 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnglish to Central Kurdish Speech Translation: Corpus Creation, Evaluation, and Orthographic Standardization
Apr 01, 2026We present KUTED, a speech-to-text translation (S2TT) dataset for Central Kurdish, derived from TED and TEDx talks. The corpus comprises 91,000 sentence pairs, including 170 hours of English audio, 1.65 million English tokens, and 1.40 million Central Kurdish tokens. We evaluate KUTED on the S2TT task and find that orthographic variation significantly degrades Kurdish translation performance, producing nonstandard outputs. To address this, we propose a systematic text standardization approach that yields substantial performance gains and more consistent translations. On a test set separated from TED talks, a fine-tuned Seamless model achieves 15.18 BLEU, and we improve Seamless baseline by 3.0 BLEU on the FLEURS benchmark. We also train a Transformer model from scratch and evaluate a cascaded system that combines Seamless (ASR) with NLLB (MT).
FLEURS-Kobani: Extending the FLEURS Dataset for Northern Kurdish
Mar 31, 2026FLEURS offers n-way parallel speech for 100+ languages, but Northern Kurdish is not one of them, which limits benchmarking for automatic speech recognition and speech translation tasks in this language. We present FLEURS-Kobani, a Northern Kurdish (ISO 639-3 KMR) spoken extension of the FLEURS benchmark. The FLEURS-Kobani dataset consists of 5,162 validated utterances, totaling 18 hours and 24 minutes. The data were recorded by 31 native speakers. It extends benchmark coverage to an under-resourced Kurdish variety. As baselines, we fine-tuned Whisper v3-large for ASR and E2E S2TT. A two-stage fine-tuning strategy (Common Voice to FLEURS-Kobani) yields the best ASR performance (WER 28.11, CER 9.84 on test). For E2E S2TT (KMR to EN), Whisper achieves 8.68 BLEU on test; we additionally report pivot-derived targets and a cascaded S2TT setup. FLEURS-Kobani provides the first public Northern Kurdish benchmark for evaluation of ASR, S2TT and S2ST tasks. The dataset is publicly released for research use under a CC BY 4.0 license.
From Consensus to Split Decisions: ABC-Stratified Sentiment in Holocaust Oral Histories
Mar 30, 2026Polarity detection becomes substantially more challenging under domain shift, particularly in heterogeneous, long-form narratives with complex discourse structure, such as Holocaust oral histories. This paper presents a corpus-scale diagnostic study of off-the-shelf sentiment classifiers on long-form Holocaust oral histories, using three pretrained transformer-based polarity classifiers on a corpus of 107,305 utterances and 579,013 sentences. After assembling model outputs, we introduce an agreement-based stability taxonomy (ABC) to stratify inter-model output stability. We report pairwise percent agreement, Cohen kappa, Fleiss kappa, and row-normalized confusion matrices to localize systematic disagreement. As an auxiliary descriptive signal, a T5-based emotion classifier is applied to stratified samples from each agreement stratum to compare emotion distributions across strata. The combination of multi-model label triangulation and the ABC taxonomy provides a cautious, operational framework for characterizing where and how sentiment models diverge in sensitive historical narratives. Inter-model agreement is low to moderate overall and is driven primarily by boundary decisions around neutrality.
Language and Speech Technology for Central Kurdish Varieties
Mar 04, 2024



Kurdish, an Indo-European language spoken by over 30 million speakers, is considered a dialect continuum and known for its diversity in language varieties. Previous studies addressing language and speech technology for Kurdish handle it in a monolithic way as a macro-language, resulting in disparities for dialects and varieties for which there are few resources and tools available. In this paper, we take a step towards developing resources for language and speech technology for varieties of Central Kurdish, creating a corpus by transcribing movies and TV series as an alternative to fieldwork. Additionally, we report the performance of machine translation, automatic speech recognition, and language identification as downstream tasks evaluated on Central Kurdish varieties. Data and models are publicly available under an open license at https://github.com/sinaahmadi/CORDI.
Leveraging Multilingual News Websites for Building a Kurdish Parallel Corpus
Oct 04, 2020
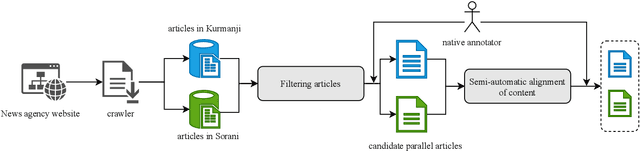
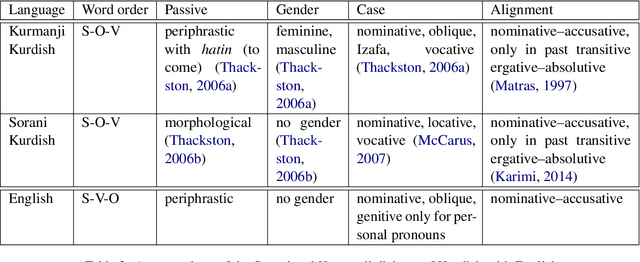
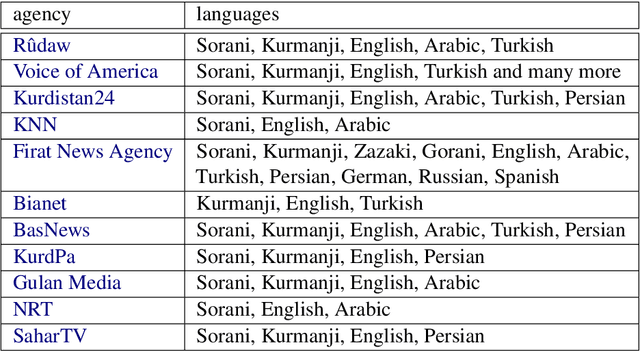
Machine translation has been a major motivation of development in natural language processing. Despite the burgeoning achievements in creating more efficient machine translation systems thanks to deep learning methods, parallel corpora have remained indispensable for progress in the field. In an attempt to create parallel corpora for the Kurdish language, in this paper, we describe our approach in retrieving potentially-alignable news articles from multi-language websites and manually align them across dialects and languages based on lexical similarity and transliteration of scripts. We present a corpus containing 12,327 translation pairs in the two major dialects of Kurdish, Sorani and Kurmanji. We also provide 1,797 and 650 translation pairs in English-Kurmanji and English-Sorani. The corpus is publicly available under the CC BY-NC-SA 4.0 license.