 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUSE: Frequency-domain Unification and Spectral Energy Alignment for Multi-modal Object Re-Identification
Jun 18, 2026Despite significant progress in multi-modal Re-Identification (ReID), existing methods tend to emphasize low-frequency cues. Consequently, they focus on attributes such as color, illumination, and coarse appearance, while overlooking mid and high-frequency structures that encode geometric, textural, and identity-discriminative details. This imbalance leads to incomplete spectral representations and unstable cross-modal alignment. To overcome these limitations, we introduce FUSE, a frequency-domain framework that reformulates multi-modal ReID as a two-stage process of spectral disentanglement and energy alignment. The proposed Spectral Decomposition Module (SDM) adaptively partitions features into low, mid, and high-frequency subspaces, enabling hierarchical spectral modeling. The Cross-Modal Alignment Module (CAM) further enforces energy alignment and subspace complementarity across modalities via frequency-consistency regularization. In addition, FUSE incorporates learnable frequency modulation to enhance robustness under varying illumination and heterogeneous sensor conditions. Extensive experiments on RGBNT201, RGBNT100, and MSVR310 show that FUSE achieves 9.1\% mAP and 9.5\% Rank-1 improvements, establishing an interpretable frequency-domain paradigm for multi-modal representation learning.
Dual-Mapping Sparse Vector Transmission for Short Packet URLLC
Jan 22, 2026Sparse vector coding (SVC) is a promising short-packet transmission method for ultra reliable low latency communication (URLLC) in next generation communication systems. In this paper, a dual-mapping SVC (DM-SVC) based short packet transmission scheme is proposed to further enhance the transmission performance of SVC. The core idea behind the proposed scheme lies in mapping the transmitted information bits onto sparse vectors via block and single-element sparse mappings. The block sparse mapping pattern is able to concentrate the transmit power in a small number of non-zero blocks thus improving the decoding accuracy, while the single-element sparse mapping pattern ensures that the code length does not increase dramatically with the number of transmitted information bits. At the receiver, a two-stage decoding algorithm is proposed to sequentially identify non-zero block indexes and single-element non-zero indexes. Extensive simulation results verify that proposed DM-SVC scheme outperforms the existing SVC schemes in terms of block error rate and spectral efficiency.
Low-Complexity Sparse Superimposed Coding for Ultra Reliable Low Latency Communications
Jan 22, 2026Sparse superimposed coding (SSC) has emerged as a promising technique for short-packet transmission in ultra-reliable low-latency communication scenarios. However, conventional SSC schemes often suffer from high encoding and decoding complexity due to the use of dense codebook matrices. In this paper, we propose a low-complexity SSC scheme by designing a sparse codebook structure, where each codeword contains only a small number of non-zero elements. The decoding is performed using the traditional multipath matching pursuit algorithm, and the overall complexity is significantly reduced by exploiting the sparsity of the codebook. Simulation results show that the proposed scheme achieves a favorable trade-off between BLER performance and computational complexity, and exhibits strong robustness across different transmission block lengths.
Hierarchical Sparse Vector Transmission for Ultra Reliable and Low Latency Communications
Jan 19, 2026Sparse vector transmission (SVT) is a promising candidate technology for achieving ultra-reliable low-latency communication (URLLC). In this paper, a hierarchical SVT scheme is proposed for multi-user URLLC scenarios. The hierarchical SVT scheme partitions the transmitted bits into common and private parts. The common information is conveyed by the indices of non-zero sections in a sparse vector, while each user's private information is embedded into non-zero blocks with specific block lengths. At the receiver, the common bits are first recovered from the detected non-zero sections, followed by user-specific private bits decoding based on the corresponding non-zero block indices. Simulation results show the proposed scheme outperforms state-of-the-art SVT schemes in terms of block error rate.
