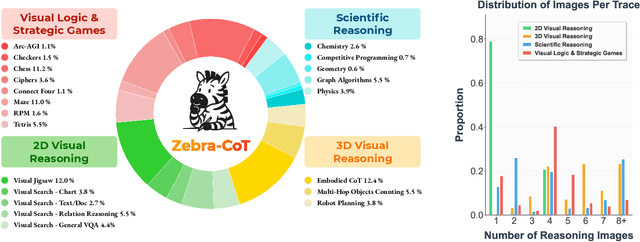

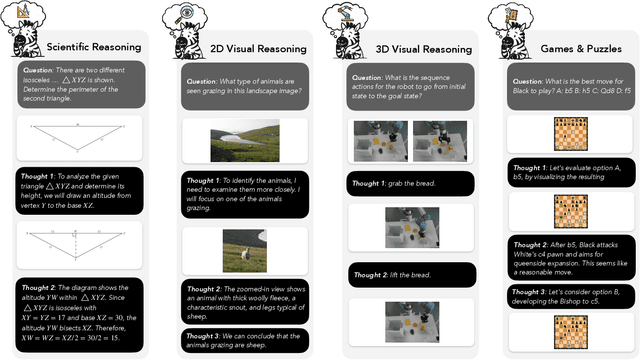

Humans often use visual aids, for example diagrams or sketches, when solving complex problems. Training multimodal models to do the same, known as Visual Chain of Thought (Visual CoT), is challenging due to: (1) poor off-the-shelf visual CoT performance, which hinders reinforcement learning, and (2) the lack of high-quality visual CoT training data. We introduce $\textbf{Zebra-CoT}$, a diverse large-scale dataset with 182,384 samples, containing logically coherent interleaved text-image reasoning traces. We focus on four categories of tasks where sketching or visual reasoning is especially natural, spanning scientific questions such as geometry, physics, and algorithms; 2D visual reasoning tasks like visual search and jigsaw puzzles; 3D reasoning tasks including 3D multi-hop inference, embodied and robot planning; visual logic problems and strategic games like chess. Fine-tuning the Anole-7B model on the Zebra-CoT training corpus results in an improvement of +12% in our test-set accuracy and yields up to +13% performance gain on standard VLM benchmark evaluations. Fine-tuning Bagel-7B yields a model that generates high-quality interleaved visual reasoning chains, underscoring Zebra-CoT's effectiveness for developing multimodal reasoning abilities. We open-source our dataset and models to support development and evaluation of visual CoT.
Resa: Transparent Reasoning Models via SAEs
Jun 11, 2025How cost-effectively can we elicit strong reasoning in language models by leveraging their underlying representations? We answer this question with Resa, a family of 1.5B reasoning models trained via a novel and efficient sparse autoencoder tuning (SAE-Tuning) procedure. This method first trains an SAE to capture reasoning abilities from a source model, and then uses the trained SAE to guide a standard supervised fine-tuning process to elicit such abilities in a target model, all using verified question-answer data without any reasoning traces. Notably, when applied to certain base models before further RL post-training, SAE-Tuning retains >97% of its RL-trained counterpart's reasoning performance while reducing training costs by >2000x to roughly \$1 and training time by >450x to around 20 minutes. Furthermore, when applied to lightly RL-trained models (e.g., within 1 hour on 2 GPUs), it enables reasoning performance such as 43.33% Pass@1 on AIME24 and 90% Pass@1 on AMC23 for only around \$1 additional cost. Surprisingly, the reasoning abilities extracted via SAEs are potentially both generalizable and modular. Generality means abilities extracted from one dataset still elevate performance on a larger and overlapping corpus. Modularity means abilities extracted from Qwen or Qwen-Math can be attached to the R1-Distill model at test time, without any retraining, and yield comparable gains. Extensive ablations validate these findings and all artifacts are fully open-sourced.
