 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Importance Sampling: Rejection-Gated Policy Optimization
Apr 16, 2026We propose a new perspective on policy optimization: rather than reweighting all samples by their importance ratios, an optimizer should select which samples are trustworthy enough to drive a policy update. Building on this view, we introduce Rejection-Gated Policy Optimization (RGPO), which replaces the importance sampling ratio r_theta = pi_theta / pi_old with a smooth, differentiable acceptance gate alpha_theta(s, a) = g(r_theta(s, a)) in the range [0, 1]. Unlike prior work that applies rejection sampling as a data-level heuristic before training, RGPO elevates rejection to an optimization principle: the gate participates directly in gradient computation and is implicitly updated alongside the policy. RGPO provides a unified framework: the policy gradients of TRPO, PPO, and REINFORCE all correspond to specific choices of the effective gradient weight w(r) = g'(r) * r. We prove that RGPO guarantees finite, bounded gradient variance even when importance sampling ratios are heavy-tailed (where IS variance diverges). We further show that RGPO incurs only a bounded, controllable bias and provides an approximate monotonic policy improvement guarantee analogous to TRPO. RGPO matches PPO in computational cost, requires no second-order optimization, and extends naturally to RLHF-style preference alignment. In online preference fine-tuning of Qwen2.5-1.5B-Instruct on Anthropic HH-RLHF (n = 3 seeds), RGPO uses a dual-ratio gate that anchors learning to both the previous policy and the reference model, achieving a Pareto-dominant outcome: the highest reward among online RL methods (+14.8% vs. PPO-RLHF) and the lowest KL divergence to the reference model (-16.0% vs. PPO-RLHF, -53.1% vs. GRPO).
SAM-DAQ: Segment Anything Model with Depth-guided Adaptive Queries for RGB-D Video Salient Object Detection
Nov 13, 2025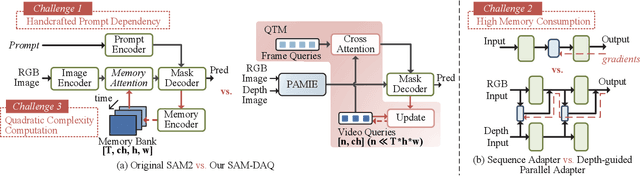
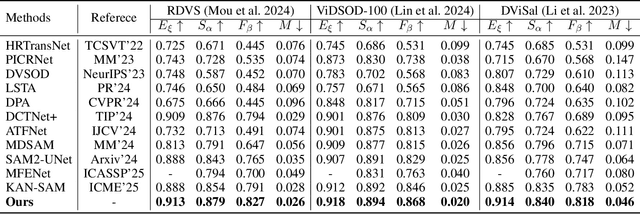
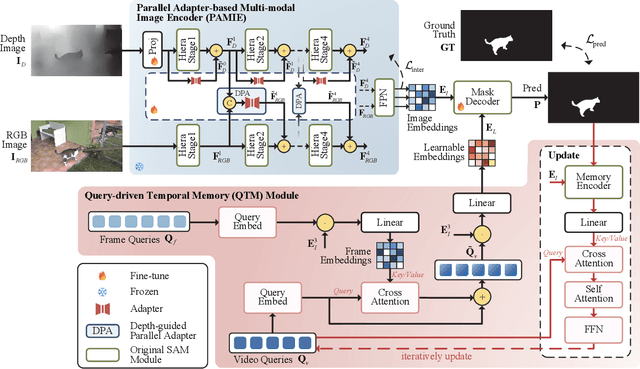
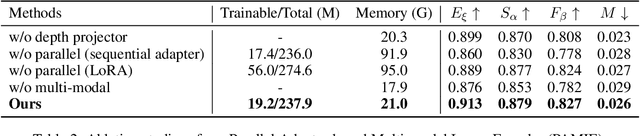
