 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Analysis of Power Consumption in Gasoline, Electric, and Hybrid Vehicles
Aug 11, 2025Accurate power consumption prediction is crucial for improving efficiency and reducing environmental impact, yet traditional methods relying on specialized instruments or rigid physical models are impractical for large-scale, real-world deployment. This study introduces a scalable data-driven method using powertrain dynamic feature sets and both traditional machine learning and deep neural networks to estimate instantaneous and cumulative power consumption in internal combustion engine (ICE), electric vehicle (EV), and hybrid electric vehicle (HEV) platforms. ICE models achieved high instantaneous accuracy with mean absolute error and root mean squared error on the order of $10^{-3}$, and cumulative errors under 3%. Transformer and long short-term memory models performed best for EVs and HEVs, with cumulative errors below 4.1% and 2.1%, respectively. Results confirm the approach's effectiveness across vehicles and models. Uncertainty analysis revealed greater variability in EV and HEV datasets than ICE, due to complex power management, emphasizing the need for robust models for advanced powertrains.
TinyDrive: Multiscale Visual Question Answering with Selective Token Routing for Autonomous Driving
May 21, 2025Vision Language Models (VLMs) employed for visual question-answering (VQA) in autonomous driving often require substantial computational resources that pose a challenge for their deployment in resource-constrained vehicles. To address this challenge, we introduce TinyDrive, a lightweight yet effective VLM for multi-view VQA in driving scenarios. Our model comprises two key components including a multiscale vision encoder and a dual-level prioritization mechanism for tokens and sequences. The multiscale encoder facilitates the processing of multi-view images at diverse resolutions through scale injection and cross-scale gating to generate enhanced visual representations. At the token level, we design a token routing mechanism that dynamically selects and process the most informative tokens based on learned importance scores. At the sequence level, we propose integrating normalized loss, uncertainty estimates, and a diversity metric to formulate sequence scores that rank and preserve samples within a sequence priority buffer. Samples with higher scores are more frequently selected for training. TinyDrive is first evaluated on our custom-curated VQA dataset, and it is subsequently tested on the public DriveLM benchmark, where it achieves state-of-the-art language understanding performance. Notably, it achieves relative improvements of 11.1% and 35.4% in BLEU-4 and METEOR scores, respectively, despite having a significantly smaller parameter count.
TS-VLM: Text-Guided SoftSort Pooling for Vision-Language Models in Multi-View Driving Reasoning
May 19, 2025Vision-Language Models (VLMs) have shown remarkable potential in advancing autonomous driving by leveraging multi-modal fusion in order to enhance scene perception, reasoning, and decision-making. Despite their potential, existing models suffer from computational overhead and inefficient integration of multi-view sensor data that make them impractical for real-time deployment in safety-critical autonomous driving applications. To address these shortcomings, this paper is devoted to designing a lightweight VLM called TS-VLM, which incorporates a novel Text-Guided SoftSort Pooling (TGSSP) module. By resorting to semantics of the input queries, TGSSP ranks and fuses visual features from multiple views, enabling dynamic and query-aware multi-view aggregation without reliance on costly attention mechanisms. This design ensures the query-adaptive prioritization of semantically related views, which leads to improved contextual accuracy in multi-view reasoning for autonomous driving. Extensive evaluations on the DriveLM benchmark demonstrate that, on the one hand, TS-VLM outperforms state-of-the-art models with a BLEU-4 score of 56.82, METEOR of 41.91, ROUGE-L of 74.64, and CIDEr of 3.39. On the other hand, TS-VLM reduces computational cost by up to 90%, where the smallest version contains only 20.1 million parameters, making it more practical for real-time deployment in autonomous vehicles.
