 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Modeling of Protein Conformation and Dynamics via Autoregression
May 23, 2025Understanding protein dynamics is critical for elucidating their biological functions. The increasing availability of molecular dynamics (MD) data enables the training of deep generative models to efficiently explore the conformational space of proteins. However, existing approaches either fail to explicitly capture the temporal dependencies between conformations or do not support direct generation of time-independent samples. To address these limitations, we introduce ConfRover, an autoregressive model that simultaneously learns protein conformation and dynamics from MD trajectories, supporting both time-dependent and time-independent sampling. At the core of our model is a modular architecture comprising: (i) an encoding layer, adapted from protein folding models, that embeds protein-specific information and conformation at each time frame into a latent space; (ii) a temporal module, a sequence model that captures conformational dynamics across frames; and (iii) an SE(3) diffusion model as the structure decoder, generating conformations in continuous space. Experiments on ATLAS, a large-scale protein MD dataset of diverse structures, demonstrate the effectiveness of our model in learning conformational dynamics and supporting a wide range of downstream tasks. ConfRover is the first model to sample both protein conformations and trajectories within a single framework, offering a novel and flexible approach for learning from protein MD data.
Click-Calib: A Robust Extrinsic Calibration Method for Surround-View Systems
Jan 02, 2025Surround-View System (SVS) is an essential component in Advanced Driver Assistance System (ADAS) and requires precise calibrations. However, conventional offline extrinsic calibration methods are cumbersome and time-consuming as they rely heavily on physical patterns. Additionally, these methods primarily focus on short-range areas surrounding the vehicle, resulting in lower calibration quality in more distant zones. To address these limitations, we propose Click-Calib, a pattern-free approach for offline SVS extrinsic calibration. Without requiring any special setup, the user only needs to click a few keypoints on the ground in natural scenes. Unlike other offline calibration approaches, Click-Calib optimizes camera poses over a wide range by minimizing reprojection distance errors of keypoints, thereby achieving accurate calibrations at both short and long distances. Furthermore, Click-Calib supports both single-frame and multiple-frame modes, with the latter offering even better results. Evaluations on our in-house dataset and the public WoodScape dataset demonstrate its superior accuracy and robustness compared to baseline methods. Code is avalaible at https://github.com/lwangvaleo/click_calib.
ProteinBench: A Holistic Evaluation of Protein Foundation Models
Sep 10, 2024Recent years have witnessed a surge in the development of protein foundation models, significantly improving performance in protein prediction and generative tasks ranging from 3D structure prediction and protein design to conformational dynamics. However, the capabilities and limitations associated with these models remain poorly understood due to the absence of a unified evaluation framework. To fill this gap, we introduce ProteinBench, a holistic evaluation framework designed to enhance the transparency of protein foundation models. Our approach consists of three key components: (i) A taxonomic classification of tasks that broadly encompass the main challenges in the protein domain, based on the relationships between different protein modalities; (ii) A multi-metric evaluation approach that assesses performance across four key dimensions: quality, novelty, diversity, and robustness; and (iii) In-depth analyses from various user objectives, providing a holistic view of model performance. Our comprehensive evaluation of protein foundation models reveals several key findings that shed light on their current capabilities and limitations. To promote transparency and facilitate further research, we release the evaluation dataset, code, and a public leaderboard publicly for further analysis and a general modular toolkit. We intend for ProteinBench to be a living benchmark for establishing a standardized, in-depth evaluation framework for protein foundation models, driving their development and application while fostering collaboration within the field.
