 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Prototypical Part Network (EPPNet) For Explainable Image Classification Via Prototypes
Aug 08, 2024Explainable Artificial Intelligence (xAI) has the potential to enhance the transparency and trust of AI-based systems. Although accurate predictions can be made using Deep Neural Networks (DNNs), the process used to arrive at such predictions is usually hard to explain. In terms of perceptibly human-friendly representations, such as word phrases in text or super-pixels in images, prototype-based explanations can justify a model's decision. In this work, we introduce a DNN architecture for image classification, the Enhanced Prototypical Part Network (EPPNet), which achieves strong performance while discovering relevant prototypes that can be used to explain the classification results. This is achieved by introducing a novel cluster loss that helps to discover more relevant human-understandable prototypes. We also introduce a faithfulness score to evaluate the explainability of the results based on the discovered prototypes. Our score not only accounts for the relevance of the learned prototypes but also the performance of a model. Our evaluations on the CUB-200-2011 dataset show that the EPPNet outperforms state-of-the-art xAI-based methods, in terms of both classification accuracy and explainability
Robust Multiview Multimodal Driver Monitoring System Using Masked Multi-Head Self-Attention
Apr 13, 2023Driver Monitoring Systems (DMSs) are crucial for safe hand-over actions in Level-2+ self-driving vehicles. State-of-the-art DMSs leverage multiple sensors mounted at different locations to monitor the driver and the vehicle's interior scene and employ decision-level fusion to integrate these heterogenous data. However, this fusion method may not fully utilize the complementarity of different data sources and may overlook their relative importance. To address these limitations, we propose a novel multiview multimodal driver monitoring system based on feature-level fusion through multi-head self-attention (MHSA). We demonstrate its effectiveness by comparing it against four alternative fusion strategies (Sum, Conv, SE, and AFF). We also present a novel GPU-friendly supervised contrastive learning framework SuMoCo to learn better representations. Furthermore, We fine-grained the test split of the DAD dataset to enable the multi-class recognition of drivers' activities. Experiments on this enhanced database demonstrate that 1) the proposed MHSA-based fusion method (AUC-ROC: 97.0\%) outperforms all baselines and previous approaches, and 2) training MHSA with patch masking can improve its robustness against modality/view collapses. The code and annotations are publicly available.
Real-Time Driver Monitoring Systems through Modality and View Analysis
Oct 17, 2022

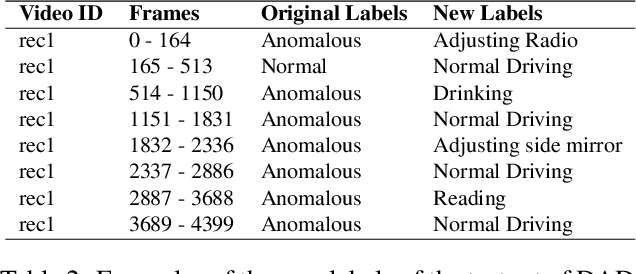
Driver distractions are known to be the dominant cause of road accidents. While monitoring systems can detect non-driving-related activities and facilitate reducing the risks, they must be accurate and efficient to be applicable. Unfortunately, state-of-the-art methods prioritize accuracy while ignoring latency because they leverage cross-view and multimodal videos in which consecutive frames are highly similar. Thus, in this paper, we pursue time-effective detection models by neglecting the temporal relation between video frames and investigate the importance of each sensing modality in detecting drives' activities. Experiments demonstrate that 1) our proposed algorithms are real-time and can achieve similar performances (97.5\% AUC-PR) with significantly reduced computation compared with video-based models; 2) the top view with the infrared channel is more informative than any other single modality. Furthermore, we enhance the DAD dataset by manually annotating its test set to enable multiclassification. We also thoroughly analyze the influence of visual sensor types and their placements on the prediction of each class. The code and the new labels will be released.