 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Parking Perception by Multi-Task Fisheye Cross-view Transformers
Aug 22, 2024Current parking area perception algorithms primarily focus on detecting vacant slots within a limited range, relying on error-prone homographic projection for both labeling and inference. However, recent advancements in Advanced Driver Assistance System (ADAS) require interaction with end-users through comprehensive and intelligent Human-Machine Interfaces (HMIs). These interfaces should present a complete perception of the parking area going from distinguishing vacant slots' entry lines to the orientation of other parked vehicles. This paper introduces Multi-Task Fisheye Cross View Transformers (MT F-CVT), which leverages features from a four-camera fisheye Surround-view Camera System (SVCS) with multihead attentions to create a detailed Bird-Eye View (BEV) grid feature map. Features are processed by both a segmentation decoder and a Polygon-Yolo based object detection decoder for parking slots and vehicles. Trained on data labeled using LiDAR, MT F-CVT positions objects within a 25m x 25m real open-road scenes with an average error of only 20 cm. Our larger model achieves an F-1 score of 0.89. Moreover the smaller model operates at 16 fps on an Nvidia Jetson Orin embedded board, with similar detection results to the larger one. MT F-CVT demonstrates robust generalization capability across different vehicles and camera rig configurations. A demo video from an unseen vehicle and camera rig is available at: https://streamable.com/jjw54x.
Holistic Parking Slot Detection with Polygon-Shaped Representations
Oct 17, 2023
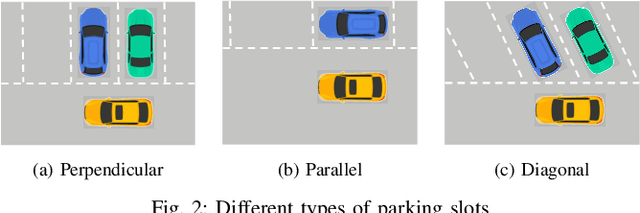
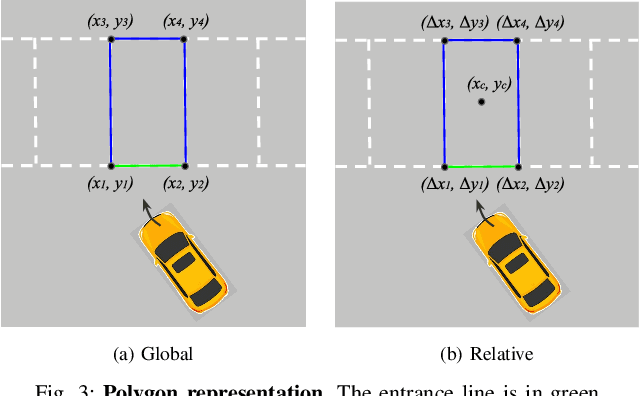

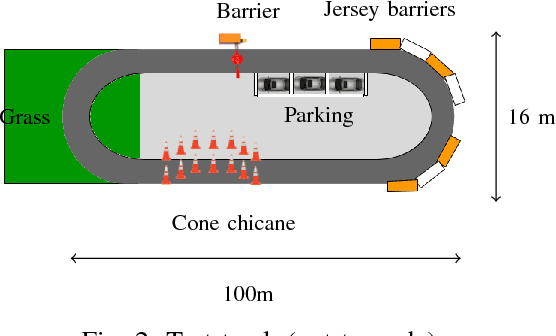
Current parking slot detection in advanced driver-assistance systems (ADAS) primarily relies on ultrasonic sensors. This method has several limitations such as the need to scan the entire parking slot before detecting it, the incapacity of detecting multiple slots in a row, and the difficulty of classifying them. Due to the complex visual environment, vehicles are equipped with surround view camera systems to detect vacant parking slots. Previous research works in this field mostly use image-domain models to solve the problem. These two-stage approaches separate the 2D detection and 3D pose estimation steps using camera calibration. In this paper, we propose one-step Holistic Parking Slot Network (HPS-Net), a tailor-made adaptation of the You Only Look Once (YOLO)v4 algorithm. This camera-based approach directly outputs the four vertex coordinates of the parking slot in topview domain, instead of a bounding box in raw camera images. Several visible points and shapes can be proposed from different angles. A novel regression loss function named polygon-corner Generalized Intersection over Union (GIoU) for polygon vertex position optimization is also proposed to manage the slot orientation and to distinguish the entrance line. Experiments show that HPS-Net can detect various vacant parking slots with a F1-score of 0.92 on our internal Valeo Parking Slots Dataset (VPSD) and 0.99 on the public dataset PS2.0. It provides a satisfying generalization and robustness in various parking scenarios, such as indoor (F1: 0.86) or paved ground (F1: 0.91). Moreover, it achieves a real-time detection speed of 17 FPS on Nvidia Drive AGX Xavier. A demo video can be found at https://streamable.com/75j7sj.