Enhanced Parking Perception by Multi-Task Fisheye Cross-view Transformers
Aug 22, 2024Current parking area perception algorithms primarily focus on detecting vacant slots within a limited range, relying on error-prone homographic projection for both labeling and inference. However, recent advancements in Advanced Driver Assistance System (ADAS) require interaction with end-users through comprehensive and intelligent Human-Machine Interfaces (HMIs). These interfaces should present a complete perception of the parking area going from distinguishing vacant slots' entry lines to the orientation of other parked vehicles. This paper introduces Multi-Task Fisheye Cross View Transformers (MT F-CVT), which leverages features from a four-camera fisheye Surround-view Camera System (SVCS) with multihead attentions to create a detailed Bird-Eye View (BEV) grid feature map. Features are processed by both a segmentation decoder and a Polygon-Yolo based object detection decoder for parking slots and vehicles. Trained on data labeled using LiDAR, MT F-CVT positions objects within a 25m x 25m real open-road scenes with an average error of only 20 cm. Our larger model achieves an F-1 score of 0.89. Moreover the smaller model operates at 16 fps on an Nvidia Jetson Orin embedded board, with similar detection results to the larger one. MT F-CVT demonstrates robust generalization capability across different vehicles and camera rig configurations. A demo video from an unseen vehicle and camera rig is available at: https://streamable.com/jjw54x.
Autaptic Synaptic Circuit Enhances Spatio-temporal Predictive Learning of Spiking Neural Networks
Jun 01, 2024Spiking Neural Networks (SNNs) emulate the integrated-fire-leak mechanism found in biological neurons, offering a compelling combination of biological realism and energy efficiency. In recent years, they have gained considerable research interest. However, existing SNNs predominantly rely on the Leaky Integrate-and-Fire (LIF) model and are primarily suited for simple, static tasks. They lack the ability to effectively model long-term temporal dependencies and facilitate spatial information interaction, which is crucial for tackling complex, dynamic spatio-temporal prediction tasks. To tackle these challenges, this paper draws inspiration from the concept of autaptic synapses in biology and proposes a novel Spatio-Temporal Circuit (STC) model. The STC model integrates two learnable adaptive pathways, enhancing the spiking neurons' temporal memory and spatial coordination. We conduct a theoretical analysis of the dynamic parameters in the STC model, highlighting their contribution in establishing long-term memory and mitigating the issue of gradient vanishing. Through extensive experiments on multiple spatio-temporal prediction datasets, we demonstrate that our model outperforms other adaptive models. Furthermore, our model is compatible with existing spiking neuron models, thereby augmenting their dynamic representations. In essence, our work enriches the specificity and topological complexity of SNNs.
Protein Conformation Generation via Force-Guided SE(3) Diffusion Models
Mar 21, 2024
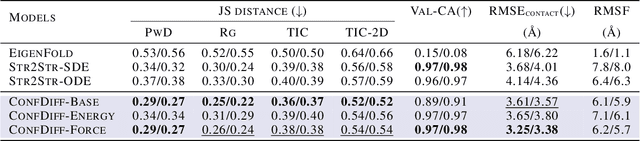
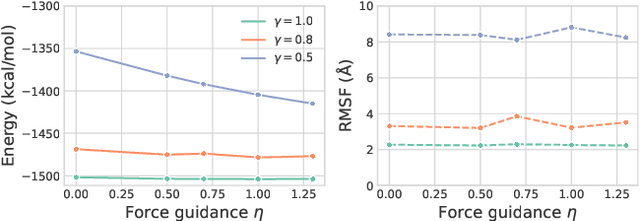
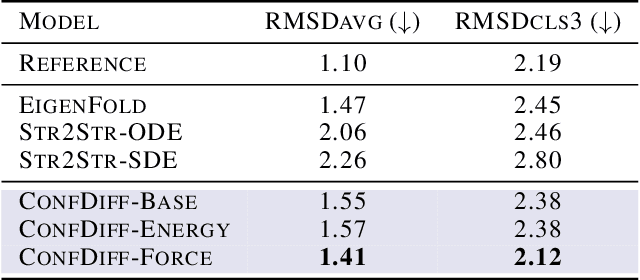
The conformational landscape of proteins is crucial to understanding their functionality in complex biological processes. Traditional physics-based computational methods, such as molecular dynamics (MD) simulations, suffer from rare event sampling and long equilibration time problems, hindering their applications in general protein systems. Recently, deep generative modeling techniques, especially diffusion models, have been employed to generate novel protein conformations. However, existing score-based diffusion methods cannot properly incorporate important physical prior knowledge to guide the generation process, causing large deviations in the sampled protein conformations from the equilibrium distribution. In this paper, to overcome these limitations, we propose a force-guided SE(3) diffusion model, ConfDiff, for protein conformation generation. By incorporating a force-guided network with a mixture of data-based score models, ConfDiff can can generate protein conformations with rich diversity while preserving high fidelity. Experiments on a variety of protein conformation prediction tasks, including 12 fast-folding proteins and the Bovine Pancreatic Trypsin Inhibitor (BPTI), demonstrate that our method surpasses the state-of-the-art method.
