 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Max: Making RL practical for Autonomous Driving
Mar 11, 2025Learning-based decision-making has the potential to enable generalizable Autonomous Driving (AD) policies, reducing the engineering overhead of rule-based approaches. Imitation Learning (IL) remains the dominant paradigm, benefiting from large-scale human demonstration datasets, but it suffers from inherent limitations such as distribution shift and imitation gaps. Reinforcement Learning (RL) presents a promising alternative, yet its adoption in AD remains limited due to the lack of standardized and efficient research frameworks. To this end, we introduce V-Max, an open research framework providing all the necessary tools to make RL practical for AD. V-Max is built on Waymax, a hardware-accelerated AD simulator designed for large-scale experimentation. We extend it using ScenarioNet's approach, enabling the fast simulation of diverse AD datasets. V-Max integrates a set of observation and reward functions, transformer-based encoders, and training pipelines. Additionally, it includes adversarial evaluation settings and an extensive set of evaluation metrics. Through a large-scale benchmark, we analyze how network architectures, observation functions, training data, and reward shaping impact RL performance.
PLOP: Probabilistic poLynomial Objects trajectory Planning for autonomous driving
Mar 09, 2020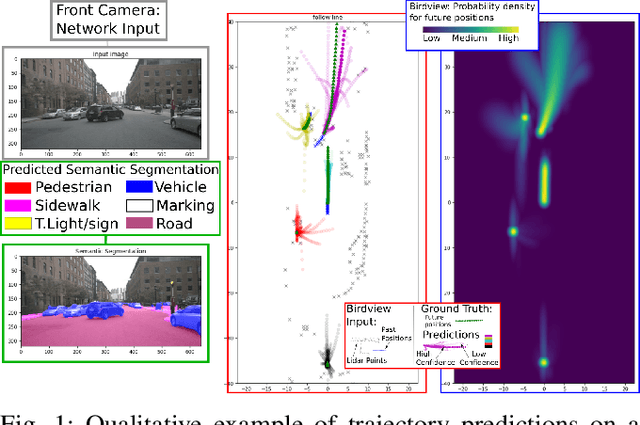
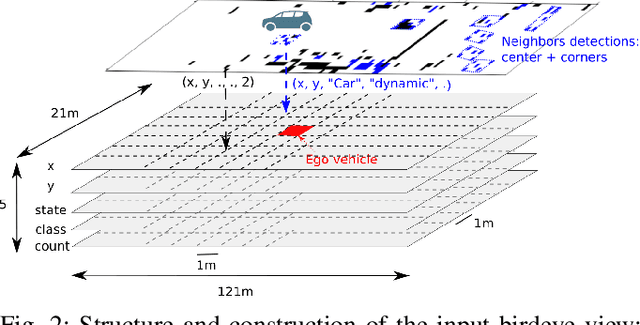
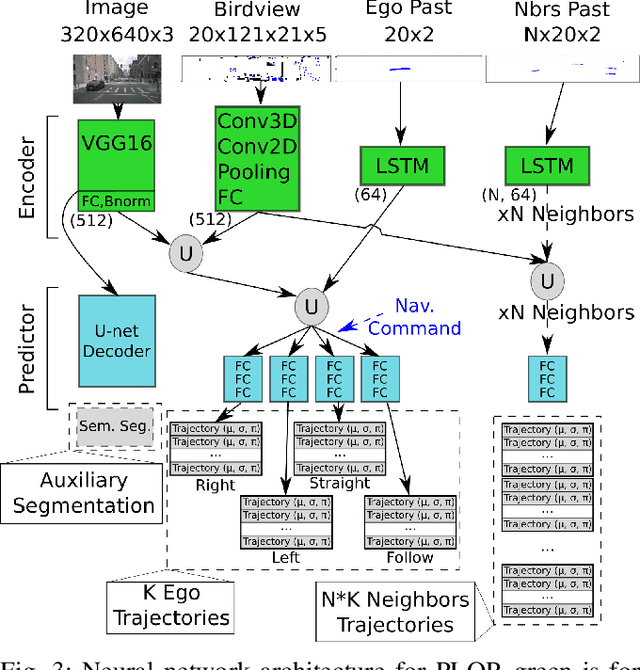
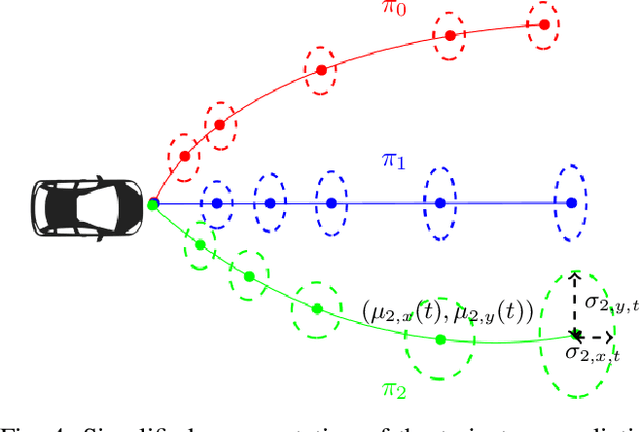
To navigate safely in an urban environment, an autonomous vehicle (ego vehicle) needs to understand and anticipate its surroundings, in particular the behavior of other road users (neighbors). However, multiple choices are often acceptable (e.g. turn right or left, or different ways of avoiding an obstacle). We focus here on predicting multiple feasible future trajectories both for the ego vehicle and neighbors through a probabilistic framework. We use a conditional imitation learning algorithm, conditioned by a navigation command for the ego vehicle (e.g. "turn right"). It takes as input the ego car front camera image, a Lidar point cloud in a bird-eye view grid and present and past objects detections to output ego vehicle and neighbors possible trajectories but also semantic segmentation as an auxiliary loss. We evaluate our method on the publicly available dataset nuScenes, showing state-of-the-art performance and investigating the impact of our architecture choices.
