 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoices of the Mountains: Deep Learning-Based Vocal Error Detection System for Kurdish Maqams
Feb 24, 2026Maqam, a singing type, is a significant component of Kurdish music. A maqam singer receives training in a traditional face-to-face or through self-training. Automatic Singing Assessment (ASA) uses machine learning (ML) to provide the accuracy of singing styles and can help learners to improve their performance through error detection. Currently, the available ASA tools follow Western music rules. The musical composition requires all notes to stay within their expected pitch range from start to finish. The system fails to detect micro-intervals and pitch bends, so it identifies Kurdish maqam singing as incorrect even though the singer performs according to traditional rules. Kurdish maqam requires recognizing performance errors within microtonal spaces, which is beyond Western equal temperament. This research is the first attempt to address the mentioned gap. While many error types happen during singing, our focus is on pitch, rhythm, and modal stability errors in the context of Bayati-Kurd. We collected 50 songs from 13 vocalists ( 2-3 hours) and annotated 221 error spans (150 fine pitch, 46 rhythm, 25 modal drift). The data was segmented into 15,199 overlapping windows and converted to log-mel spectrograms. We developed a two-headed CNN-BiLSTM with attention mode to decide whether a window contains an error and to classify it based on the chosen errors. Trained for 20 epochs with early stopping at epoch 10, the model reached a validation macro-F1 of 0.468. On the full 50-song evaluation at a 0.750 threshold, recall was 39.4% and precision 25.8% . Within detected windows, type macro-F1 was 0.387, with F1 of 0.492 (fine pitch), 0.536 (rhythm), and 0.133 (modal drift); modal drift recall was 8.0%. The better performance on common error types shows that the method works, while the poor modal-drift recall shows that more data and balancing are needed.
I can tell whether you are a Native Hawlêri Speaker! How ANN, CNN, and RNN perform in NLI-Native Language Identification
Feb 11, 2026Native Language Identification (NLI) is a task in Natural Language Processing (NLP) that typically determines the native language of an author through their writing or a speaker through their speaking. It has various applications in different areas, such as forensic linguistics and general linguistics studies. Although considerable research has been conducted on NLI regarding two different languages, such as English and German, the literature indicates a significant gap regarding NLI for dialects and subdialects. The gap becomes wider in less-resourced languages such as Kurdish. This research focuses on NLI within the context of a subdialect of Sorani (Central) Kurdish. It aims to investigate the NLI for Hewlêri, a subdialect spoken in Hewlêr (Erbil), the Capital of the Kurdistan Region of Iraq. We collected about 24 hours of speech by recording interviews with 40 native or non-native Hewlêri speakers, 17 female and 23 male. We created three Neural Network-based models: Artificial Neural Network (ANN), Convolutional Neural Network (CNN), and Recurrent Neural Network (RNN), which were evaluated through 66 experiments, covering various time-frames from 1 to 60 seconds, undersampling, oversampling, and cross-validation. The RNN model showed the highest accuracy of 95.92% for 5-second audio segmentation, using an 80:10:10 data splitting scheme. The created dataset is the first speech dataset for NLI on the Hewlêri subdialect in the Sorani Kurdish dialect, which can be of benefit to various research areas.
Which one Performs Better? Wav2Vec or Whisper? Applying both in Badini Kurdish Speech to Text (BKSTT)
Aug 13, 2025Speech-to-text (STT) systems have a wide range of applications. They are available in many languages, albeit at different quality levels. Although Kurdish is considered a less-resourced language from a processing perspective, SST is available for some of the Kurdish dialects, for instance, Sorani (Central Kurdish). However, that is not applied to other Kurdish dialects, Badini and Hawrami, for example. This research is an attempt to address this gap. Bandin, approximately, has two million speakers, and STT systems can help their community use mobile and computer-based technologies while giving their dialect more global visibility. We aim to create a language model based on Badini's speech and evaluate its performance. To cover a conversational aspect, have a proper confidence level of grammatical accuracy, and ready transcriptions, we chose Badini kids' stories, eight books including 78 stories, as the textual input. Six narrators narrated the books, which resulted in approximately 17 hours of recording. We cleaned, segmented, and tokenized the input. The preprocessing produced nearly 15 hours of speech, including 19193 segments and 25221 words. We used Wav2Vec2-Large-XLSR-53 and Whisper-small to develop the language models. The experiments indicate that the transcriptions process based on the Wav2Vec2-Large-XLSR-53 model provides a significantly more accurate and readable output than the Whisper-small model, with 90.38% and 65.45% readability, and 82.67% and 53.17% accuracy, respectively.
