 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElucidating the Design Space of Multimodal Protein Language Models
Apr 16, 2025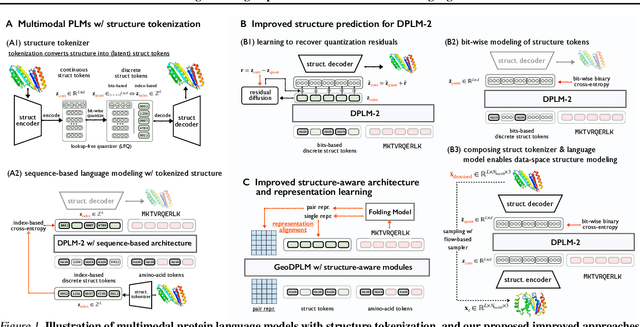
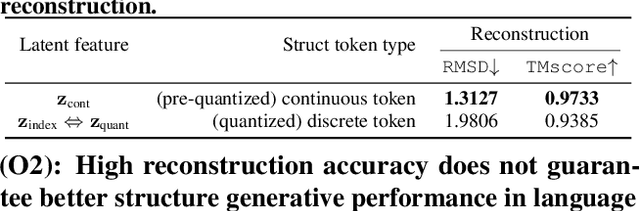
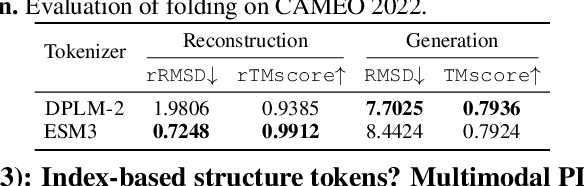
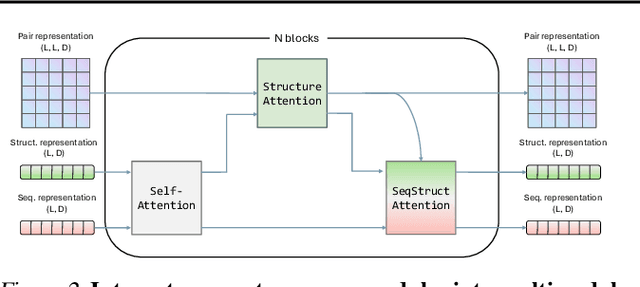
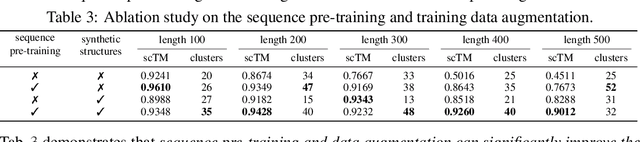
Multimodal protein language models (PLMs) integrate sequence and token-based structural information, serving as a powerful foundation for protein modeling, generation, and design. However, the reliance on tokenizing 3D structures into discrete tokens causes substantial loss of fidelity about fine-grained structural details and correlations. In this paper, we systematically elucidate the design space of multimodal PLMs to overcome their limitations. We identify tokenization loss and inaccurate structure token predictions by the PLMs as major bottlenecks. To address these, our proposed design space covers improved generative modeling, structure-aware architectures and representation learning, and data exploration. Our advancements approach finer-grained supervision, demonstrating that token-based multimodal PLMs can achieve robust structural modeling. The effective design methods dramatically improve the structure generation diversity, and notably, folding abilities of our 650M model by reducing the RMSD from 5.52 to 2.36 on PDB testset, even outperforming 3B baselines and on par with the specialized folding models.
DPLM-2: A Multimodal Diffusion Protein Language Model
Oct 17, 2024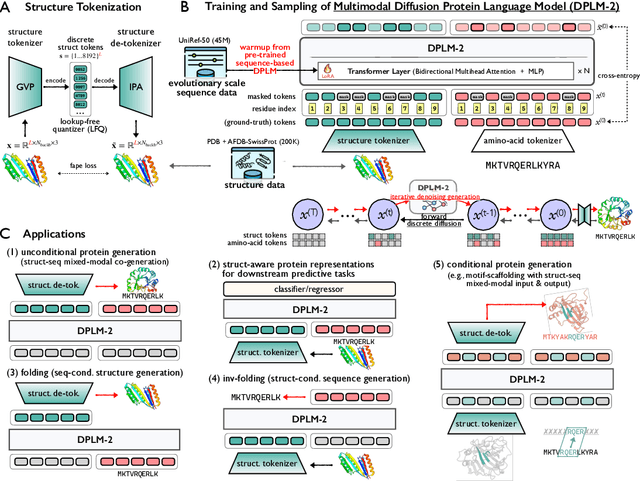
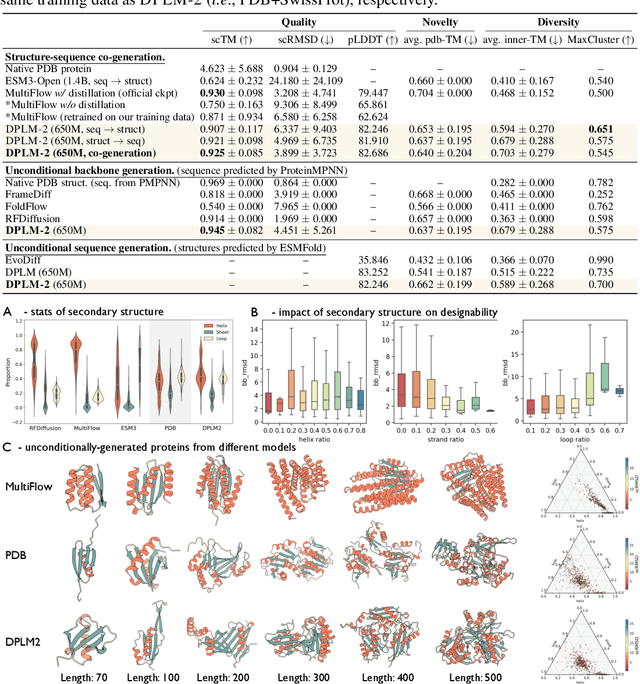
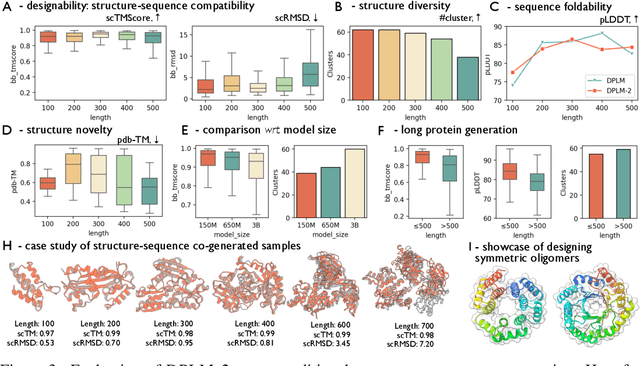
Proteins are essential macromolecules defined by their amino acid sequences, which determine their three-dimensional structures and, consequently, their functions in all living organisms. Therefore, generative protein modeling necessitates a multimodal approach to simultaneously model, understand, and generate both sequences and structures. However, existing methods typically use separate models for each modality, limiting their ability to capture the intricate relationships between sequence and structure. This results in suboptimal performance in tasks that requires joint understanding and generation of both modalities. In this paper, we introduce DPLM-2, a multimodal protein foundation model that extends discrete diffusion protein language model (DPLM) to accommodate both sequences and structures. To enable structural learning with the language model, 3D coordinates are converted