 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSocInt: A Multi-modal Training Environment for Human-Aware Social Navigation
Jan 05, 2026In this paper, we introduce OpenSocInt, an open-source software package providing a simulator for multi-modal social interactions and a modular architecture to train social agents. We described the software package and showcased its interest via an experimental protocol based on the task of social navigation. Our framework allows for exploring the use of different perceptual features, their encoding and fusion, as well as the use of different agents. The software is already publicly available under GPL at https://gitlab.inria.fr/robotlearn/OpenSocInt/.
LLM-driven Indoor Scene Layout Generation via Scaled Human-aligned Data Synthesis and Multi-Stage Preference Optimization
Jun 09, 2025Automatic indoor layout generation has attracted increasing attention due to its potential in interior design, virtual environment construction, and embodied AI. Existing methods fall into two categories: prompt-driven approaches that leverage proprietary LLM services (e.g., GPT APIs) and learning-based methods trained on layout data upon diffusion-based models. Prompt-driven methods often suffer from spatial inconsistency and high computational costs, while learning-based methods are typically constrained by coarse relational graphs and limited datasets, restricting their generalization to diverse room categories. In this paper, we revisit LLM-based indoor layout generation and present 3D-SynthPlace, a large-scale dataset that combines synthetic layouts generated via a 'GPT synthesize, Human inspect' pipeline, upgraded from the 3D-Front dataset. 3D-SynthPlace contains nearly 17,000 scenes, covering four common room types -- bedroom, living room, kitchen, and bathroom -- enriched with diverse objects and high-level spatial annotations. We further introduce OptiScene, a strong open-source LLM optimized for indoor layout generation, fine-tuned based on our 3D-SynthPlace dataset through our two-stage training. For the warum-up stage I, we adopt supervised fine-tuning (SFT), which is taught to first generate high-level spatial descriptions then conditionally predict concrete object placements. For the reinforcing stage II, to better align the generated layouts with human design preferences, we apply multi-turn direct preference optimization (DPO), which significantly improving layout quality and generation success rates. Extensive experiments demonstrate that OptiScene outperforms traditional prompt-driven and learning-based baselines. Moreover, OptiScene shows promising potential in interactive tasks such as scene editing and robot navigation.
