 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Word Segmentation with Bi-directional Neural Language Model
Paper and Code
Mar 02, 2021
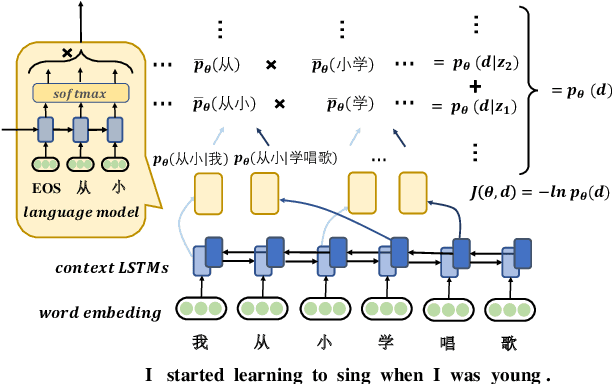
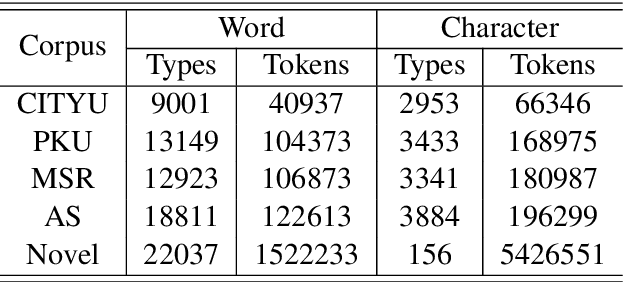
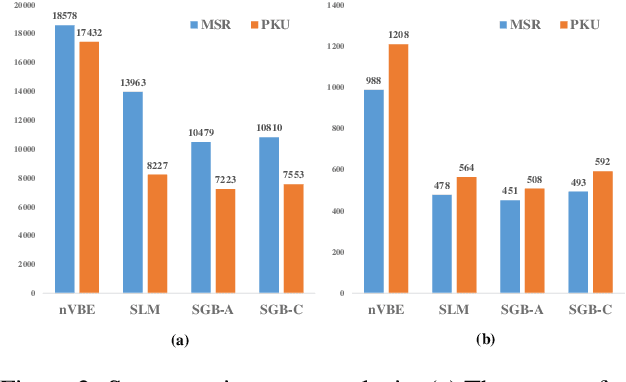
We present an unsupervised word segmentation model, in which the learning objective is to maximize the generation probability of a sentence given its all possible segmentation. Such generation probability can be factorized into the likelihood of each possible segment given the context in a recursive way. In order to better capture the long- and short-term dependencies, we propose to use bi-directional neural language models to better capture the features of segment's context. Two decoding algorithms are also described to combine the context features from both directions to generate the final segmentation, which helps to reconcile word boundary ambiguities. Experimental results showed that our context-sensitive unsupervised segmentation model achieved state-of-the-art at different evaluation settings on various data sets for Chinese, and the comparable result for Thai.