Recently segment anything model (SAM) has attracted widespread concerns, and it is often treated as a vision foundation model for universal segmentation. Some researchers have attempted to directly apply the foundation model to the RGB-D video salient object detection (RGB-D VSOD) task, which often encounters three challenges, including the dependence on manual prompts, the high memory consumption of sequential adapters, and the computational burden of memory attention. To address the limitations, we propose a novel method, namely Segment Anything Model with Depth-guided Adaptive Queries (SAM-DAQ), which adapts SAM2 to pop-out salient objects from videos by seamlessly integrating depth and temporal cues within a unified framework. Firstly, we deploy a parallel adapter-based multi-modal image encoder (PAMIE), which incorporates several depth-guided parallel adapters (DPAs) in a skip-connection way. Remarkably, we fine-tune the frozen SAM encoder under prompt-free conditions, where the DPA utilizes depth cues to facilitate the fusion of multi-modal features. Secondly, we deploy a query-driven temporal memory (QTM) module, which unifies the memory bank and prompt embeddings into a learnable pipeline. Concretely, by leveraging both frame-level queries and video-level queries simultaneously, the QTM module can not only selectively extract temporal consistency features but also iteratively update the temporal representations of the queries. Extensive experiments are conducted on three RGB-D VSOD datasets, and the results show that the proposed SAM-DAQ consistently outperforms state-of-the-art methods in terms of all evaluation metrics.
It Takes Two: Accurate Gait Recognition in the Wild via Cross-granularity Alignment
Nov 16, 2024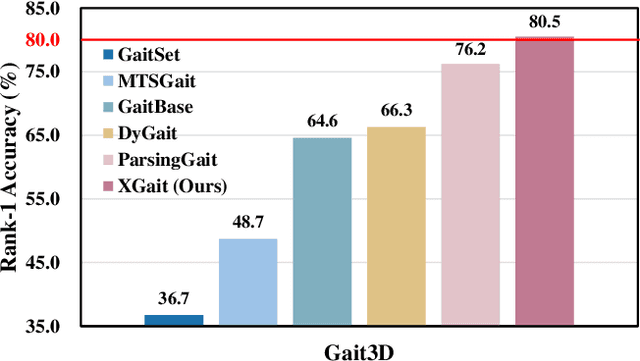
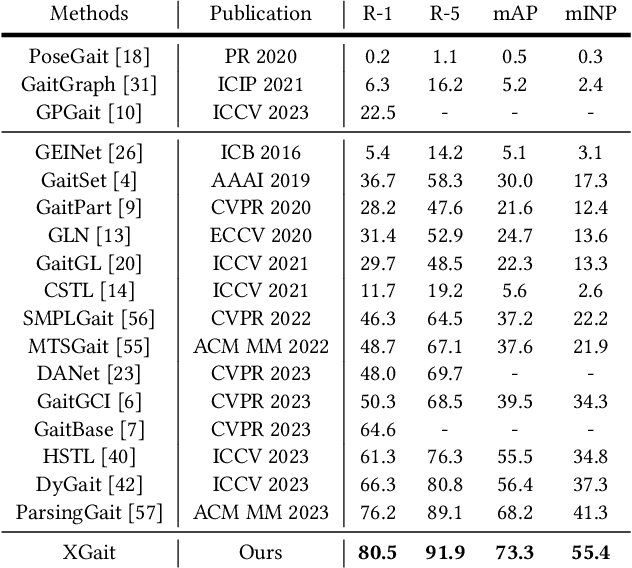
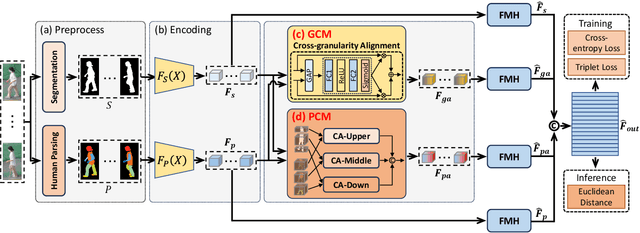
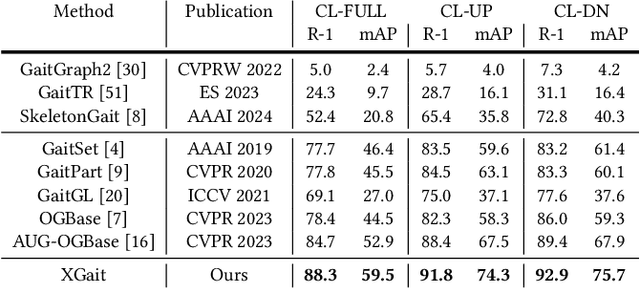
Existing studies for gait recognition primarily utilized sequences of either binary silhouette or human parsing to encode the shapes and dynamics of persons during walking. Silhouettes exhibit accurate segmentation quality and robustness to environmental variations, but their low information entropy may result in sub-optimal performance. In contrast, human parsing provides fine-grained part segmentation with higher information entropy, but the segmentation quality may deteriorate due to the complex environments. To discover the advantages of silhouette and parsing and overcome