 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNüshuVoice: Reviving the Voice of Endangered Nüshu with Pitch-Aware Text-to-Speech
Jun 08, 2026Nüshu is an endangered phonetic script historically used by women in Jiangyong County, southern Hunan, China. While existing computational studies of Nüshu mainly focus on textual digitization and visual recognition, the acoustic reconstruction of its authentic pronunciation remains largely unexplored. Building a Nüshu text-to-speech (TTS) system is particularly challenging because available recordings are extremely limited and mostly consist of isolated syllable-level pronunciations rather than natural sentence-level utterances. In this work, we introduce NüshuVoice, the first TTS benchmark for Nüshu. We construct a sentence-level Nüshu text-to-audio dataset that aligns standardized Unicode Nüshu text, phonetic transcriptions, standard Chinese translations, and archival recordings. To synthesize speech under this extreme low-resource setting, we propose Nüshu-PitchVITS, an F0-conditioned VITS framework that leverages Nüshu's five-level pitch notation as an explicit prosodic inductive bias. Experimental results show that Nüshu-PitchVITS outperforms strong TTS baselines in spectral fidelity, pitch reconstruction, and human-rated intelligibility. We publicly release the dataset and code at: https://anonymous.4open.science/r/Nvshu-TTS-2EB6.
Robust OT-Guided Generative Residual Domain Adaptation for Bike-Sharing Demand Prediction under Temporal Domain Shift
May 22, 2026Bike-sharing models trained on historical station-hour data may degrade when deployed in later years because travel patterns change over time. This paper studies March Citi Bike demand prediction from 2021 to 2026 as a temporal domain adaptation problem and proposes Gen-ROTDA, a robust optimal transport-guided residual domain adaptation framework. The method fits a target-domain station-time anchor with a small labeled target subset, transfers residual rather than raw demand, applies a deterministic label-preserving residual feature generator, and trims high-cost transport matches before training the final residual predictor. Experiments compare Gen-ROTDA with anchor-only, source-only, target-only, fine-tuning, MMD adaptation, Sinkhorn OTDA, ROTDA, and Gen-OTDA. Gen-ROTDA achieves the lowest MAE on the main 2025 to 2026 task and is the best OT-family method on average across multi-year tasks, although fine-tuning and MMD adaptation remain strong overall baselines. Under abnormal target-unlabeled records, Gen-ROTDA is much more stable than non-robust OT variants, suggesting that robust transport is useful for noisy temporal transfer in bike-sharing demand prediction.
DeAR: Fine-Grained VLM Adaptation by Decomposing Attention Head Roles
Mar 01, 2026Prompt learning is a dominant paradigm for adapting pre-trained Vision-Language Models (VLMs) to downstream tasks. However, existing methods often rely on a simplistic, layer-centric view, assuming shallow layers capture general features while deep layers handle task-specific knowledge. This assumption results in uncontrolled interactions between learnable tokens and original tokens. Task-specific knowledge could degrades the model's core generalization and creates a trade-off between task adaptation and the preservation of zero-shot generalization. To address this, we challenge the layer-centric view and propose \textbf{DeAR}, a framework that achieves fine-grained VLM adaptation by \textbf{De}composing \textbf{A}ttention head \textbf{R}oles. We posit that the functional specialization within VLMs occurs not between layers, but at the finer-grained level of individual attention heads in the deeper layers. Based on this insight, we introduce a novel metric, Concept Entropy, to systematically classify attention heads into distinct functional roles: \textit{Attribute}, \textit{Generalization}, and \textit{Mixed}. Guided by these roles, we introduce specialized attribute tokens and a Role-Based Attention Mask mechanism to precisely control information flow, ensuring generalization heads remain isolated from task-specific knowledge. We further incorporate a Task-Adaptive Fusion Strategy for inference. Extensive experiments on fifteen datasets show that DeAR achieves a strong balance between task adaptation and generalization, outperforming previous methods across various tasks.
How Implicit Bias Accumulates and Propagates in LLM Long-term Memory
Feb 02, 2026Long-term memory mechanisms enable Large Language Models (LLMs) to maintain continuity and personalization across extended interaction lifecycles, but they also introduce new and underexplored risks related to fairness. In this work, we study how implicit bias, defined as subtle statistical prejudice, accumulates and propagates within LLMs equipped with long-term memory. To support systematic analysis, we introduce the Decision-based Implicit Bias (DIB) Benchmark, a large-scale dataset comprising 3,776 decision-making scenarios across nine social domains, designed to quantify implicit bias in long-term decision processes. Using a realistic long-horizon simulation framework, we evaluate six state-of-the-art LLMs integrated with three representative memory architectures on DIB and demonstrate that LLMs' implicit bias does not remain static but intensifies over time and propagates across unrelated domains. We further analyze mitigation strategies and show that a static system-level prompting baseline provides limited and short-lived debiasing effects. To address this limitation, we propose Dynamic Memory Tagging (DMT), an agentic intervention that enforces fairness constraints at memory write time. Extensive experimental results show that DMT substantially reduces bias accumulation and effectively curtails cross-domain bias propagation.
