 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailoring Vaccine Messaging with Common-Ground Opinions
May 17, 2024


One way to personalize chatbot interactions is by establishing common ground with the intended reader. A domain where establishing mutual understanding could be particularly impactful is vaccine concerns and misinformation. Vaccine interventions are forms of messaging which aim to answer concerns expressed about vaccination. Tailoring responses in this domain is difficult, since opinions often have seemingly little ideological overlap. We define the task of tailoring vaccine interventions to a Common-Ground Opinion (CGO). Tailoring responses to a CGO involves meaningfully improving the answer by relating it to an opinion or belief the reader holds. In this paper we introduce TAILOR-CGO, a dataset for evaluating how well responses are tailored to provided CGOs. We benchmark several major LLMs on this task; finding GPT-4-Turbo performs significantly better than others. We also build automatic evaluation metrics, including an efficient and accurate BERT model that outperforms finetuned LLMs, investigate how to successfully tailor vaccine messaging to CGOs, and provide actionable recommendations from this investigation. Code and model weights: https://github.com/rickardstureborg/tailor-cgo Dataset: https://huggingface.co/datasets/DukeNLP/tailor-cgo
GMNLP at SemEval-2023 Task 12: Sentiment Analysis with Phylogeny-Based Adapters
Apr 25, 2023This report describes GMU's sentiment analysis system for the SemEval-2023 shared task AfriSenti-SemEval. We participated in all three sub-tasks: Monolingual, Multilingual, and Zero-Shot. Our approach uses models initialized with AfroXLMR-large, a pre-trained multilingual language model trained on African languages and fine-tuned correspondingly. We also introduce augmented training data along with original training data. Alongside finetuning, we perform phylogeny-based adapter tuning to create several models and ensemble the best models for the final submission. Our system achieves the best F1-score on track 5: Amharic, with 6.2 points higher F1-score than the second-best performing system on this track. Overall, our system ranks 5th among the 10 systems participating in all 15 tracks.
Noisy Parallel Data Alignment
Jan 23, 2023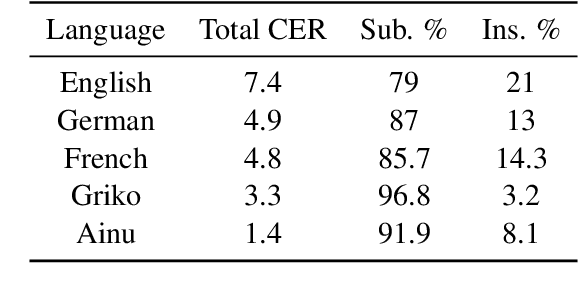
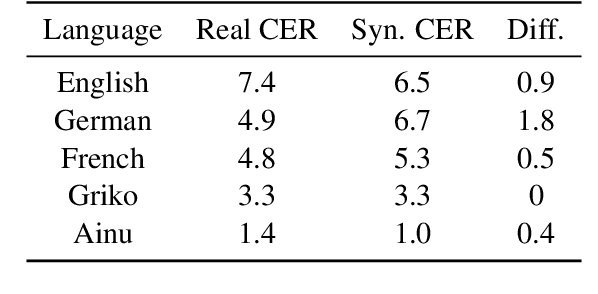
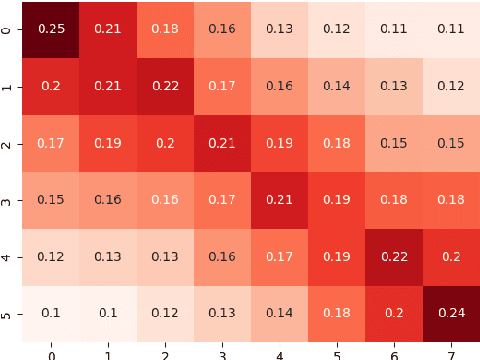
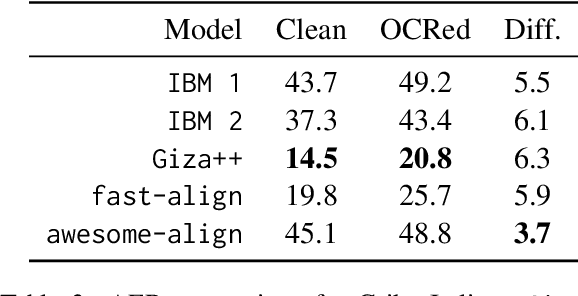
An ongoing challenge in current natural language processing is how its major advancements tend to disproportionately favor resource-rich languages, leaving a significant number of under-resourced languages behind. Due to the lack of resources required to train and evaluate models, most modern language technologies are either nonexistent or unreliable to process endangered, local, and non-standardized languages. Optical character recognition (OCR) is often used to convert endangered language documents into machine-readable data. However, such OCR output is typically noisy, and most word alignment models are not built to work under such noisy conditions. In this work, we study the existing word-level alignment models under noisy settings and aim to make them more robust to noisy data. Our noise simulation and structural biasing method, tested on multiple language pairs, manages to reduce the alignment error rate on a state-of-the-art neural-based alignment model up to 59.6%.