Holistic Parking Slot Detection with Polygon-Shaped Representations
Oct 17, 2023
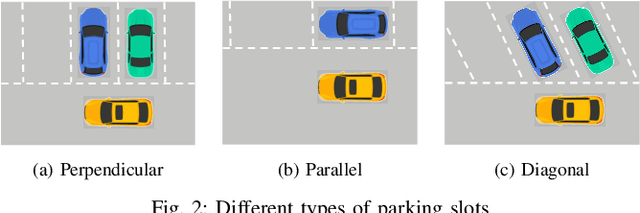
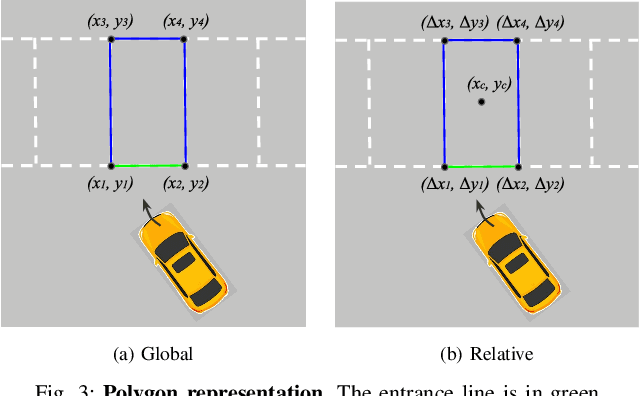

Current parking slot detection in advanced driver-assistance systems (ADAS) primarily relies on ultrasonic sensors. This method has several limitations such as the need to scan the entire parking slot before detecting it, the incapacity of detecting multiple slots in a row, and the difficulty of classifying them. Due to the complex visual environment, vehicles are equipped with surround view camera systems to detect vacant parking slots. Previous research works in this field mostly use image-domain models to solve the problem. These two-stage approaches separate the 2D detection and 3D pose estimation steps using camera calibration. In this paper, we propose one-step Holistic Parking Slot Network (HPS-Net), a tailor-made adaptation of the You Only Look Once (YOLO)v4 algorithm. This camera-based approach directly outputs the four vertex coordinates of the parking slot in topview domain, instead of a bounding box in raw camera images. Several visible points and shapes can be proposed from different angles. A novel regression loss function named polygon-corner Generalized Intersection over Union (GIoU) for polygon vertex position optimization is also proposed to manage the slot orientation and to distinguish the entrance line. Experiments show that HPS-Net can detect various vacant parking slots with a F1-score of 0.92 on our internal Valeo Parking Slots Dataset (VPSD) and 0.99 on the public dataset PS2.0. It provides a satisfying generalization and robustness in various parking scenarios, such as indoor (F1: 0.86) or paved ground (F1: 0.91). Moreover, it achieves a real-time detection speed of 17 FPS on Nvidia Drive AGX Xavier. A demo video can be found at https://streamable.com/75j7sj.