Advancing Video Anomaly Detection: A Bi-Directional Hybrid Framework for Enhanced Single- and Multi-Task Approaches
Apr 20, 2025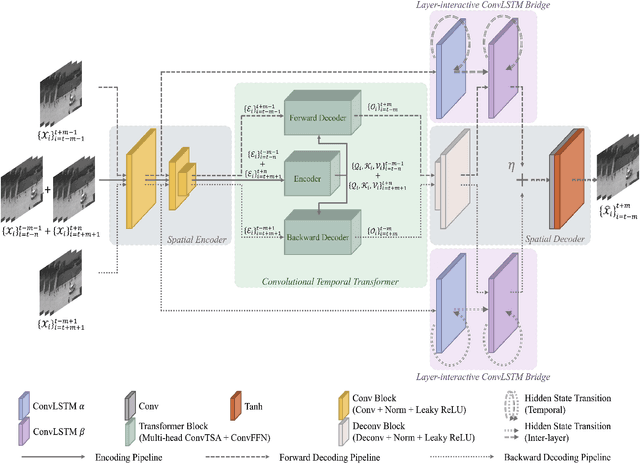
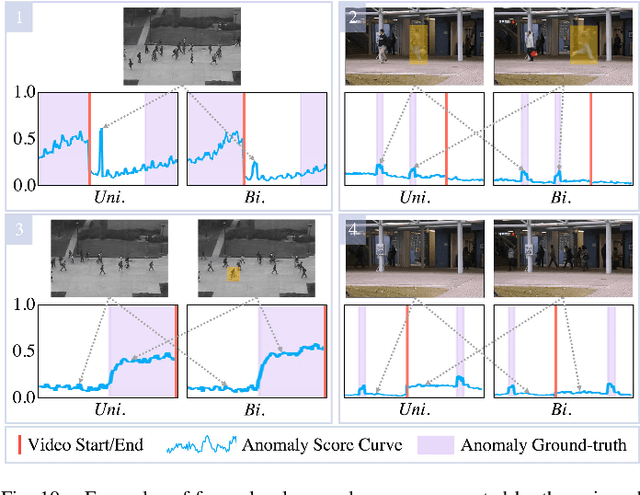
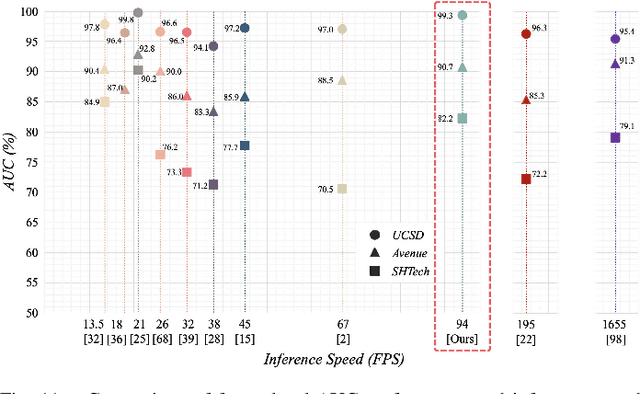
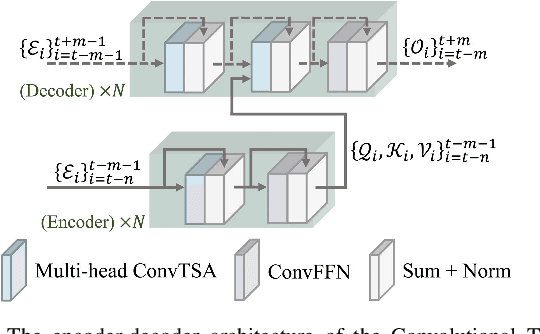
Despite the prevailing transition from single-task to multi-task approaches in video anomaly detection, we observe that many adopt sub-optimal frameworks for individual proxy tasks. Motivated by this, we contend that optimizing single-task frameworks can advance both single- and multi-task approaches. Accordingly, we leverage middle-frame prediction as the primary proxy task, and introduce an effective hybrid framework designed to generate accurate predictions for normal frames and flawed predictions for abnormal frames. This hybrid framework is built upon a bi-directional structure that seamlessly integrates both vision transformers and ConvLSTMs. Specifically, we utilize this bi-directional structure to fully analyze the temporal dimension by predicting frames in both forward and backward directions, significantly boosting the detection stability. Given the transformer's capacity to model long-range contextual dependencies, we develop a convolutional temporal transformer that efficiently associates feature maps from all context frames to generate attention-based predictions for target frames. Furthermore, we devise a layer-interactive ConvLSTM bridge that facilitates the smooth flow of low-level features across layers and time-steps, thereby strengthening predictions with fine details. Anomalies are eventually identified by scrutinizing the discrepancies between target frames and their corresponding predictions. Several experiments conducted on public benchmarks affirm the efficacy of our hybrid framework, whether used as a standalone single-task approach or integrated as a branch in a multi-task approach. These experiments also underscore the advantages of merging vision transformers and ConvLSTMs for video anomaly detection.
