 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatViX: Multimodal Information Extraction from Visually Rich Articles
Oct 27, 2024



Multimodal information extraction (MIE) is crucial for scientific literature, where valuable data is often spread across text, figures, and tables. In materials science, extracting structured information from research articles can accelerate the discovery of new materials. However, the multimodal nature and complex interconnections of scientific content present challenges for traditional text-based methods. We introduce \textsc{MatViX}, a benchmark consisting of $324$ full-length research articles and $1,688$ complex structured JSON files, carefully curated by domain experts. These JSON files are extracted from text, tables, and figures in full-length documents, providing a comprehensive challenge for MIE. We introduce an evaluation method to assess the accuracy of curve similarity and the alignment of hierarchical structures. Additionally, we benchmark vision-language models (VLMs) in a zero-shot manner, capable of processing long contexts and multimodal inputs, and show that using a specialized model (DePlot) can improve performance in extracting curves. Our results demonstrate significant room for improvement in current models. Our dataset and evaluation code are available\footnote{\url{https://matvix-bench.github.io/}}.
Your Large Language Models Are Leaving Fingerprints
May 22, 2024It has been shown that finetuned transformers and other supervised detectors effectively distinguish between human and machine-generated text in some situations arXiv:2305.13242, but we find that even simple classifiers on top of n-gram and part-of-speech features can achieve very robust performance on both in- and out-of-domain data. To understand how this is possible, we analyze machine-generated output text in five datasets, finding that LLMs possess unique fingerprints that manifest as slight differences in the frequency of certain lexical and morphosyntactic features. We show how to visualize such fingerprints, describe how they can be used to detect machine-generated text and find that they are even robust across textual domains. We find that fingerprints are often persistent across models in the same model family (e.g. llama-13b vs. llama-65b) and that models fine-tuned for chat are easier to detect than standard language models, indicating that LLM fingerprints may be directly induced by the training data.
Tailoring Vaccine Messaging with Common-Ground Opinions
May 17, 2024

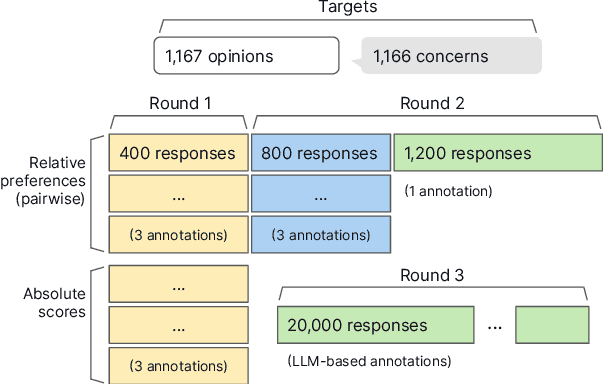

One way to personalize chatbot interactions is by establishing common ground with the intended reader. A domain where establishing mutual understanding could be particularly impactful is vaccine concerns and misinformation. Vaccine interventions are forms of messaging which aim to answer concerns expressed about vaccination. Tailoring responses in this domain is difficult, since opinions often have seemingly little ideological overlap. We define the task of tailoring vaccine interventions to a Common-Ground Opinion (CGO). Tailoring responses to a CGO involves meaningfully improving the answer by relating it to an opinion or belief the reader holds. In this paper we introduce TAILOR-CGO, a dataset for evaluating how well responses are tailored to provided CGOs. We benchmark several major LLMs on this task; finding GPT-4-Turbo performs significantly better than others. We also build automatic evaluation metrics, including an efficient and accurate BERT model that outperforms finetuned LLMs, investigate how to successfully tailor vaccine messaging to CGOs, and provide actionable recommendations from this investigation. Code and model weights: https://github.com/rickardstureborg/tailor-cgo Dataset: https://huggingface.co/datasets/DukeNLP/tailor-cgo
Large Language Models are Inconsistent and Biased Evaluators
May 02, 2024The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low "inter-sample" agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
Hierarchical Multi-Label Classification of Online Vaccine Concerns
Feb 01, 2024Vaccine concerns are an ever-evolving target, and can shift quickly as seen during the COVID-19 pandemic. Identifying longitudinal trends in vaccine concerns and misinformation might inform the healthcare space by helping public health efforts strategically allocate resources or information campaigns. We explore the task of detecting vaccine concerns in online discourse using large language models (LLMs) in a zero-shot setting without the need for expensive training datasets. Since real-time monitoring of online sources requires large-scale inference, we explore cost-accuracy trade-offs of different prompting strategies and offer concrete takeaways that may inform choices in system designs for current applications. An analysis of different prompting strategies reveals that classifying the concerns over multiple passes through the LLM, each consisting a boolean question whether the text mentions a vaccine concern or not, works the best. Our results indicate that GPT-4 can strongly outperform crowdworker accuracy when compared to ground truth annotations provided by experts on the recently introduced VaxConcerns dataset, achieving an overall F1 score of 78.7%.
Do Not Harm Protected Groups in Debiasing Language Representation Models
Oct 27, 2023Language Representation Models (LRMs) trained with real-world data may capture and exacerbate undesired bias and cause unfair treatment of people in various demographic groups. Several techniques have been investigated for applying interventions to LRMs to remove bias in benchmark evaluations on, for example, word embeddings. However, the negative side effects of debiasing interventions are usually not revealed in the downstream tasks. We propose xGAP-DEBIAS, a set of evaluations on assessing the fairness of debiasing. In this work, We examine four debiasing techniques on a real-world text classification task and show that reducing biasing is at the cost of degrading performance for all demographic groups, including those the debiasing techniques aim to protect. We advocate that a debiasing technique should have good downstream performance with the constraint of ensuring no harm to the protected group.
Learning the Legibility of Visual Text Perturbations
Mar 10, 2023Many adversarial attacks in NLP perturb inputs to produce visually similar strings ('ergo' $\rightarrow$ '$\epsilon$rgo') which are legible to humans but degrade model performance. Although preserving legibility is a necessary condition for text perturbation, little work has been done to systematically characterize it; instead, legibility is typically loosely enforced via intuitions around the nature and extent of perturbations. Particularly, it is unclear to what extent can inputs be perturbed while preserving legibility, or how to quantify the legibility of a perturbed string. In this work, we address this gap by learning models that predict the legibility of a perturbed string, and rank candidate perturbations based on their legibility. To do so, we collect and release LEGIT, a human-annotated dataset comprising the legibility of visually perturbed text. Using this dataset, we build both text- and vision-based models which achieve up to $0.91$ F1 score in predicting whether an input is legible, and an accuracy of $0.86$ in predicting which of two given perturbations is more legible. Additionally, we discover that legible perturbations from the LEGIT dataset are more effective at lowering the performance of NLP models than best-known attack strategies, suggesting that current models may be vulnerable to a broad range of perturbations beyond what is captured by existing visual attacks. Data, code, and models are available at https://github.com/dvsth/learning-legibility-2023.