Parsing is All You Need for Accurate Gait Recognition in the Wild
Aug 31, 2023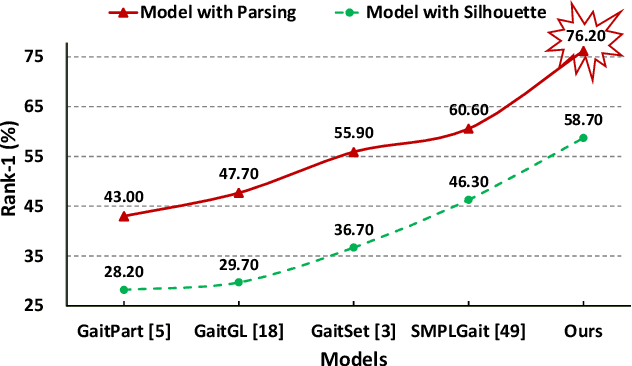
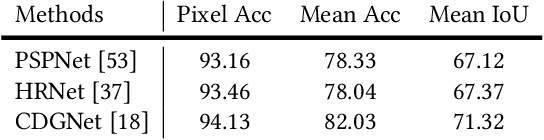
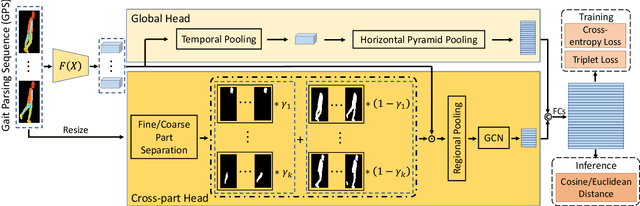
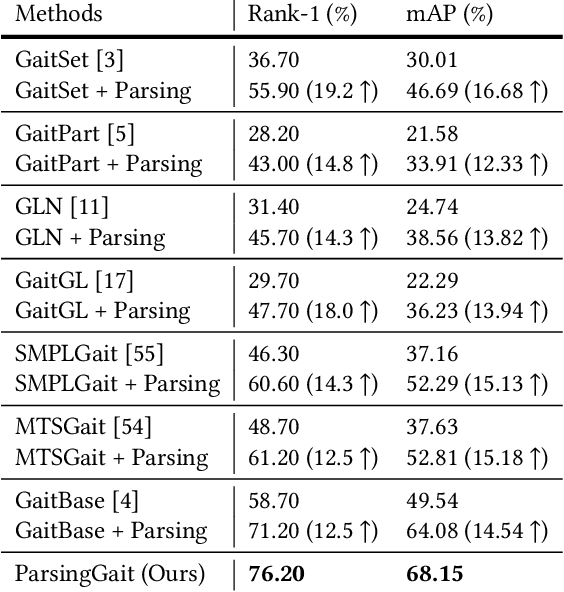
Binary silhouettes and keypoint-based skeletons have dominated human gait recognition studies for decades since they are easy to extract from video frames. Despite their success in gait recognition for in-the-lab environments, they usually fail in real-world scenarios due to their low information entropy for gait representations. To achieve accurate gait recognition in the wild, this paper presents a novel gait representation, named Gait Parsing Sequence (GPS). GPSs are sequences of fine-grained human segmentation, i.e., human parsing, extracted from video frames, so they have much higher information entropy to encode the shapes and dynamics of fine-grained human parts during walking. Moreover, to effectively explore the capability of the GPS representation, we propose a novel human parsing-based gait recognition framework, named ParsingGait. ParsingGait contains a Convolutional Neural Network (CNN)-based backbone and two light-weighted heads. The first head extracts global semantic features from GPSs, while the other one learns mutual information of part-level features through Graph Convolutional Networks to model the detailed dynamics of human walking. Furthermore, due to the lack of suitable datasets, we build the first parsing-based dataset for gait recognition in the wild, named Gait3D-Parsing, by extending the large-scale and challenging Gait3D dataset. Based on Gait3D-Parsing, we comprehensively evaluate our method and existing gait recognition methods. The experimental results show a significant improvement in accuracy brought by the GPS representation and the superiority of ParsingGait. The code and dataset are available at https://gait3d.github.io/gait3d-parsing-hp .