their limitations, this paper proposes a novel cross-granularity alignment gait recognition method, named XGait, to unleash the power of gait representations of different granularity. To achieve this goal, the XGait first contains two branches of backbone encoders to map the silhouette sequences and the parsing sequences into two latent spaces, respectively. Moreover, to explore the complementary knowledge across the features of two representations, we design the Global Cross-granularity Module (GCM) and the Part Cross-granularity Module (PCM) after the two encoders. In particular, the GCM aims to enhance the quality of parsing features by leveraging global features from silhouettes, while the PCM aligns the dynamics of human parts between silhouette and parsing features using the high information entropy in parsing sequences. In addition, to effectively guide the alignment of two representations with different granularity at the part level, an elaborate-designed learnable division mechanism is proposed for the parsing features. Comprehensive experiments on two large-scale gait datasets not only show the superior performance of XGait with the Rank-1 accuracy of 80.5% on Gait3D and 88.3% CCPG but also reflect the robustness of the learned features even under challenging conditions like occlusions and cloth changes.
Quality-aware Selective Fusion Network for V-D-T Salient Object Detection
May 13, 2024Depth images and thermal images contain the spatial geometry information and surface temperature information, which can act as complementary information for the RGB modality. However, the quality of the depth and thermal images is often unreliable in some challenging scenarios, which will result in the performance degradation of the two-modal based salient object detection (SOD). Meanwhile, some researchers pay attention to the triple-modal SOD task, where they attempt to explore the complementarity of the RGB image, the depth image, and the thermal image. However, existing triple-modal SOD methods fail to perceive the quality of depth maps and thermal images, which leads to performance degradation when dealing with scenes with low-quality depth and thermal images. Therefore, we propose a quality-aware selective fusion network (QSF-Net) to conduct VDT salient object detection, which