TextSplat: Text-Guided Semantic Fusion for Generalizable Gaussian Splatting
Apr 13, 2025Recent advancements in Generalizable Gaussian Splatting have enabled robust 3D reconstruction from sparse input views by utilizing feed-forward Gaussian Splatting models, achieving superior cross-scene generalization. However, while many methods focus on geometric consistency, they often neglect the potential of text-driven guidance to enhance semantic understanding, which is crucial for accurately reconstructing fine-grained details in complex scenes. To address this limitation, we propose TextSplat--the first text-driven Generalizable Gaussian Splatting framework. By employing a text-guided fusion of diverse semantic cues, our framework learns robust cross-modal feature representations that improve the alignment of geometric and semantic information, producing high-fidelity 3D reconstructions. Specifically, our framework employs three parallel modules to obtain complementary representations: the Diffusion Prior Depth Estimator for accurate depth information, the Semantic Aware Segmentation Network for detailed semantic information, and the Multi-View Interaction Network for refined cross-view features. Then, in the Text-Guided Semantic Fusion Module, these representations are integrated via the text-guided and attention-based feature aggregation mechanism, resulting in enhanced 3D Gaussian parameters enriched with detailed semantic cues. Experimental results on various benchmark datasets demonstrate improved performance compared to existing methods across multiple evaluation metrics, validating the effectiveness of our framework. The code will be publicly available.
It Takes Two: Accurate Gait Recognition in the Wild via Cross-granularity Alignment
Nov 16, 2024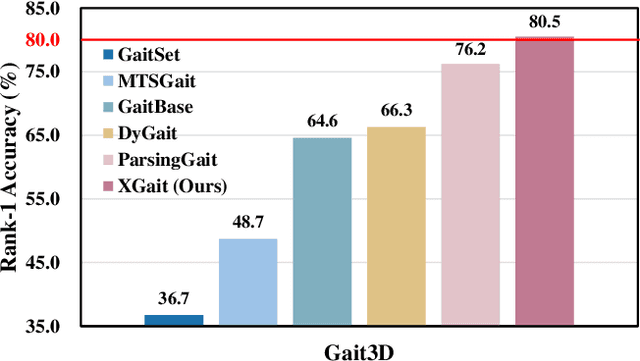
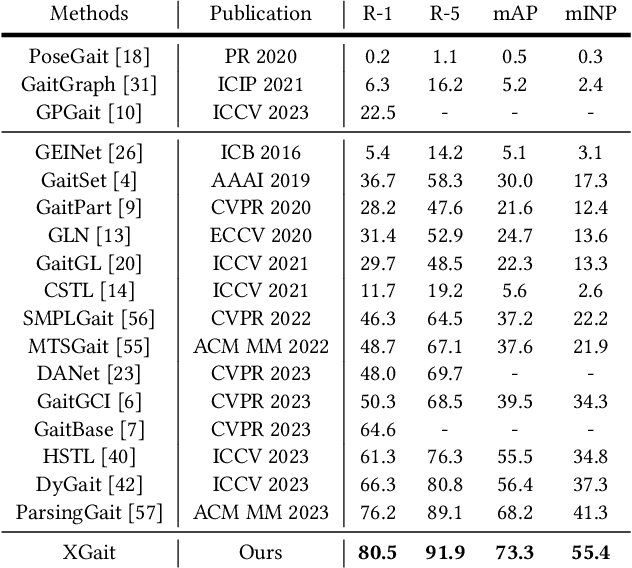
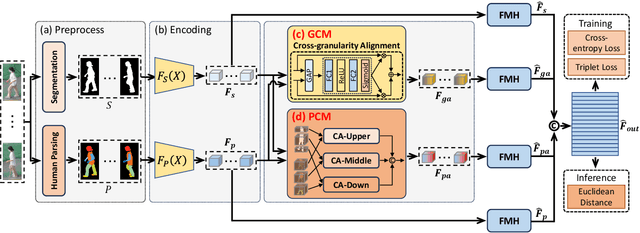
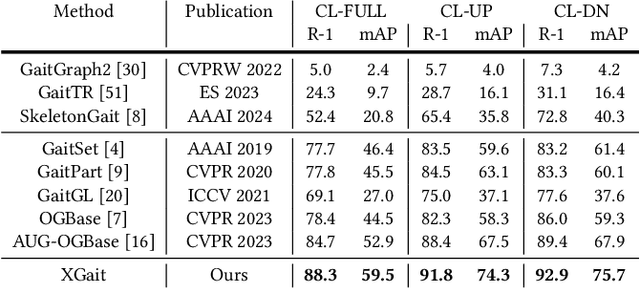