Conditional Vehicle Trajectories Prediction in CARLA Urban Environment
Sep 02, 2019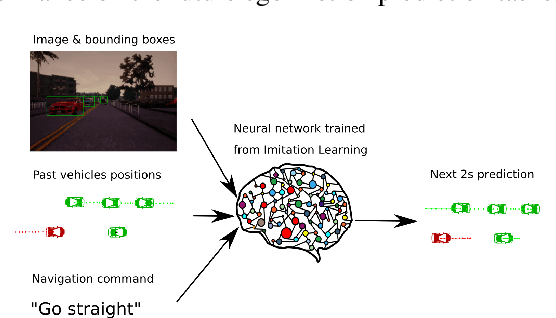
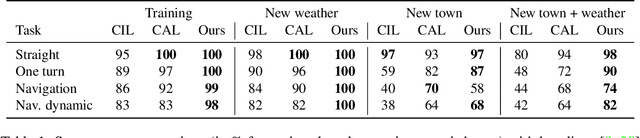
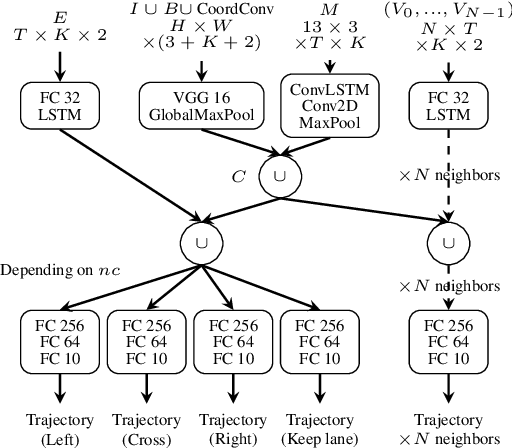
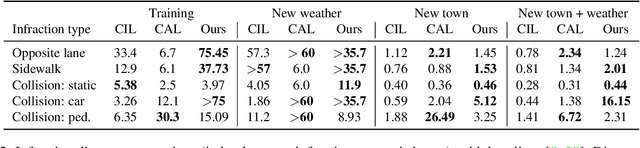
Imitation learning is becoming more and more successful for autonomous driving. End-to-end (raw signal to command) performs well on relatively simple tasks (lane keeping and navigation). Mid-to-mid (environment abstraction to mid-level trajectory representation) or direct perception (raw signal to performance) approaches strive to handle more complex, real life environment and tasks (e.g. complex intersection). In this work, we show that complex urban situations can be handled with raw signal input and mid-level representation. We build a hybrid end-to-mid approach predicting trajectories for neighbor vehicles and for the ego vehicle with a conditional navigation goal. We propose an original architecture inspired from social pooling LSTM taking low and mid level data as input and producing trajectories as polynomials of time. We introduce a label augmentation mechanism to get the level of generalization that is required to control a vehicle. The performance is evaluated on CARLA 0.8 benchmark, showing significant improvements over previously published state of the art.
Imitation Learning for End to End Vehicle Longitudinal Control with Forward Camera
Dec 14, 2018
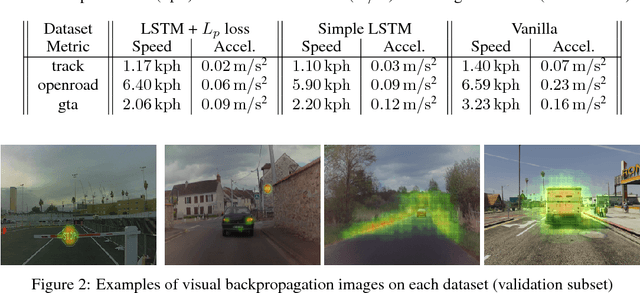
In this paper we present a complete study of an end-to-end imitation learning system for speed control of a real car, based on a neural network with a Long Short Term Memory (LSTM). To achieve robustness and generalization from expert demonstrations, we propose data augmentation and label augmentation that are relevant for imitation learning in longitudinal control context. Based on front camera image only, our system is able to correctly control the speed of a car in simulation environment, and in a real car on a challenging test track. The system also shows promising results in open road context.