* Accepted by IEEE Transactions on Image Processing (TIP)
RefComp: A Reference-guided Unified Framework for Unpaired Point Cloud Completion
Apr 18, 2025The unpaired point cloud completion task aims to complete a partial point cloud by using models trained with no ground truth. Existing unpaired point cloud completion methods are class-aware, i.e., a separate model is needed for each object class. Since they have limited generalization capabilities, these methods perform poorly in real-world scenarios when confronted with a wide range of point clouds of generic 3D objects. In this paper, we propose a novel unpaired point cloud completion framework, namely the Reference-guided Completion (RefComp) framework, which attains strong performance in both the class-aware and class-agnostic training settings. The RefComp framework transforms the unpaired completion problem into a shape translation problem, which is solved in the latent feature space of the partial point clouds. To this end, we introduce the use of partial-complete point cloud pairs, which are retrieved by using the partial point cloud to be completed as a template. These point cloud pairs are used as reference data to guide the completion process. Our RefComp framework uses a reference branch and a target branch with shared parameters for shape fusion and shape translation via a Latent Shape Fusion Module (LSFM) to enhance the structural features along the completion pipeline. Extensive experiments demonstrate that the RefComp framework achieves not only state-of-the-art performance in the class-aware training setting but also competitive results in the class-agnostic training setting on both virtual scans and real-world datasets.
DiffFake: Exposing Deepfakes using Differential Anomaly Detection
Feb 22, 2025


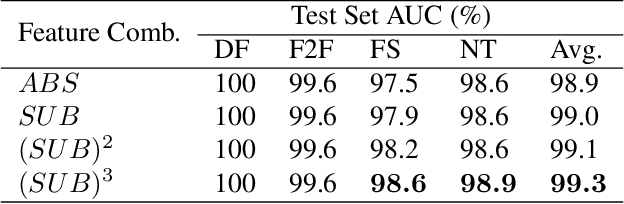
Traditional deepfake detectors have dealt with the detection problem as a binary classification task. This approach can achieve satisfactory results in cases where samples of a given deepfake generation technique have been seen during training, but can easily fail with deepfakes generated by other techniques. In this paper, we propose DiffFake, a novel deepfake detector that approaches the detection problem as an anomaly detection task. Specifically, DiffFake learns natural changes that occur between two facial images of the same person by leveraging a differential anomaly detection framework. This is done by combining pairs of deep face embeddings and using them to train an anomaly detection model. We further propose to train a feature extractor on pseudo-deepfakes with global and local artifacts, to extract meaningful and generalizable features that can then be used to train the anomaly detection model. We perform extensive experiments on five different deepfake datasets and show that our method can match and sometimes even exceed the performance of state-of-the-art competitors.
From Age Estimation to Age-Invariant Face Recognition: Generalized Age Feature Extraction Using Order-Enhanced Contrastive Learning
Jan 03, 2025



Generalized age feature extraction is crucial for age-related facial analysis tasks, such as age estimation and age-invariant face recognition (AIFR). Despite the recent successes of models in homogeneous-dataset experiments, their performance drops significantly in cross-dataset evaluations. Most of these models fail to extract generalized age features as they only attempt to map extracted features with training age labels directly without explicitly modeling the natural progression of aging. In this paper, we propose Order-Enhanced Contrastive Learning (OrdCon), which aims to extract generalized age features to minimize the domain gap across different datasets and scenarios. OrdCon aligns the direction vector of two features with either the natural aging direction or its reverse to effectively model the aging process. The method also leverages metric learning which is incorporated with a novel soft proxy matching loss to ensure that features are positioned around the center of each age cluster with minimum intra-class variance. We demonstrate that our proposed method achieves comparable results to state-of-the-art methods on various benchmark datasets in homogeneous-dataset evaluations for both age estimation and AIFR. In cross-dataset experiments, our method reduces the mean absolute error by about 1.38 in average for age estimation task and boosts the average accuracy for AIFR by 1.87%.