Existing studies for gait recognition primarily utilized sequences of either binary silhouette or human parsing to encode the shapes and dynamics of persons during walking. Silhouettes exhibit accurate segmentation quality and robustness to environmental variations, but their low information entropy may result in sub-optimal performance. In contrast, human parsing provides fine-grained part segmentation with higher information entropy, but the segmentation quality may deteriorate due to the complex environments. To discover the advantages of silhouette and parsing and overcome their limitations, this paper proposes a novel cross-granularity alignment gait recognition method, named XGait, to unleash the power of gait representations of different granularity. To achieve this goal, the XGait first contains two branches of backbone encoders to map the silhouette sequences and the parsing sequences into two latent spaces, respectively. Moreover, to explore the complementary knowledge across the features of two representations, we design the Global Cross-granularity Module (GCM) and the Part Cross-granularity Module (PCM) after the two encoders. In particular, the GCM aims to enhance the quality of parsing features by leveraging global features from silhouettes, while the PCM aligns the dynamics of human parts between silhouette and parsing features using the high information entropy in parsing sequences. In addition, to effectively guide the alignment of two representations with different granularity at the part level, an elaborate-designed learnable division mechanism is proposed for the parsing features. Comprehensive experiments on two large-scale gait datasets not only show the superior performance of XGait with the Rank-1 accuracy of 80.5% on Gait3D and 88.3% CCPG but also reflect the robustness of the learned features even under challenging conditions like occlusions and cloth changes.
Parsing is All You Need for Accurate Gait Recognition in the Wild
Aug 31, 2023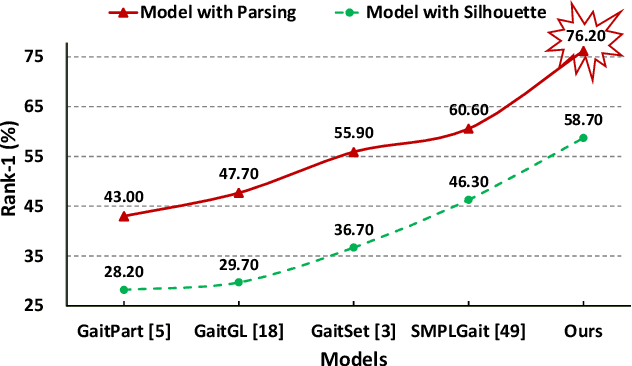
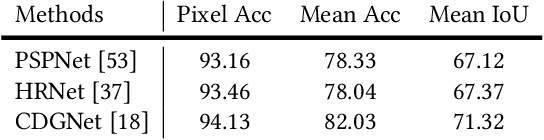
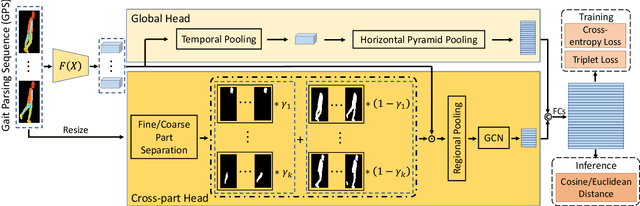
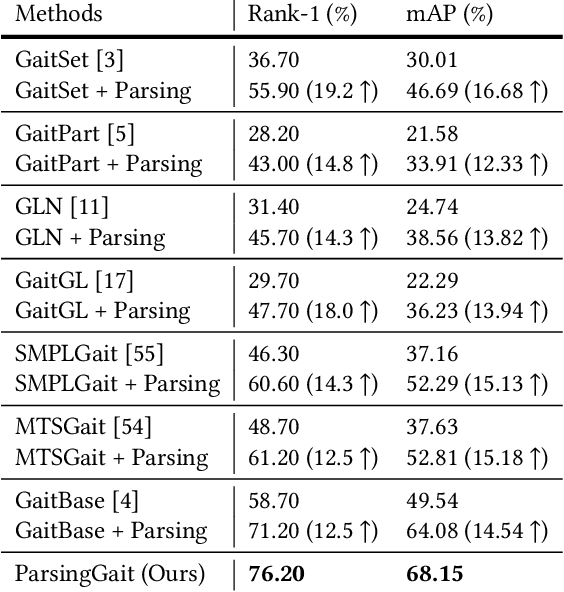
