 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage and Speech Technology for Central Kurdish Varieties
Mar 04, 2024



Kurdish, an Indo-European language spoken by over 30 million speakers, is considered a dialect continuum and known for its diversity in language varieties. Previous studies addressing language and speech technology for Kurdish handle it in a monolithic way as a macro-language, resulting in disparities for dialects and varieties for which there are few resources and tools available. In this paper, we take a step towards developing resources for language and speech technology for varieties of Central Kurdish, creating a corpus by transcribing movies and TV series as an alternative to fieldwork. Additionally, we report the performance of machine translation, automatic speech recognition, and language identification as downstream tasks evaluated on Central Kurdish varieties. Data and models are publicly available under an open license at https://github.com/sinaahmadi/CORDI.
A Morphologically-Aware Dictionary-based Data Augmentation Technique for Machine Translation of Under-Represented Languages
Feb 02, 2024The availability of parallel texts is crucial to the performance of machine translation models. However, most of the world's languages face the predominant challenge of data scarcity. In this paper, we propose strategies to synthesize parallel data relying on morpho-syntactic information and using bilingual lexicons along with a small amount of seed parallel data. Our methodology adheres to a realistic scenario backed by the small parallel seed data. It is linguistically informed, as it aims to create augmented data that is more likely to be grammatically correct. We analyze how our synthetic data can be combined with raw parallel data and demonstrate a consistent improvement in performance in our experiments on 14 languages (28 English <-> X pairs) ranging from well- to very low-resource ones. Our method leads to improvements even when using only five seed sentences and a bilingual lexicon.
A Case Study on Filtering for End-to-End Speech Translation
Feb 02, 2024It is relatively easy to mine a large parallel corpus for any machine learning task, such as speech-to-text or speech-to-speech translation. Although these mined corpora are large in volume, their quality is questionable. This work shows that the simplest filtering technique can trim down these big, noisy datasets to a more manageable, clean dataset. We also show that using this clean dataset can improve the model's performance, as in the case of the multilingual-to-English Speech Translation (ST) model, where, on average, we obtain a 4.65 BLEU score improvement.
CODET: A Benchmark for Contrastive Dialectal Evaluation of Machine Translation
May 26, 2023
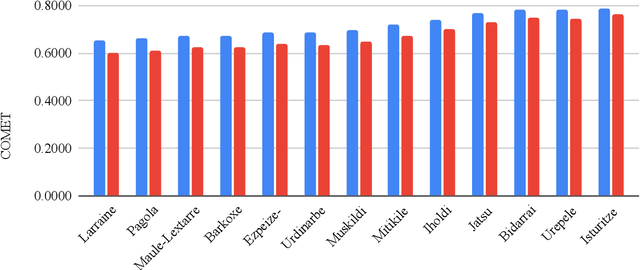