VRUNet: Multi-Task Learning Model for Intent Prediction of Vulnerable Road Users
Jul 10, 2020
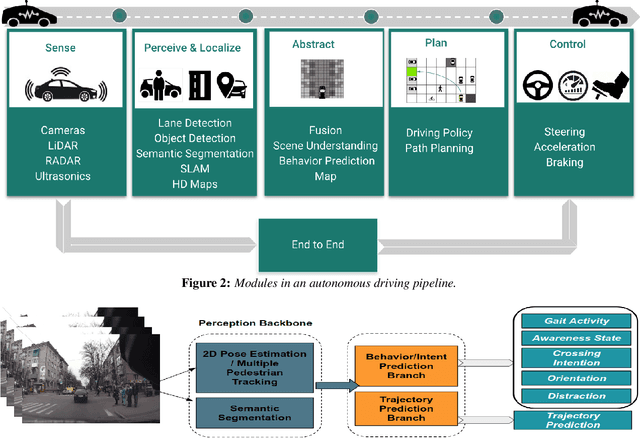
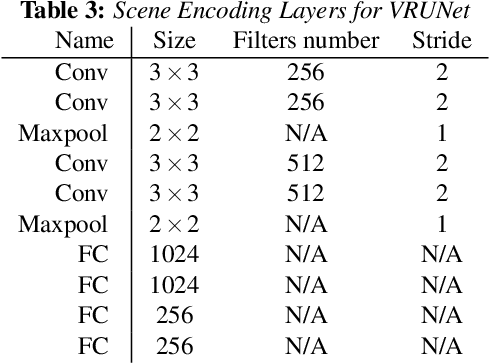

Advanced perception and path planning are at the core for any self-driving vehicle. Autonomous vehicles need to understand the scene and intentions of other road users for safe motion planning. For urban use cases it is very important to perceive and predict the intentions of pedestrians, cyclists, scooters, etc., classified as vulnerable road users (VRU). Intent is a combination of pedestrian activities and long term trajectories defining their future motion. In this paper we propose a multi-task learning model to predict pedestrian actions, crossing intent and forecast their future path from video sequences. We have trained the model on naturalistic driving open-source JAAD dataset, which is rich in behavioral annotations and real world scenarios. Experimental results show state-of-the-art performance on JAAD dataset and how we can benefit from jointly learning and predicting actions and trajectories using 2D human pose features and scene context.
PLOP: Probabilistic poLynomial Objects trajectory Planning for autonomous driving
Mar 09, 2020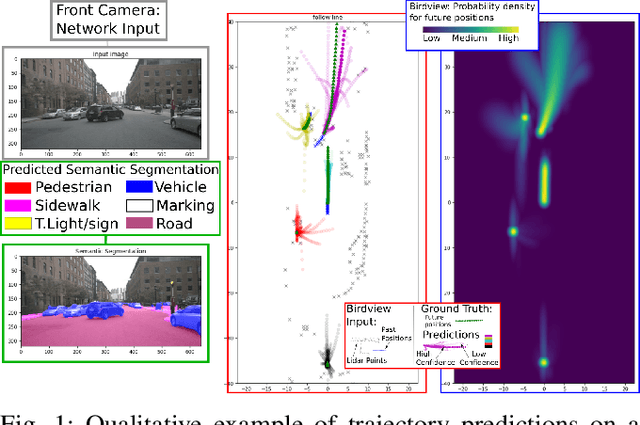
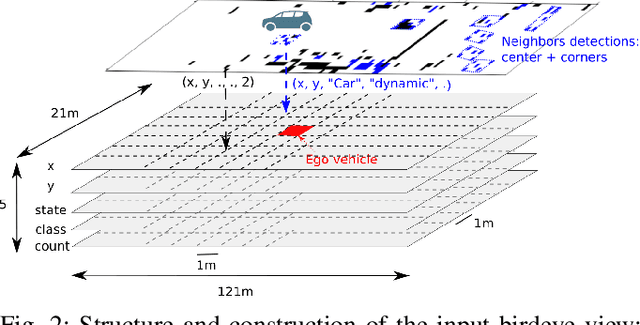
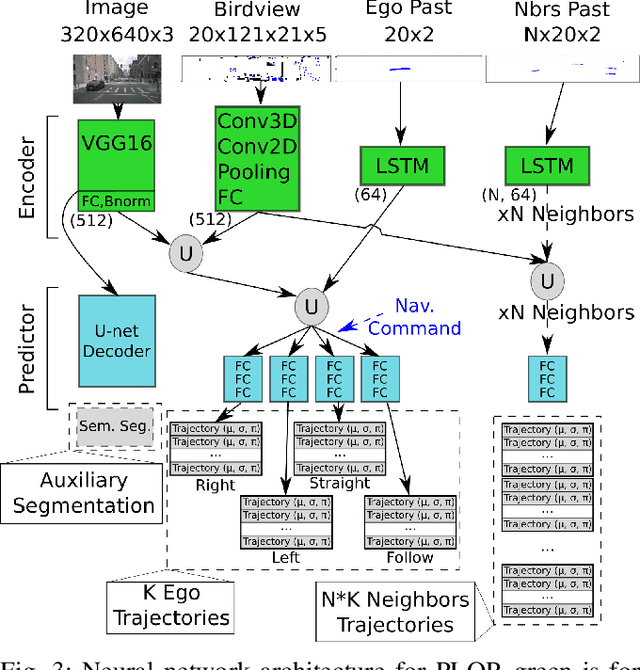
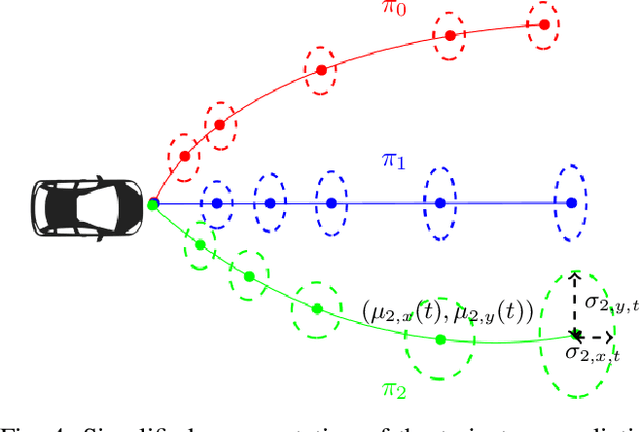
To navigate safely in an urban environment, an autonomous vehicle (ego vehicle) needs to understand and anticipate its surroundings, in particular the behavior of other road users (neighbors). However, multiple choices are often acceptable (e.g. turn right or left, or different ways of avoiding an obstacle). We focus here on predicting multiple feasible future trajectories both for the ego vehicle and neighbors through a probabilistic framework. We use a