Learning Harmonic Molecular Representations on Riemannian Manifold
Mar 27, 2023Molecular representation learning plays a crucial role in AI-assisted drug discovery research. Encoding 3D molecular structures through Euclidean neural networks has become the prevailing method in the geometric deep learning community. However, the equivariance constraints and message passing in Euclidean space may limit the network expressive power. In this work, we propose a Harmonic Molecular Representation learning (HMR) framework, which represents a molecule using the Laplace-Beltrami eigenfunctions of its molecular surface. HMR offers a multi-resolution representation of molecular geometric and chemical features on 2D Riemannian manifold. We also introduce a harmonic message passing method to realize efficient spectral message passing over the surface manifold for better molecular encoding. Our proposed method shows comparable predictive power to current models in small molecule property prediction, and outperforms the state-of-the-art deep learning models for ligand-binding protein pocket classification and the rigid protein docking challenge, demonstrating its versatility in molecular representation learning.
Unsupervised Word Segmentation with Bi-directional Neural Language Model
Mar 02, 2021
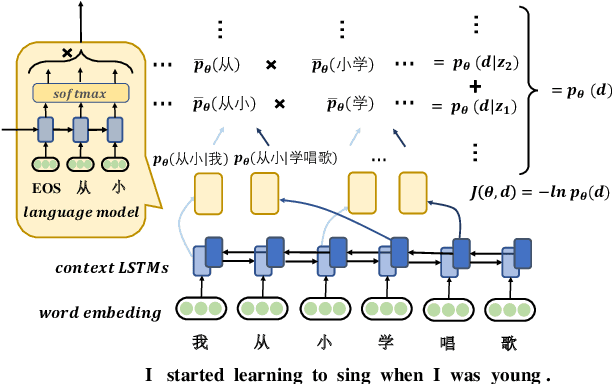
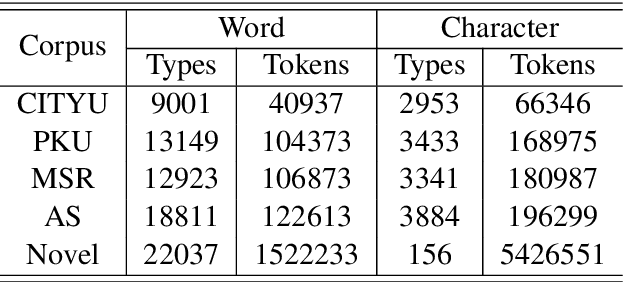
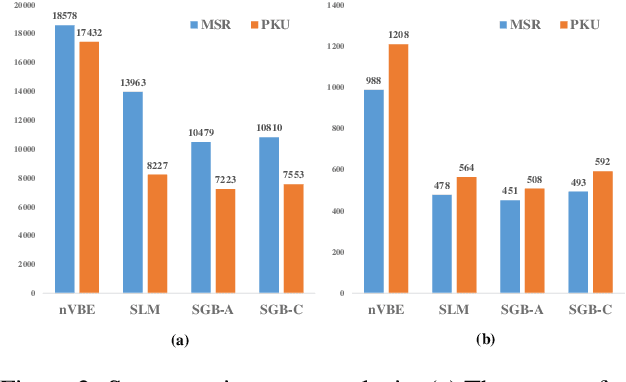
We present an unsupervised word segmentation model, in which the learning objective is to maximize the generation probability of a sentence given its all possible segmentation. Such generation probability can be factorized into the likelihood of each possible segment given the context in a recursive way. In order to better capture the long- and short-term dependencies, we propose to use bi-directional neural language models to better capture the features of segment's context. Two decoding algorithms are also described to combine the context features from both directions to generate the final segmentation, which helps to reconcile word boundary ambiguities. Experimental results showed that our context-sensitive unsupervised segmentation model achieved state-of-the-art at different evaluation settings on various data sets for Chinese, and the comparable result for Thai.