Pruning-Based TinyML Optimization of Machine Learning Models for Anomaly Detection in Electric Vehicle Charging Infrastructure
Mar 19, 2025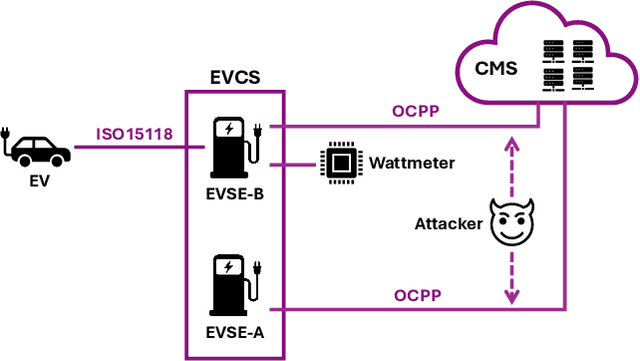
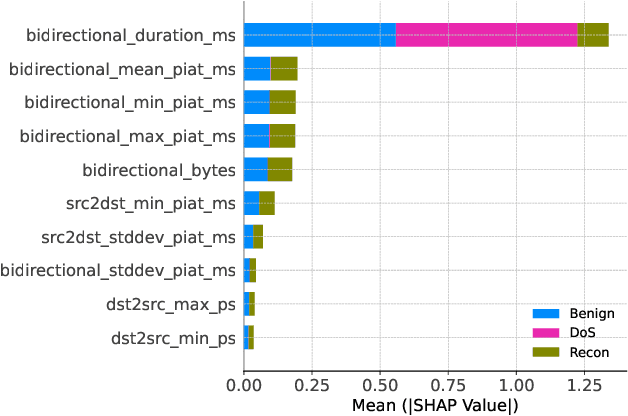
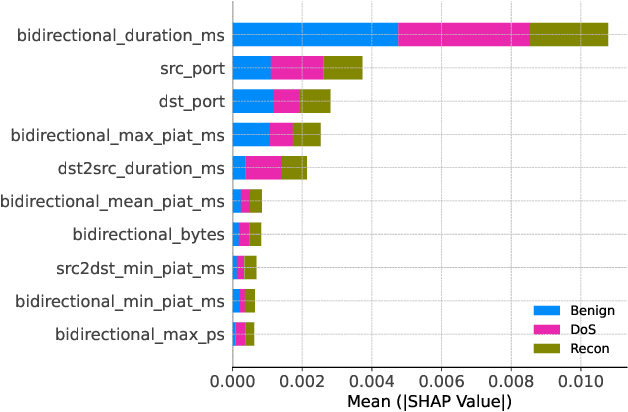
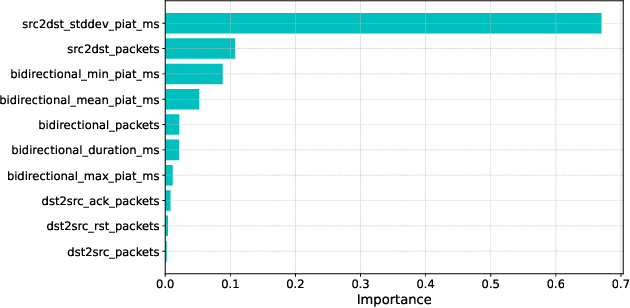
With the growing need for real-time processing on IoT devices, optimizing machine learning (ML) models' size, latency, and computational efficiency is essential. This paper investigates a pruning method for anomaly detection in resource-constrained environments, specifically targeting Electric Vehicle Charging Infrastructure (EVCI). Using the CICEVSE2024 dataset, we trained and optimized three models-Multi-Layer Perceptron (MLP), Long Short-Term Memory (LSTM), and XGBoost-through hyperparameter tuning with Optuna, further refining them using SHapley Additive exPlanations (SHAP)-based feature selection (FS) and unstructured pruning techniques. The optimized models achieved significant reductions in model size and inference times, with only a marginal impact on their performance. Notably, our findings indicate that, in the context of EVCI, pruning and FS can enhance computational efficiency while retaining critical anomaly detection capabilities.