TinyDrive: Multiscale Visual Question Answering with Selective Token Routing for Autonomous Driving
May 21, 2025Vision Language Models (VLMs) employed for visual question-answering (VQA) in autonomous driving often require substantial computational resources that pose a challenge for their deployment in resource-constrained vehicles. To address this challenge, we introduce TinyDrive, a lightweight yet effective VLM for multi-view VQA in driving scenarios. Our model comprises two key components including a multiscale vision encoder and a dual-level prioritization mechanism for tokens and sequences. The multiscale encoder facilitates the processing of multi-view images at diverse resolutions through scale injection and cross-scale gating to generate enhanced visual representations. At the token level, we design a token routing mechanism that dynamically selects and process the most informative tokens based on learned importance scores. At the sequence level, we propose integrating normalized loss, uncertainty estimates, and a diversity metric to formulate sequence scores that rank and preserve samples within a sequence priority buffer. Samples with higher scores are more frequently selected for training. TinyDrive is first evaluated on our custom-curated VQA dataset, and it is subsequently tested on the public DriveLM benchmark, where it achieves state-of-the-art language understanding performance. Notably, it achieves relative improvements of 11.1% and 35.4% in BLEU-4 and METEOR scores, respectively, despite having a significantly smaller parameter count.
TS-VLM: Text-Guided SoftSort Pooling for Vision-Language Models in Multi-View Driving Reasoning
May 19, 2025Vision-Language Models (VLMs) have shown remarkable potential in advancing autonomous driving by leveraging multi-modal fusion in order to enhance scene perception, reasoning, and decision-making. Despite their potential, existing models suffer from computational overhead and inefficient integration of multi-view sensor data that make them impractical for real-time deployment in safety-critical autonomous driving applications. To address these shortcomings, this paper is devoted to designing a lightweight VLM called TS-VLM, which incorporates a novel Text-Guided SoftSort Pooling (TGSSP) module. By resorting to semantics of the input queries, TGSSP ranks and fuses visual features from multiple views, enabling dynamic and query-aware multi-view aggregation without reliance on costly attention mechanisms. This design ensures the query-adaptive prioritization of semantically related views, which leads to improved contextual accuracy in multi-view reasoning for autonomous driving. Extensive evaluations on the DriveLM benchmark demonstrate that, on the one hand, TS-VLM outperforms state-of-the-art models with a BLEU-4 score of 56.82, METEOR of 41.91, ROUGE-L of 74.64, and CIDEr of 3.39. On the other hand, TS-VLM reduces computational cost by up to 90%, where the smallest version contains only 20.1 million parameters, making it more practical for real-time deployment in autonomous vehicles.
Automatic Text Summarization (ATS) for Research Documents in Sorani Kurdish
Apr 20, 2025Extracting concise information from scientific documents aids learners, researchers, and practitioners. Automatic Text Summarization (ATS), a key Natural Language Processing (NLP) application, automates this process. While ATS methods exist for many languages, Kurdish remains underdeveloped due to limited resources. This study develops a dataset and language model based on 231 scientific papers in Sorani Kurdish, collected from four academic departments in two universities in the Kurdistan Region of Iraq (KRI), averaging 26 pages per document. Using Sentence Weighting and Term Frequency-Inverse Document Frequency (TF-IDF) algorithms, two experiments were conducted, differing in whether the conclusions were included. The average word count was 5,492.3 in the first experiment and 5,266.96 in the second. Results were evaluated manually and automatically using ROUGE-1, ROUGE-2, and ROUGE-L metrics, with the best accuracy reaching 19.58%. Six experts conducted manual evaluations using three criteria, with results varying by document. This research provides valuable resources for Kurdish NLP researchers to advance ATS and related fields.
Idiom Detection in Sorani Kurdish Texts
Jan 24, 2025



Idiom detection using Natural Language Processing (NLP) is the computerized process of recognizing figurative expressions within a text that convey meanings beyond the literal interpretation of the words. While idiom detection has seen significant progress across various languages, the Kurdish language faces a considerable research gap in this area despite the importance of idioms in tasks like machine translation and sentiment analysis. This study addresses idiom detection in Sorani Kurdish by approaching it as a text classification task using deep learning techniques. To tackle this, we developed a dataset containing 10,580 sentences embedding 101 Sorani Kurdish idioms across diverse contexts. Using this dataset, we developed and evaluated three deep learning models: KuBERT-based transformer sequence classification, a Recurrent Convolutional Neural Network (RCNN), and a BiLSTM model with an attention mechanism. The evaluations revealed that the transformer model, the fine-tuned BERT, consistently outperformed the others, achieving nearly 99% accuracy while the RCNN achieved 96.5% and the BiLSTM 80%. These results highlight the effectiveness of Transformer-based architectures in low-resource languages like Kurdish. This research provides a dataset, three optimized models, and insights into idiom detection, laying a foundation for advancing Kurdish NLP.