UniMPR: A Unified Framework for Multimodal Place Recognition with Heterogeneous Sensor Configurations
Dec 23, 2025Place recognition is a critical component of autonomous vehicles and robotics, enabling global localization in GPS-denied environments. Recent advances have spurred significant interest in multimodal place recognition (MPR), which leverages complementary strengths of multiple modalities. Despite its potential, most existing MPR methods still face three key challenges: (1) dynamically adapting to various modality inputs within a unified framework, (2) maintaining robustness with missing or degraded modalities, and (3) generalizing across diverse sensor configurations and setups. In this paper, we propose UniMPR, a unified framework for multimodal place recognition. Using only one trained model, it can seamlessly adapt to any combination of common perceptual modalities (e.g., camera, LiDAR, radar). To tackle the data heterogeneity, we unify all inputs within a polar BEV feature space. Subsequently, the polar BEVs are fed into a multi-branch network to exploit discriminative intra-model and inter-modal features from any modality combinations. To fully exploit the network's generalization capability and robustness, we construct a large-scale training set from multiple datasets and introduce an adaptive label assignment strategy for extensive pre-training. Experiments on seven datasets demonstrate that UniMPR achieves state-of-the-art performance under varying sensor configurations, modality combinations, and environmental conditions. Our code will be released at https://github.com/QiZS-BIT/UniMPR.
SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs
Nov 18, 2025Serving deep learning based recommendation models (DLRM) at scale is challenging. Existing systems rely on CPU-based ANN indexing and filtering services, suffering from non-negligible costs and forgoing joint optimization opportunities. Such inefficiency makes them difficult to support more complex model architectures, such as learned similarities and multi-task retrieval. In this paper, we propose SilverTorch, a model-based system for serving recommendation models on GPUs. SilverTorch unifies model serving by replacing standalone indexing and filtering services with layers of served models. We propose a Bloom index algorithm on GPUs for feature filtering and a tensor-native fused Int8 ANN kernel on GPUs for nearest neighbor search. We further co-design the ANN search index and filtering index to reduce GPU memory utilization and eliminate unnecessary computation. Benefit from SilverTorch's serving paradigm, we introduce a OverArch scoring layer and a Value Model to aggregate results across multi-tasks. These advancements improve the accuracy for retrieval and enable future studies for serving more complex models. For ranking, SilverTorch's design accelerates item embedding calculation by caching the pre-calculated embeddings inside the serving model. Our evaluation on the industry-scale datasets show that SilverTorch achieves up to 5.6x lower latency and 23.7x higher throughput compared to the state-of-the-art approaches. We also demonstrate that SilverTorch's solution is 13.35x more cost-efficient than CPU-based solution while improving accuracy via serving more complex models. SilverTorch serves over hundreds of models online across major products and recommends contents for billions of daily active users.