Neural machine translation (NMT) systems exhibit limited robustness in handling source-side linguistic variations. Their performance tends to degrade when faced with even slight deviations in language usage, such as different domains or variations introduced by second-language speakers. It is intuitive to extend this observation to encompass dialectal variations as well, but the work allowing the community to evaluate MT systems on this dimension is limited. To alleviate this issue, we compile and release \dataset, a contrastive dialectal benchmark encompassing 882 different variations from nine different languages. We also quantitatively demonstrate the challenges large MT models face in effectively translating dialectal variants. We are releasing all code and data.
BIG-C: a Multimodal Multi-Purpose Dataset for Bemba
May 26, 2023
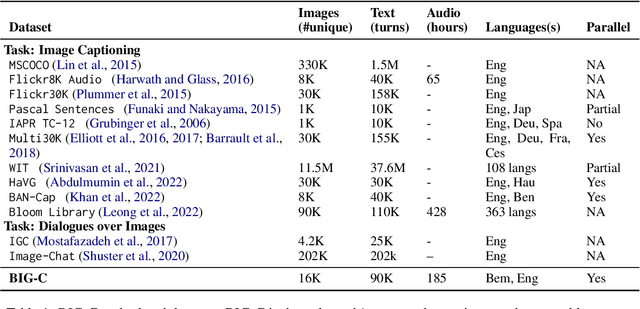
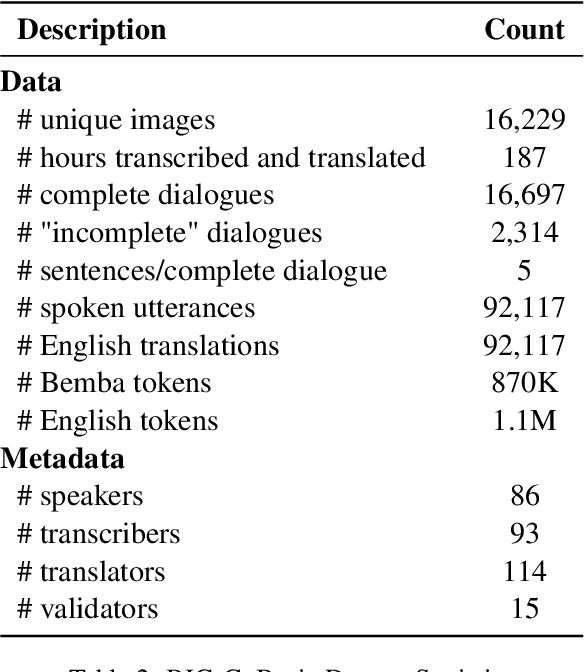

We present BIG-C (Bemba Image Grounded Conversations), a large multimodal dataset for Bemba. While Bemba is the most populous language of Zambia, it exhibits a dearth of resources which render the development of language technologies or language processing research almost impossible. The dataset is comprised of multi-turn dialogues between Bemba speakers based on images, transcribed and translated into English. There are more than 92,000 utterances/sentences, amounting to more than 180 hours of audio data with corresponding transcriptions and English translations. We also provide baselines on speech recognition (ASR), machine translation (MT) and speech translation (ST) tasks, and sketch out other potential future multimodal uses of our dataset. We hope that by making the dataset available to the research community, this work will foster research and encourage collaboration across the language, speech, and vision communities especially for languages outside the "traditionally" used high-resourced ones. All data and code are publicly available: https://github.com/csikasote/bigc.
LIMIT: Language Identification, Misidentification, and Translation using Hierarchical Models in 350+ Languages
May 23, 2023Knowing the language of an input text/audio is a necessary first step for using almost every natural language processing (NLP) tool such as taggers, parsers, or translation systems. Language identification is a well-studied problem, sometimes even considered solved; in reality, most of the world's 7000 languages are not supported by current systems. This lack of representation affects large-scale data mining efforts and further exacerbates data shortage for low-resource languages. We take a step towards tackling the data bottleneck by compiling a corpus of over 50K parallel children's stories in 350+ languages and dialects, and the computation bottleneck by building lightweight hierarchical models for language identification. Our data can serve as benchmark data for language identification of short texts and for understudied translation directions such as those between Indian or African languages. Our proposed method, Hierarchical LIMIT, uses limited computation to expand coverage into excluded languages while maintaining prediction quality.
GMNLP at SemEval-2023 Task 12: Sentiment Analysis with Phylogeny-Based Adapters
Apr 25, 2023



This report describes GMU's sentiment analysis system for the SemEval-2023 shared task AfriSenti-SemEval. We participated in all three sub-tasks: Monolingual, Multilingual, and Zero-Shot. Our approach uses models initialized with AfroXLMR-large, a pre-trained multilingual language model trained on African languages and fine-tuned correspondingly. We also introduce augmented training data along with original training data. Alongside finetuning, we perform phylogeny-based adapter tuning to create several models and ensemble the best models for the final submission. Our system achieves the best F1-score on track 5: Amharic, with 6.2 points higher F1-score than the second-best performing system on this track. Overall, our system ranks 5th among the 10 systems participating in all 15 tracks.