Domain-Specific Machine Translation to Translate Medicine Brochures in English to Sorani Kurdish
Jan 23, 2025Access to Kurdish medicine brochures is limited, depriving Kurdish-speaking communities of critical health information. To address this problem, we developed a specialized Machine Translation (MT) model to translate English medicine brochures into Sorani Kurdish using a parallel corpus of 22,940 aligned sentence pairs from 319 brochures, sourced from two pharmaceutical companies in the Kurdistan Region of Iraq (KRI). We trained a Statistical Machine Translation (SMT) model using the Moses toolkit, conducting seven experiments that resulted in BLEU scores ranging from 22.65 to 48.93. We translated three new brochures to improve the evaluation process and encountered unknown words. We addressed unknown words through post-processing with a medical dictionary, resulting in BLEU scores of 56.87, 31.05, and 40.01. Human evaluation by native Kurdish-speaking pharmacists, physicians, and medicine users showed that 50% of professionals found the translations consistent, while 83.3% rated them accurate. Among users, 66.7% considered the translations clear and felt confident using the medications.
Towards Sample-Efficiency and Generalization of Transfer and Inverse Reinforcement Learning: A Comprehensive Literature Review
Nov 15, 2024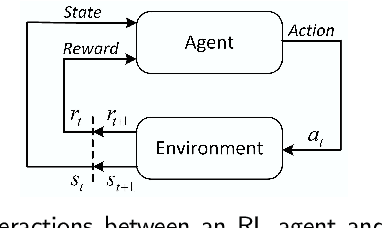
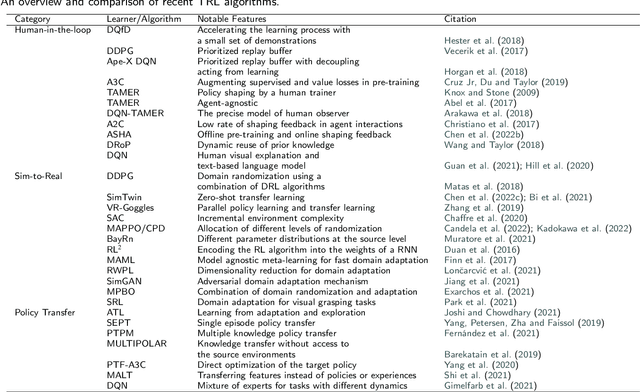
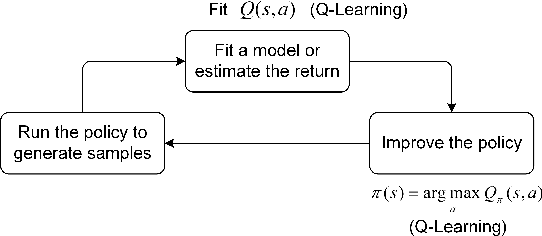
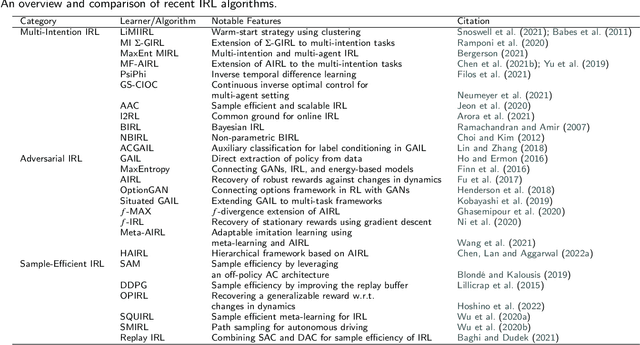
Reinforcement learning (RL) is a sub-domain of machine learning, mainly concerned with solving sequential decision-making problems by a learning agent that interacts with the decision environment to improve its behavior through the reward it receives from the environment. This learning paradigm is, however, well-known for being time-consuming due to the necessity of collecting a large amount of data, making RL suffer from sample inefficiency and difficult generalization. Furthermore, the construction of an explicit reward function that accounts for the trade-off between multiple desiderata of a decision problem is often a laborious task. These challenges have been recently addressed utilizing transfer and inverse reinforcement learning (T-IRL). In this regard, this paper is devoted to a comprehensive review of realizing the sample efficiency and generalization of RL algorithms through T-IRL. Following a brief introduction to RL, the fundamental T-IRL methods are presented and the most recent advancements in each research field have been extensively reviewed. Our findings denote that a majority of recent research works have dealt with the aforementioned challenges by utilizing human-in-the-loop and sim-to-real strategies for the efficient transfer of knowledge from source domains to the target domain under the transfer learning scheme. Under the IRL structure, training schemes that require a low number of experience transitions and extension of such frameworks to multi-agent and multi-intention problems have been the priority of researchers in recent years.