Textual Steering Vectors Can Improve Visual Understanding in Multimodal Large Language Models
May 20, 2025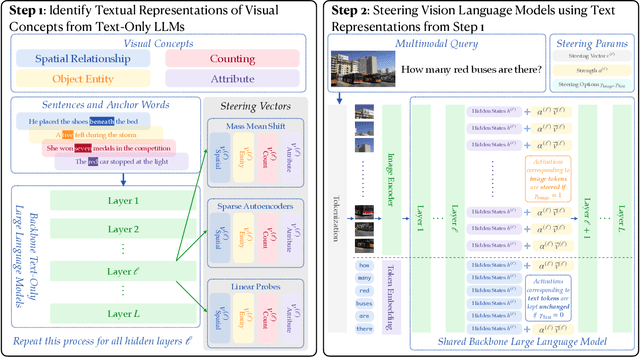
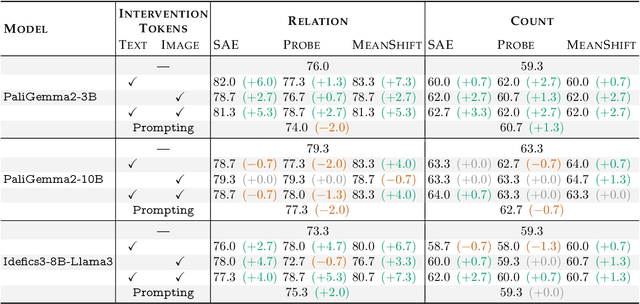
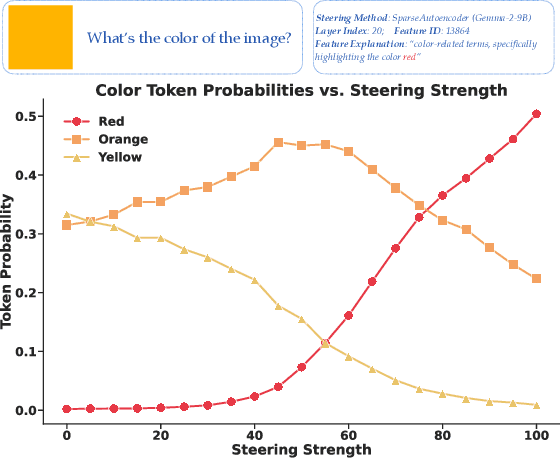
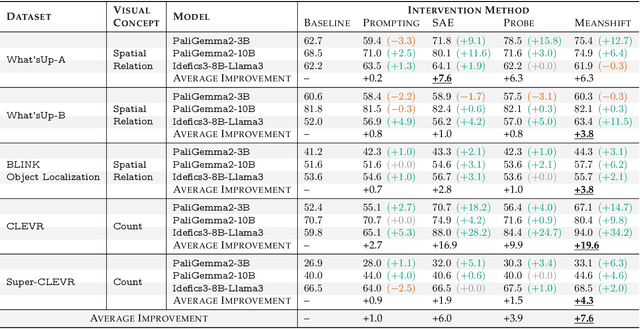
Steering methods have emerged as effective and targeted tools for guiding large language models' (LLMs) behavior without modifying their parameters. Multimodal large language models (MLLMs), however, do not currently enjoy the same suite of techniques, due in part to their recency and architectural diversity. Inspired by this gap, we investigate whether MLLMs can be steered using vectors derived from their text-only LLM backbone, via sparse autoencoders (SAEs), mean shift, and linear probing. We find that text-derived steering consistently enhances multimodal accuracy across diverse MLLM architectures and visual tasks. In particular, mean shift boosts spatial relationship accuracy on CV-Bench by up to +7.3% and counting accuracy by up to +3.3%, outperforming prompting and exhibiting strong generalization to out-of-distribution datasets. These results highlight textual steering vectors as a powerful, efficient mechanism for enhancing grounding in MLLMs with minimal additional data collection and computational overhead.