Binary silhouettes and keypoint-based skeletons have dominated human gait recognition studies for decades since they are easy to extract from video frames. Despite their success in gait recognition for in-the-lab environments, they usually fail in real-world scenarios due to their low information entropy for gait representations. To achieve accurate gait recognition in the wild, this paper presents a novel gait representation, named Gait Parsing Sequence (GPS). GPSs are sequences of fine-grained human segmentation, i.e., human parsing, extracted from video frames, so they have much higher information entropy to encode the shapes and dynamics of fine-grained human parts during walking. Moreover, to effectively explore the capability of the GPS representation, we propose a novel human parsing-based gait recognition framework, named ParsingGait. ParsingGait contains a Convolutional Neural Network (CNN)-based backbone and two light-weighted heads. The first head extracts global semantic features from GPSs, while the other one learns mutual information of part-level features through Graph Convolutional Networks to model the detailed dynamics of human walking. Furthermore, due to the lack of suitable datasets, we build the first parsing-based dataset for gait recognition in the wild, named Gait3D-Parsing, by extending the large-scale and challenging Gait3D dataset. Based on Gait3D-Parsing, we comprehensively evaluate our method and existing gait recognition methods. The experimental results show a significant improvement in accuracy brought by the GPS representation and the superiority of ParsingGait. The code and dataset are available at https://gait3d.github.io/gait3d-parsing-hp .
Gait Recognition in the Wild with Dense 3D Representations and A Benchmark
Apr 06, 2022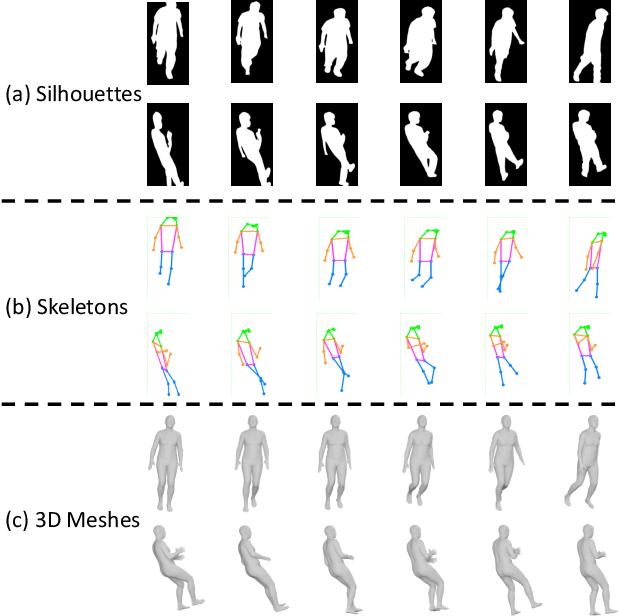
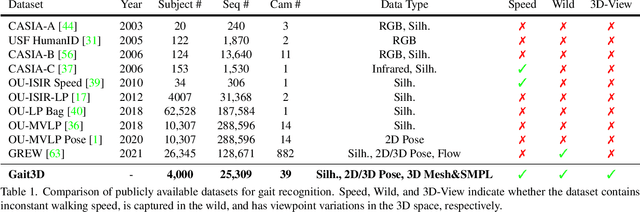
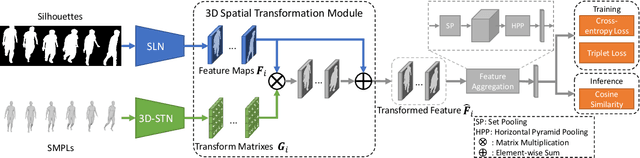
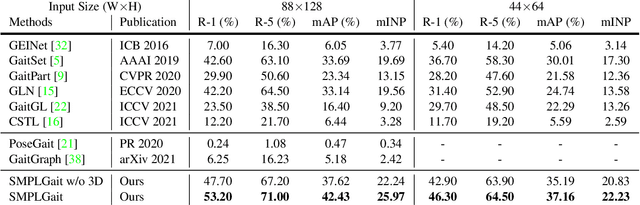
Existing studies for gait recognition are dominated by 2D representations like the silhouette or skeleton of the human body in constrained scenes. However, humans live and walk in the unconstrained 3D space, so projecting the 3D human body onto the 2D plane will discard a lot of crucial information like the viewpoint, shape, and dynamics for gait recognition. Therefore, this paper aims to explore dense 3D representations