Shifting from endangerment to rebirth in the Artificial Intelligence Age: An Ensemble Machine Learning Approach for Hawrami Text Classification
Sep 25, 2024
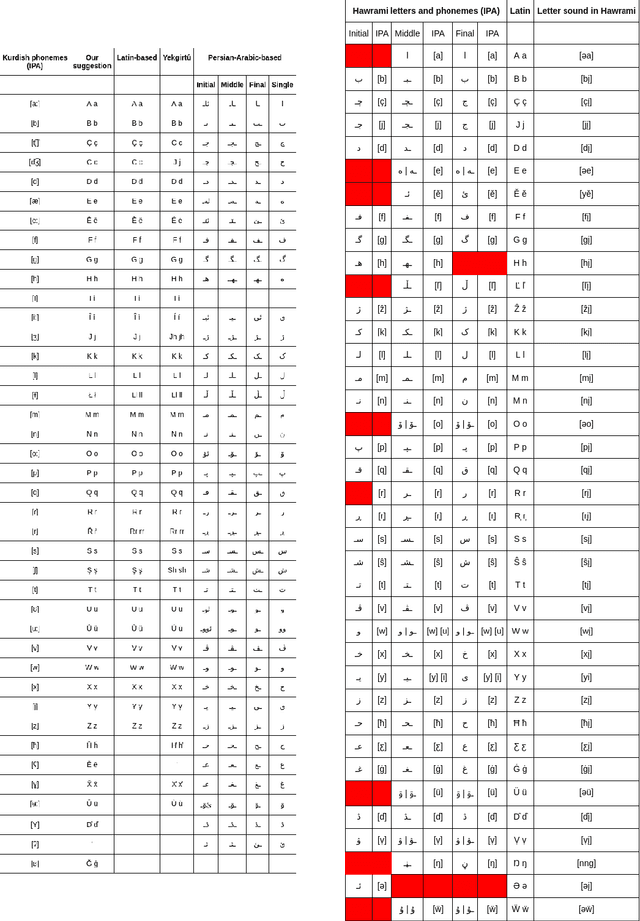
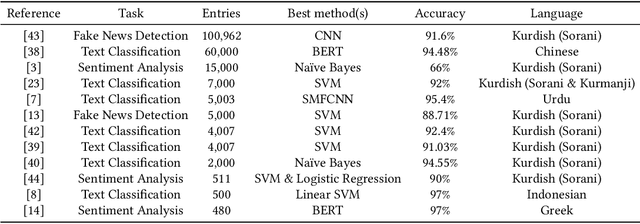
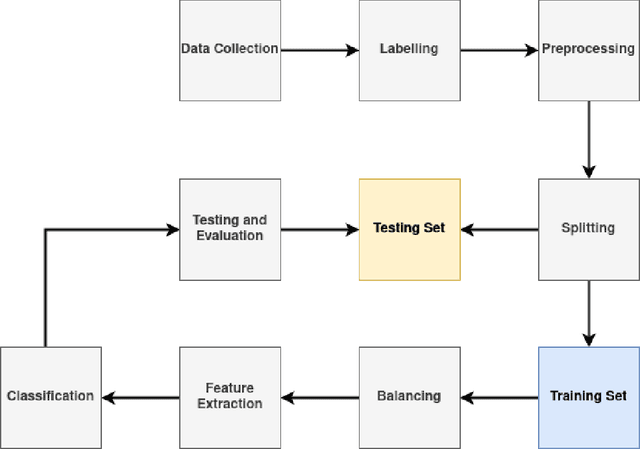
Hawrami, a dialect of Kurdish, is classified as an endangered language as it suffers from the scarcity of data and the gradual loss of its speakers. Natural Language Processing projects can be used to partially compensate for data availability for endangered languages/dialects through a variety of approaches, such as machine translation, language model building, and corpora development. Similarly, NLP projects such as text classification are in language documentation. Several text classification studies have been conducted for Kurdish, but they were mainly dedicated to two particular dialects: Sorani (Central Kurdish) and Kurmanji (Northern Kurdish). In this paper, we introduce various text classification models using a dataset of 6,854 articles in Hawrami labeled into 15 categories by two native speakers. We use K-nearest Neighbor (KNN), Linear Support Vector Machine (Linear SVM), Logistic Regression (LR), and Decision Tree (DT) to evaluate how well those methods perform the classification task. The results indicate that the Linear SVM achieves a 96% of accuracy and outperforms the other approaches.