Interact with me: Joint Egocentric Forecasting of Intent to Interact, Attitude and Social Actions
Dec 21, 2024



For efficient human-agent interaction, an agent should proactively recognize their target user and prepare for upcoming interactions. We formulate this challenging problem as the novel task of jointly forecasting a person's intent to interact with the agent, their attitude towards the agent and the action they will perform, from the agent's (egocentric) perspective. So we propose \emph{SocialEgoNet} - a graph-based spatiotemporal framework that exploits task dependencies through a hierarchical multitask learning approach. SocialEgoNet uses whole-body skeletons (keypoints from face, hands and body) extracted from only 1 second of video input for high inference speed. For evaluation, we augment an existing egocentric human-agent interaction dataset with new class labels and bounding box annotations. Extensive experiments on this augmented dataset, named JPL-Social, demonstrate \emph{real-time} inference and superior performance (average accuracy across all tasks: 83.15\%) of our model outperforming several competitive baselines. The additional annotations and code will be available upon acceptance.
Enhanced Prototypical Part Network (EPPNet) For Explainable Image Classification Via Prototypes
Aug 08, 2024Explainable Artificial Intelligence (xAI) has the potential to enhance the transparency and trust of AI-based systems. Although accurate predictions can be made using Deep Neural Networks (DNNs), the process used to arrive at such predictions is usually hard to explain. In terms of perceptibly human-friendly representations, such as word phrases in text or super-pixels in images, prototype-based explanations can justify a model's decision. In this work, we introduce a DNN architecture for image classification, the Enhanced Prototypical Part Network (EPPNet), which achieves strong performance while discovering relevant prototypes that can be used to explain the classification results. This is achieved by introducing a novel cluster loss that helps to discover more relevant human-understandable prototypes. We also introduce a faithfulness score to evaluate the explainability of the results based on the discovered prototypes. Our score not only accounts for the relevance of the learned prototypes but also the performance of a model. Our evaluations on the CUB-200-2011 dataset show that the EPPNet outperforms state-of-the-art xAI-based methods, in terms of both classification accuracy and explainability
LLplace: The 3D Indoor Scene Layout Generation and Editing via Large Language Model
Jun 06, 2024



Designing 3D indoor layouts is a crucial task with significant applications in virtual reality, interior design, and automated space planning. Existing methods for 3D layout design either rely on diffusion models, which utilize spatial relationship priors, or heavily leverage the inferential capabilities of proprietary Large Language Models (LLMs), which require extensive prompt engineering and in-context exemplars via black-box trials. These methods often face limitations in generalization and dynamic scene editing. In this paper, we introduce LLplace, a novel 3D indoor scene layout designer based on lightweight fine-tuned open-source LLM Llama3. LLplace circumvents the need for spatial relationship priors and in-context exemplars, enabling efficient and credible room layout generation based solely on user inputs specifying the room type and desired objects. We curated a new dialogue dataset based on the 3D-Front dataset, expanding the original data volume and incorporating dialogue data for adding and removing objects. This dataset can enhance the LLM's spatial understanding. Furthermore, through dialogue, LLplace activates the LLM's capability to understand 3D layouts and perform dynamic scene editing, enabling the addition and removal of objects. Our approach demonstrates that LLplace can effectively generate and edit 3D indoor layouts interactively and outperform existing methods in delivering high-quality 3D design solutions. Code and dataset will be released.
WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting
May 01, 2024We introduce WorkBench: a benchmark dataset for evaluating agents' ability to execute tasks in a workplace setting. WorkBench contains a sandbox environment with five databases, 26 tools, and 690 tasks. These tasks represent common business activities, such as sending emails and scheduling meetings. The tasks in WorkBench are challenging as they require planning, tool selection, and often multiple actions. If a task has been successfully executed, one (or more) of the database values may change. The correct outcome for each task is unique and unambiguous, which allows for robust, automated evaluation. We call this key contribution outcome-centric evaluation. We evaluate five existing ReAct agents on WorkBench, finding they successfully complete as few as 3% of tasks (Llama2-70B), and just 43% for the best-performing (GPT-4). We further find that agents' errors can result in the wrong action being taken, such as an email being sent to the wrong person. WorkBench reveals weaknesses in agents' ability to undertake common business activities, raising questions about their use in high-stakes workplace settings. WorkBench is publicly available as a free resource at https://github.com/olly-styles/WorkBench.