Tina: Tiny Reasoning Models via LoRA
Apr 22, 2025How cost-effectively can strong reasoning abilities be achieved in language models? Driven by this fundamental question, we present Tina, a family of tiny reasoning models achieved with high cost-efficiency. Notably, Tina demonstrates that substantial reasoning performance can be developed using only minimal resources, by applying parameter-efficient updates during reinforcement learning (RL), using low-rank adaptation (LoRA), to an already tiny 1.5B parameter base model. This minimalist approach produces models that achieve reasoning performance which is competitive with, and sometimes surpasses, SOTA RL reasoning models built upon the same base model. Crucially, this is achieved at a tiny fraction of the computational post-training cost employed by existing SOTA models. In fact, the best Tina model achieves a >20\% reasoning performance increase and 43.33\% Pass@1 accuracy on AIME24, at only \$9 USD post-training and evaluation cost (i.e., an estimated 260x cost reduction). Our work reveals the surprising effectiveness of efficient RL reasoning via LoRA. We validate this across multiple open-source reasoning datasets and various ablation settings starting with a single, fixed set of hyperparameters. Furthermore, we hypothesize that this effectiveness and efficiency stem from LoRA rapidly adapting the model to the structural format of reasoning rewarded by RL, while largely preserving the base model's underlying knowledge. In service of accessibility and open research, we fully open-source all code, training logs, and model weights \& checkpoints.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
METAGENE-1: Metagenomic Foundation Model for Pandemic Monitoring
Jan 03, 2025



We pretrain METAGENE-1, a 7-billion-parameter autoregressive transformer model, which we refer to as a metagenomic foundation model, on a novel corpus of diverse metagenomic DNA and RNA sequences comprising over 1.5 trillion base pairs. This dataset is sourced from a large collection of human wastewater samples, processed and sequenced using deep metagenomic (next-generation) sequencing methods. Unlike genomic models that focus on individual genomes or curated sets of specific species, the aim of METAGENE-1 is to capture the full distribution of genomic information present within this wastewater, to aid in tasks relevant to pandemic monitoring and pathogen detection. We carry out byte-pair encoding (BPE) tokenization on our dataset, tailored for metagenomic sequences, and then pretrain our model. In this paper, we first detail the pretraining dataset, tokenization strategy, and model architecture, highlighting the considerations and design choices that enable the effective modeling of metagenomic data. We then show results of pretraining this model on our metagenomic dataset, providing details about our losses, system metrics, and training stability over the course of pretraining. Finally, we demonstrate the performance of METAGENE-1, which achieves state-of-the-art results on a set of genomic benchmarks and new evaluations focused on human-pathogen detection and genomic sequence embedding, showcasing its potential for public health applications in pandemic monitoring, biosurveillance, and early detection of emerging health threats.
Euclid: Supercharging Multimodal LLMs with Synthetic High-Fidelity Visual Descriptions
Dec 11, 2024Multimodal large language models (MLLMs) have made rapid progress in recent years, yet continue to struggle with low-level visual perception (LLVP) -- particularly the ability to accurately describe the geometric details of an image. This capability is crucial for applications in areas such as robotics, medical image analysis, and manufacturing. In this paper, we first introduce Geoperception, a benchmark designed to evaluate an MLLM's ability to accurately transcribe 2D geometric information from an image. Using this benchmark, we demonstrate the limitations of leading MLLMs, and then conduct a comprehensive empirical study to explore strategies for improving their performance on geometric tasks. Our findings highlight the benefits of certain model architectures, training techniques, and data strategies, including the use of high-fidelity synthetic data and multi-stage training with a data curriculum. Notably, we find that a data curriculum enables models to learn challenging geometry understanding tasks which they fail to learn from scratch. Leveraging these insights, we develop Euclid, a family of models specifically optimized for strong low-level geometric perception. Although purely trained on synthetic multimodal data, Euclid shows strong generalization ability to novel geometry shapes. For instance, Euclid outperforms the best closed-source model, Gemini-1.5-Pro, by up to 58.56% on certain Geoperception benchmark tasks and 10.65% on average across all tasks.
Game-theoretic LLM: Agent Workflow for Negotiation Games
Nov 12, 2024



This paper investigates the rationality of large language models (LLMs) in strategic decision-making contexts, specifically within the framework of game theory. We evaluate several state-of-the-art LLMs across a spectrum of complete-information and incomplete-information games. Our findings reveal that LLMs frequently deviate from rational strategies, particularly as the complexity of the game increases with larger payoff matrices or deeper sequential trees. To address these limitations, we design multiple game-theoretic workflows that guide the reasoning and decision-making processes of LLMs. These workflows aim to enhance the models' ability to compute Nash Equilibria and make rational choices, even under conditions of uncertainty and incomplete information. Experimental results demonstrate that the adoption of these workflows significantly improves the rationality and robustness of LLMs in game-theoretic tasks. Specifically, with the workflow, LLMs exhibit marked improvements in identifying optimal strategies, achieving near-optimal allocations in negotiation scenarios, and reducing susceptibility to exploitation during negotiations. Furthermore, we explore the meta-strategic considerations of whether it is rational for agents to adopt such workflows, recognizing that the decision to use or forgo the workflow constitutes a game-theoretic issue in itself. Our research contributes to a deeper understanding of LLMs' decision-making capabilities in strategic contexts and provides insights into enhancing their rationality through structured workflows. The findings have implications for the development of more robust and strategically sound AI agents capable of navigating complex interactive environments. Code and data supporting this study are available at \url{https://github.com/Wenyueh/game_theory}.