to discrete tokens using a lookup-free quantization-based tokenizer. By training on both experimental and high-quality synthetic structures, DPLM-2 learns the joint distribution of sequence and structure, as well as their marginals and conditionals. We also implement an efficient warm-up strategy to exploit the connection between large-scale evolutionary data and structural inductive biases from pre-trained sequence-based protein language models. Empirical evaluation shows that DPLM-2 can simultaneously generate highly compatible amino acid sequences and their corresponding 3D structures eliminating the need for a two-stage generation approach. Moreover, DPLM-2 demonstrates competitive performance in various conditional generation tasks, including folding, inverse folding, and scaffolding with multimodal motif inputs, as well as providing structure-aware representations for predictive tasks.
ProteinBench: A Holistic Evaluation of Protein Foundation Models
Sep 10, 2024Recent years have witnessed a surge in the development of protein foundation models, significantly improving performance in protein prediction and generative tasks ranging from 3D structure prediction and protein design to conformational dynamics. However, the capabilities and limitations associated with these models remain poorly understood due to the absence of a unified evaluation framework. To fill this gap, we introduce ProteinBench, a holistic evaluation framework designed to enhance the transparency of protein foundation models. Our approach consists of three key components: (i) A taxonomic classification of tasks that broadly encompass the main challenges in the protein domain, based on the relationships between different protein modalities; (ii) A multi-metric evaluation approach that assesses performance across four key dimensions: quality, novelty, diversity, and robustness; and (iii) In-depth analyses from various user objectives, providing a holistic view of model performance. Our comprehensive evaluation of protein foundation models reveals several key findings that shed light on their current capabilities and limitations. To promote transparency and facilitate further research, we release the evaluation dataset, code, and a public leaderboard publicly for further analysis and a general modular toolkit. We intend for ProteinBench to be a living benchmark for establishing a standardized, in-depth evaluation framework for protein foundation models, driving their development and application while fostering collaboration within the field.