conditional imitation learning algorithm, conditioned by a navigation command for the ego vehicle (e.g. "turn right"). It takes as input the ego car front camera image, a Lidar point cloud in a bird-eye view grid and present and past objects detections to output ego vehicle and neighbors possible trajectories but also semantic segmentation as an auxiliary loss. We evaluate our method on the publicly available dataset nuScenes, showing state-of-the-art performance and investigating the impact of our architecture choices.
Conditional Vehicle Trajectories Prediction in CARLA Urban Environment
Sep 02, 2019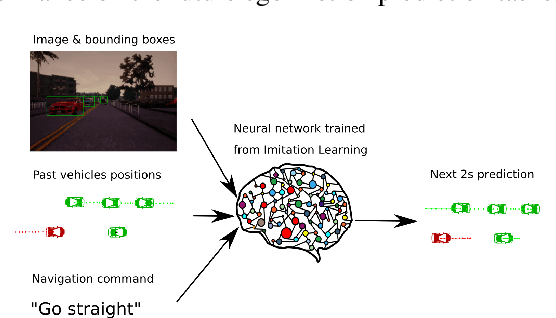
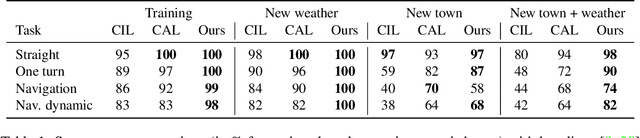
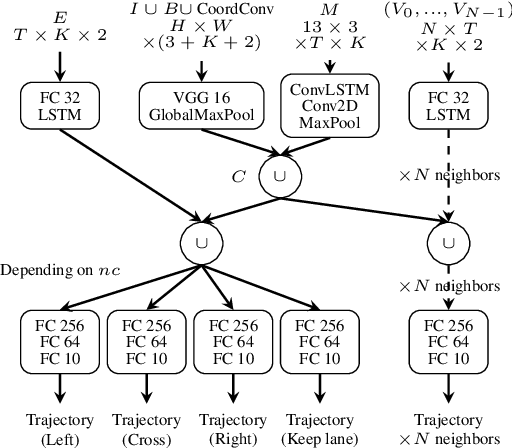
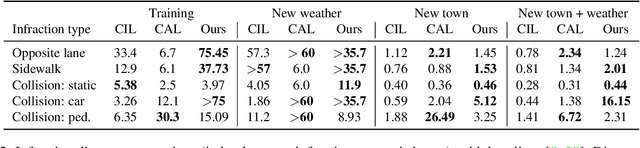
Imitation learning is becoming more and more successful for autonomous driving. End-to-end (raw signal to command) performs well on relatively simple tasks (lane keeping and navigation). Mid-to-mid (environment abstraction to mid-level trajectory representation) or direct perception (raw signal to performance) approaches strive to handle more complex, real life environment and tasks (e.g. complex intersection). In this work, we show that complex urban situations can be handled with raw signal input and mid-level representation. We build a hybrid end-to-mid approach predicting trajectories for neighbor vehicles and for the ego vehicle with a conditional navigation goal. We propose an original architecture inspired from social pooling LSTM taking low and mid level data as input and producing trajectories as polynomials of time. We introduce a label augmentation mechanism to get the level of generalization that is required to control a vehicle. The performance is evaluated on CARLA 0.8 benchmark, showing significant improvements over previously published state of the art.