MatViX: Multimodal Information Extraction from Visually Rich Articles
Oct 27, 2024Multimodal information extraction (MIE) is crucial for scientific literature, where valuable data is often spread across text, figures, and tables. In materials science, extracting structured information from research articles can accelerate the discovery of new materials. However, the multimodal nature and complex interconnections of scientific content present challenges for traditional text-based methods. We introduce \textsc{MatViX}, a benchmark consisting of $324$ full-length research articles and $1,688$ complex structured JSON files, carefully curated by domain experts. These JSON files are extracted from text, tables, and figures in full-length documents, providing a comprehensive challenge for MIE. We introduce an evaluation method to assess the accuracy of curve similarity and the alignment of hierarchical structures. Additionally, we benchmark vision-language models (VLMs) in a zero-shot manner, capable of processing long contexts and multimodal inputs, and show that using a specialized model (DePlot) can improve performance in extracting curves. Our results demonstrate significant room for improvement in current models. Our dataset and evaluation code are available\footnote{\url{https://matvix-bench.github.io/}}.
IsoBench: Benchmarking Multimodal Foundation Models on Isomorphic Representations
Apr 02, 2024
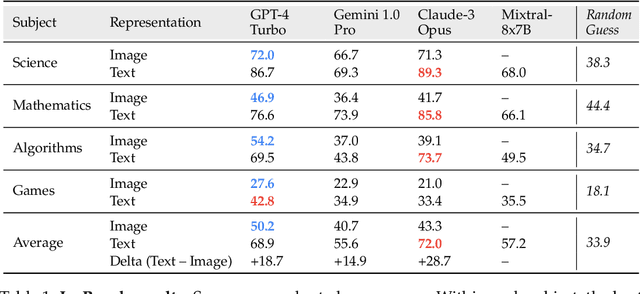
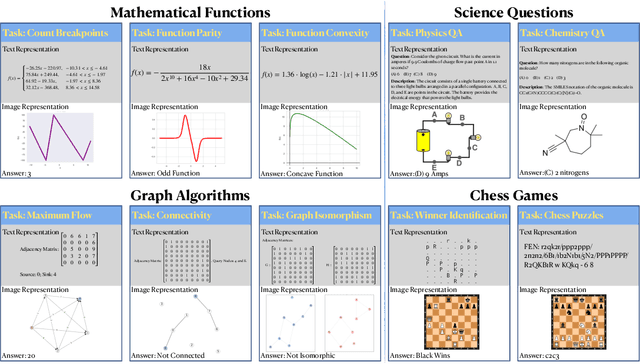
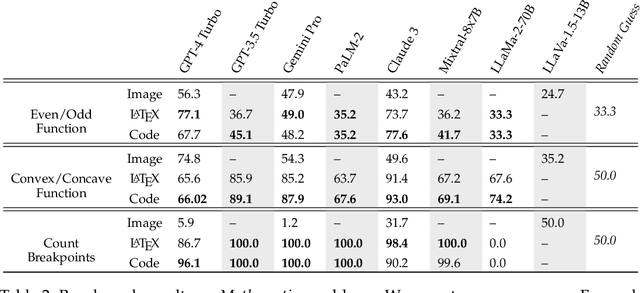
Current foundation models exhibit impressive capabilities when prompted either with text only or with both image and text inputs. But do their capabilities change depending on the input modality? In this work, we propose $\textbf{IsoBench}$, a benchmark dataset containing problems from four major areas: math, science, algorithms, and games. Each example is presented with multiple $\textbf{isomorphic representations}$ of inputs, such as visual, textual, and mathematical presentations. IsoBench provides fine-grained feedback to diagnose performance gaps caused by the form of the representation. Across various foundation models, we observe that on the same problem, models have a consistent preference towards textual representations. Most prominently, when evaluated on all IsoBench problems, Claude-3 Opus performs 28.7 points worse when provided with images instead of text; similarly, GPT-4 Turbo is 18.7 points worse and Gemini Pro is 14.9 points worse. Finally, we present two prompting techniques, $\textit{IsoCombination}$ and $\textit{IsoScratchPad}$, which improve model performance by considering combinations of, and translations between, different input representations.