Diffusion Language Models Are Versatile Protein Learners
Feb 28, 2024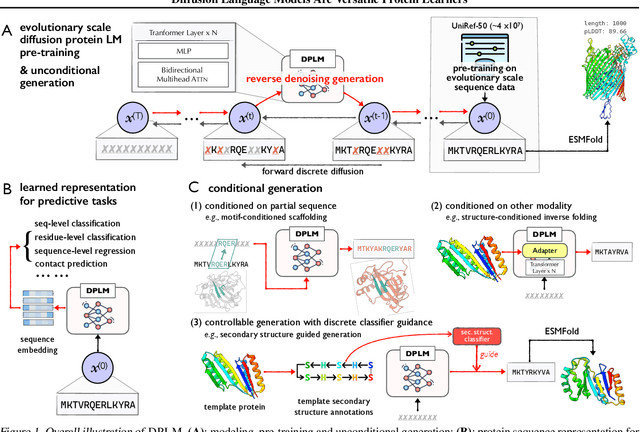
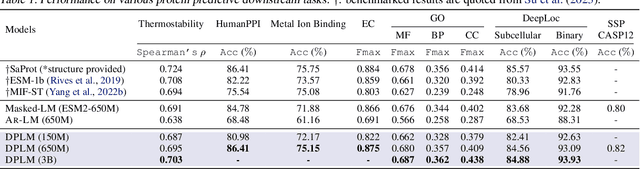
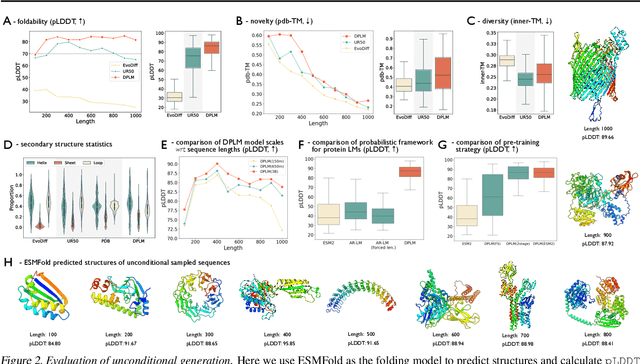
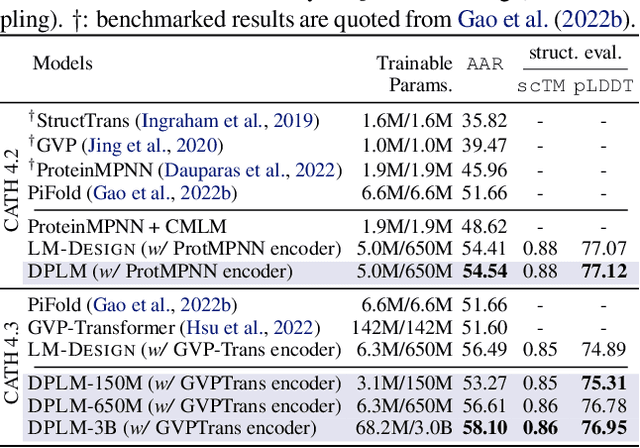
This paper introduces diffusion protein language model (DPLM), a versatile protein language model that demonstrates strong generative and predictive capabilities for protein sequences. We first pre-train scalable DPLMs from evolutionary-scale protein sequences within a generative self-supervised discrete diffusion probabilistic framework, which generalizes language modeling for proteins in a principled way. After pre-training, DPLM exhibits the ability to generate structurally plausible, novel, and diverse protein sequences for unconditional generation. We further demonstrate the proposed diffusion generative pre-training makes DPLM possess a better understanding of proteins, making it a superior representation learner, which can be fine-tuned for various predictive tasks, comparing favorably to ESM2 (Lin et al., 2022). Moreover, DPLM can be tailored for various needs, which showcases its prowess of conditional generation in several ways: (1) conditioning on partial peptide sequences, e.g., generating scaffolds for functional motifs with high success rate; (2) incorporating other modalities as conditioner, e.g., structure-conditioned generation for inverse folding; and (3) steering sequence generation towards desired properties, e.g., satisfying specified secondary structures, through a plug-and-play classifier guidance.
Helping the Weak Makes You Strong: Simple Multi-Task Learning Improves Non-Autoregressive Translators
Nov 11, 2022

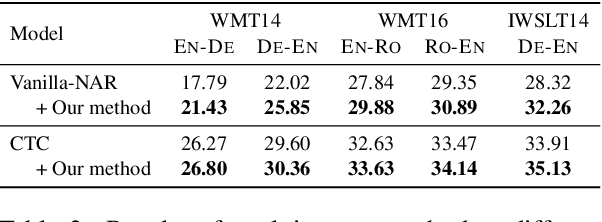

Recently, non-autoregressive (NAR) neural machine translation models have received increasing attention due to their efficient parallel decoding. However, the probabilistic framework of NAR models necessitates conditional independence assumption on target sequences, falling short of characterizing human language data. This drawback results in less informative learning signals for NAR models under conventional MLE training, thereby yielding unsatisfactory accuracy compared to their autoregressive (AR) counterparts. In this paper, we propose a simple and model-agnostic multi-task learning framework to provide more informative learning signals. During training stage, we introduce a set of sufficiently weak AR decoders that solely rely on the information provided by NAR decoder to make prediction, forcing the NAR decoder to become stronger or else it will be unable to support its weak AR partners. Experiments on WMT and IWSLT datasets show that our approach can consistently improve accuracy of multiple NAR baselines without adding any additional decoding overhead.