JiraiBench: A Bilingual Benchmark for Evaluating Large Language Models' Detection of Human Self-Destructive Behavior Content in Jirai Community
Mar 27, 2025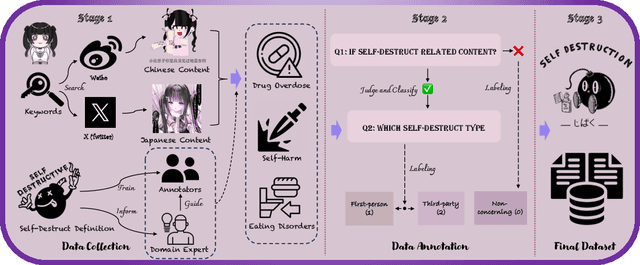
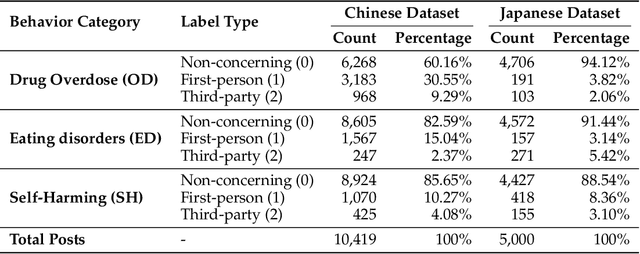


This paper introduces JiraiBench, the first bilingual benchmark for evaluating large language models' effectiveness in detecting self-destructive content across Chinese and Japanese social media communities. Focusing on the transnational "Jirai" (landmine) online subculture that encompasses multiple forms of self-destructive behaviors including drug overdose, eating disorders, and self-harm, we present a comprehensive evaluation framework incorporating both linguistic and cultural dimensions. Our dataset comprises 10,419 Chinese posts and 5,000 Japanese posts with multidimensional annotation along three behavioral categories, achieving substantial inter-annotator agreement. Experimental evaluations across four state-of-the-art models reveal significant performance variations based on instructional language, with Japanese prompts unexpectedly outperforming Chinese prompts when processing Chinese content. This emergent cross-cultural transfer suggests that cultural proximity can sometimes outweigh linguistic similarity in detection tasks. Cross-lingual transfer experiments with fine-tuned models further demonstrate the potential for knowledge transfer between these language systems without explicit target language training. These findings highlight the need for culturally-informed approaches to multilingual content moderation and provide empirical evidence for the importance of cultural context in developing more effective detection systems for vulnerable online communities.
Interact with me: Joint Egocentric Forecasting of Intent to Interact, Attitude and Social Actions
Dec 21, 2024



For efficient human-agent interaction, an agent should proactively recognize their target user and prepare for upcoming interactions. We formulate this challenging problem as the novel task of jointly forecasting a person's intent to interact with the agent, their attitude towards the agent and the action they will perform, from the agent's (egocentric) perspective. So we propose \emph{SocialEgoNet} - a graph-based spatiotemporal framework that exploits task dependencies through a hierarchical multitask learning approach. SocialEgoNet uses whole-body skeletons (keypoints from face, hands and body) extracted from only 1 second of video input for high inference speed. For evaluation, we augment an existing egocentric human-agent interaction dataset with new class labels and bounding box annotations. Extensive experiments on this augmented dataset, named JPL-Social, demonstrate \emph{real-time} inference and superior performance (average accuracy across all tasks: 83.15\%) of our model outperforming several competitive baselines. The additional annotations and code will be available upon acceptance.
ProteinWeaver: A Divide-and-Assembly Approach for Protein Backbone Design
Nov 08, 2024Nature creates diverse proteins through a `divide and assembly' strategy. Inspired by this idea, we introduce ProteinWeaver, a two-stage framework for protein backbone design. Our method first generates individual protein domains and then employs an SE(3) diffusion model to flexibly assemble these domains. A key challenge lies in the assembling step, given the complex and rugged nature of the inter-domain interaction landscape. To address this challenge, we employ preference alignment to discern complex relationships between structure and interaction landscapes through comparative analysis of generated samples. Comprehensive experiments demonstrate that ProteinWeaver: (1) generates high-quality, novel protein backbones through versatile domain assembly; (2) outperforms RFdiffusion, the current state-of-the-art in backbone design, by 13\% and 39\% for long-chain proteins; (3) shows the potential for cooperative function design through illustrative case studies. To sum up, by introducing a `divide-and-assembly' paradigm, ProteinWeaver advances protein engineering and opens new avenues for functional protein design.
ProteinBench: A Holistic Evaluation of Protein Foundation Models
Sep 10, 2024Recent years have witnessed a surge in the development of protein foundation models, significantly improving performance in protein prediction and generative tasks ranging from 3D structure prediction and protein design to conformational dynamics. However, the capabilities and limitations associated with these models remain poorly understood due to the absence of a unified evaluation framework. To fill this gap, we introduce ProteinBench, a holistic evaluation framework designed to enhance the transparency of protein foundation models. Our approach consists of three key components: (i) A taxonomic classification of tasks that broadly encompass the main challenges in the protein domain, based on the relationships between different protein modalities; (ii) A multi-metric evaluation approach that assesses performance across four key dimensions: quality, novelty, diversity, and robustness; and (iii) In-depth analyses from various user objectives, providing a holistic view of model performance. Our comprehensive evaluation of protein foundation models reveals several key findings that shed light on their current capabilities and limitations. To promote transparency and facilitate further research, we release the evaluation dataset, code, and a public leaderboard publicly for further analysis and a general modular toolkit. We intend for ProteinBench to be a living benchmark for establishing a standardized, in-depth evaluation framework for protein foundation models, driving their development and application while fostering collaboration within the field.