for gait recognition in the wild, which is a practical yet neglected problem. In particular, we propose a novel framework to explore the 3D Skinned Multi-Person Linear (SMPL) model of the human body for gait recognition, named SMPLGait. Our framework has two elaborately-designed branches of which one extracts appearance features from silhouettes, the other learns knowledge of 3D viewpoints and shapes from the 3D SMPL model. In addition, due to the lack of suitable datasets, we build the first large-scale 3D representation-based gait recognition dataset, named Gait3D. It contains 4,000 subjects and over 25,000 sequences extracted from 39 cameras in an unconstrained indoor scene. More importantly, it provides 3D SMPL models recovered from video frames which can provide dense 3D information of body shape, viewpoint, and dynamics. Based on Gait3D, we comprehensively compare our method with existing gait recognition approaches, which reflects the superior performance of our framework and the potential of 3D representations for gait recognition in the wild. The code and dataset are available at https://gait3d.github.io.
Learning Based Task Offloading in Digital Twin Empowered Internet of Vehicles
Dec 28, 2021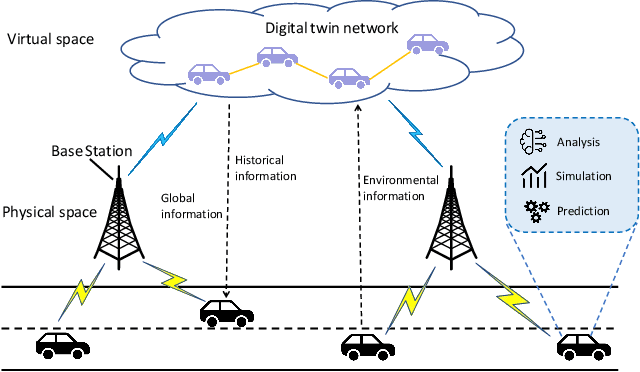
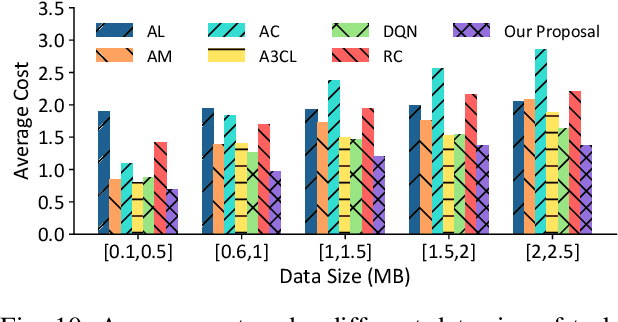

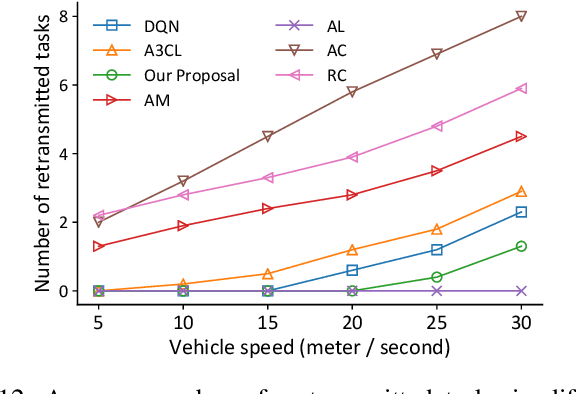
Mobile edge computing has become an effective and fundamental paradigm for futuristic autonomous vehicles to offload computing tasks. However, due to the high mobility of vehicles, the dynamics of the wireless conditions, and the uncertainty of the arrival computing tasks, it is difficult for a single vehicle to determine the optimal offloading strategy. In this paper, we propose a Digital Twin (DT) empowered task offloading framework for Internet of Vehicles. As a software agent residing in the cloud, a DT can obtain both global network information by using communications among DTs, and historical information of a vehicle by using the communications within the twin. The global network information and historical vehicular information can significantly facilitate the offloading. In specific, to preserve