Imitation Learning for End to End Vehicle Longitudinal Control with Forward Camera
Dec 14, 2018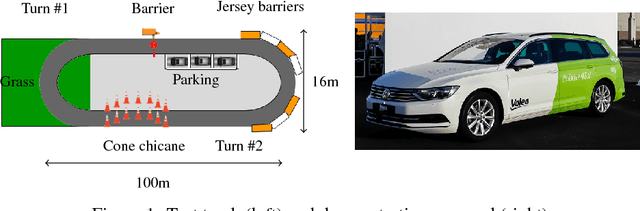
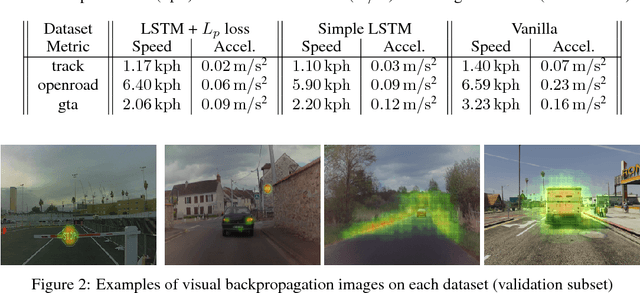
In this paper we present a complete study of an end-to-end imitation learning system for speed control of a real car, based on a neural network with a Long Short Term Memory (LSTM). To achieve robustness and generalization from expert demonstrations, we propose data augmentation and label augmentation that are relevant for imitation learning in longitudinal control context. Based on front camera image only, our system is able to correctly control the speed of a car in simulation environment, and in a real car on a challenging test track. The system also shows promising results in open road context.
Sparse and Dense Data with CNNs: Depth Completion and Semantic Segmentation
Aug 31, 2018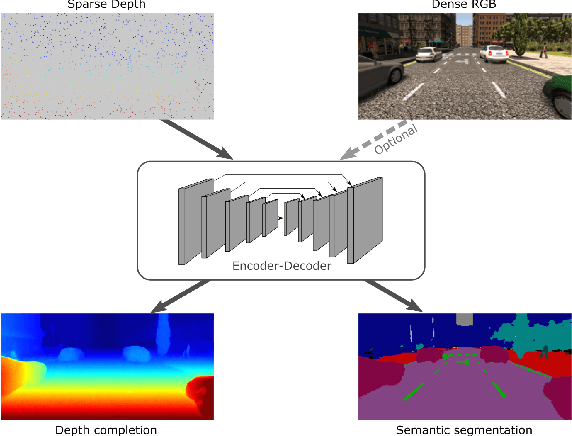
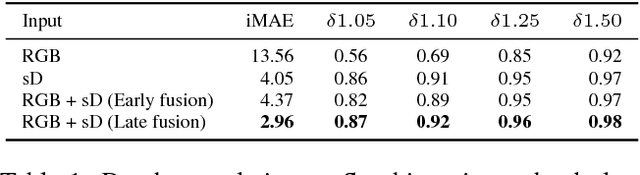


Convolutional neural networks are designed for dense data, but vision data is often sparse (stereo depth, point clouds, pen stroke, etc.). We present a method to handle sparse depth data with optional dense RGB, and accomplish depth completion and semantic segmentation changing only the last layer. Our proposal efficiently learns sparse features without the need of an additional validity mask. We show how to ensure network robustness to varying input sparsities. Our method even works with densities as low as 0.8% (8 layer lidar), and outperforms all published state-of-the-art on the Kitti depth completion benchmark.
End to End Vehicle Lateral Control Using a Single Fisheye Camera
Aug 20, 2018


Convolutional neural networks are commonly used to control the steering angle for autonomous cars. Most of the time, multiple long range cameras are used to generate lateral failure cases. In this paper we present a novel model to generate this data and label augmentation using only one short range fisheye camera. We present our simulator and how it can be used as a consistent metric for lateral end-to-end control evaluation. Experiments are conducted on a custom dataset corresponding to more than 10000 km and 200 hours of open road driving. Finally we evaluate this model on real world driving scenarios, open road and a custom test track with challenging obstacle avoidance and sharp turns. In our simulator based on real-world videos, the final model was capable of more than 99% autonomy on urban road