Efficient Transformer-based Hyper-parameter Optimization for Resource-constrained IoT Environments
Mar 18, 2024



The hyper-parameter optimization (HPO) process is imperative for finding the best-performing Convolutional Neural Networks (CNNs). The automation process of HPO is characterized by its sizable computational footprint and its lack of transparency; both important factors in a resource-constrained Internet of Things (IoT) environment. In this paper, we address these problems by proposing a novel approach that combines transformer architecture and actor-critic Reinforcement Learning (RL) model, TRL-HPO, equipped with multi-headed attention that enables parallelization and progressive generation of layers. These assumptions are founded empirically by evaluating TRL-HPO on the MNIST dataset and comparing it with state-of-the-art approaches that build CNN models from scratch. The results show that TRL-HPO outperforms the classification results of these approaches by 6.8% within the same time frame, demonstrating the efficiency of TRL-HPO for the HPO process. The analysis of the results identifies the main culprit for performance degradation attributed to stacking fully connected layers. This paper identifies new avenues for improving RL-based HPO processes in resource-constrained environments.
Robust Multiview Multimodal Driver Monitoring System Using Masked Multi-Head Self-Attention
Apr 13, 2023Driver Monitoring Systems (DMSs) are crucial for safe hand-over actions in Level-2+ self-driving vehicles. State-of-the-art DMSs leverage multiple sensors mounted at different locations to monitor the driver and the vehicle's interior scene and employ decision-level fusion to integrate these heterogenous data. However, this fusion method may not fully utilize the complementarity of different data sources and may overlook their relative importance. To address these limitations, we propose a novel multiview multimodal driver monitoring system based on feature-level fusion through multi-head self-attention (MHSA). We demonstrate its effectiveness by comparing it against four alternative fusion strategies (Sum, Conv, SE, and AFF). We also present a novel GPU-friendly supervised contrastive learning framework SuMoCo to learn better representations. Furthermore, We fine-grained the test split of the DAD dataset to enable the multi-class recognition of drivers' activities. Experiments on this enhanced database demonstrate that 1) the proposed MHSA-based fusion method (AUC-ROC: 97.0\%) outperforms all baselines and previous approaches, and 2) training MHSA with patch masking can improve its robustness against modality/view collapses. The code and annotations are publicly available.
Real-Time Driver Monitoring Systems through Modality and View Analysis
Oct 17, 2022

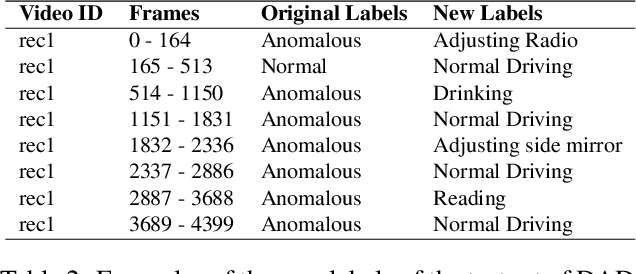
Driver distractions are known to be the dominant cause of road accidents. While monitoring systems can detect non-driving-related activities and facilitate reducing the risks, they must be accurate and efficient to be applicable. Unfortunately, state-of-the-art methods prioritize accuracy while ignoring latency because they leverage cross-view and multimodal videos in which consecutive frames are highly similar. Thus, in this paper, we pursue time-effective detection models by neglecting the temporal relation between video frames and investigate the importance of each sensing modality in detecting drives' activities. Experiments demonstrate that 1) our proposed algorithms are real-time and can achieve similar performances (97.5\% AUC-PR) with significantly reduced computation compared with video-based models; 2) the top view with the infrared channel is more informative than any other single modality. Furthermore, we enhance the DAD dataset by manually annotating its test set to enable multiclassification. We also thoroughly analyze the influence of visual sensor types and their placements on the prediction of each class. The code and the new labels will be released.