the precious computing resource at different levels for most appropriate computing tasks, we integrate a learning scheme based on the prediction of futuristic computing tasks in DT. Accordingly, we model the offloading scheduling process as a Markov Decision Process (MDP) to minimize the long-term cost in terms of a trade off between task latency, energy consumption, and renting cost of clouds. Simulation results demonstrate that our algorithm can effectively find the optimal offloading strategy, as well as achieve the fast convergence speed and high performance, compared with other existing approaches.
TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition
Feb 09, 2021
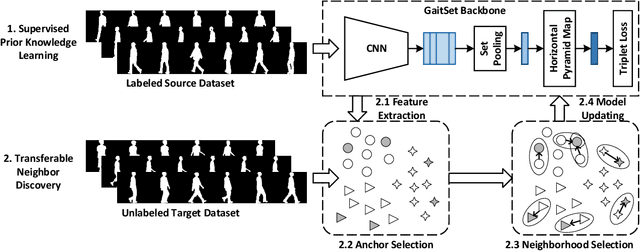
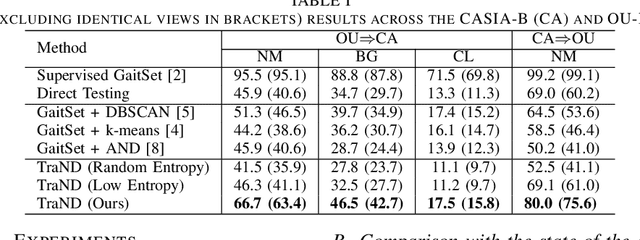
Gait, i.e., the movement pattern of human limbs during locomotion, is a promising biometric for the identification of persons. Despite significant improvement in gait recognition with deep learning, existing studies still neglect a more practical but challenging scenario -- unsupervised cross-domain gait recognition which aims to learn a model on a labeled dataset then adapts it to an unlabeled dataset. Due to the domain shift and class gap, directly applying a model trained on one source dataset to other target datasets usually obtains very poor results. Therefore, this paper proposes a Transferable Neighborhood Discovery (TraND) framework to bridge the domain gap for unsupervised cross-domain gait recognition. To learn effective prior knowledge for gait representation, we first adopt a backbone network pre-trained on the labeled source data in a supervised manner. Then we design an end-to-end trainable approach to automatically discover the confident neighborhoods of unlabeled samples in the latent space. During training, the class consistency indicator is adopted to select confident neighborhoods of samples based on their entropy measurements. Moreover, we explore a high-entropy-first neighbor selection strategy, which can effectively transfer prior knowledge to the target domain. Our method achieves state-of-the-art results on two public datasets, i.e., CASIA-B and OU-LP.