contains three subnets including the initial feature extraction subnet, the quality-aware region selection subnet, and the region-guided selective fusion subnet. Firstly, except for extracting features, the initial feature extraction subnet can generate a preliminary prediction map from each modality via a shrinkage pyramid architecture. Then, we design the weakly-supervised quality-aware region selection subnet to generate the quality-aware maps. Concretely, we first find the high-quality and low-quality regions by using the preliminary predictions, which further constitute the pseudo label that can be used to train this subnet. Finally, the region-guided selective fusion subnet purifies the initial features under the guidance of the quality-aware maps, and then fuses the triple-modal features and refines the edge details of prediction maps through the intra-modality and inter-modality attention (IIA) module and the edge refinement (ER) module, respectively. Extensive experiments are performed on VDT-2048
A hybrid controller for safe and efficient collision avoidance control
Mar 29, 2021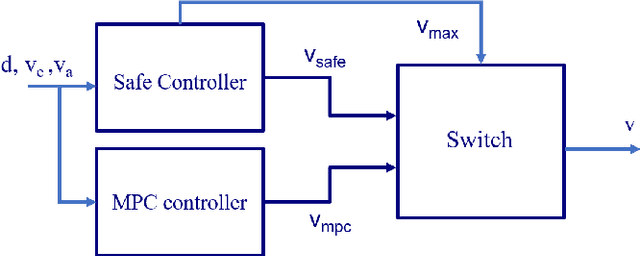
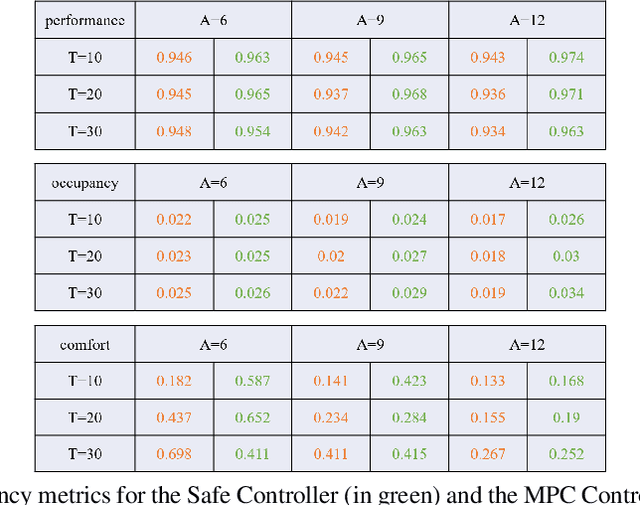
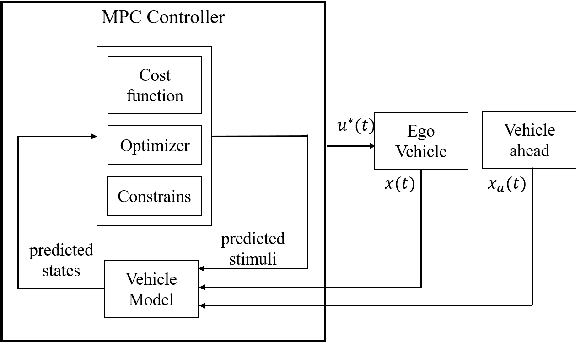
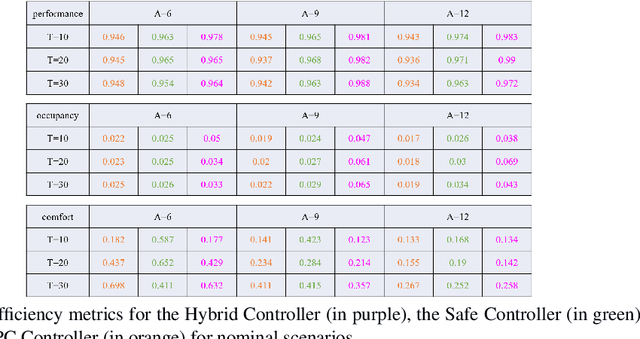
We design and experimentally evaluate a hybrid safe-by-construction collision avoidance controller for autonomous vehicles. The controller combines into a single architecture the respective advantages of an adaptive controller and a discrete safe controller. The adaptive controller relies on model predictive control to achieve optimal efficiency in nominal conditions. The safe controller avoids collision by applying two different policies, for nominal and out-of-nominal conditions, respectively. We present design principles for both the adaptive and the safe controller and show how each one can contribute in the hybrid architecture to improve performance, road occupancy and passenger comfort while preserving safety. The experimental results confirm the feasibility of the approach and the practical relevance of hybrid controllers for safe and efficient driving.
Automated Model Design and Benchmarking of 3D Deep Learning Models for COVID-19 Detection with Chest CT Scans
Feb 12, 2021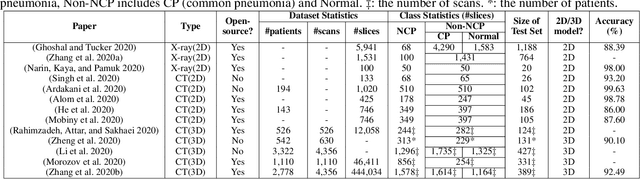
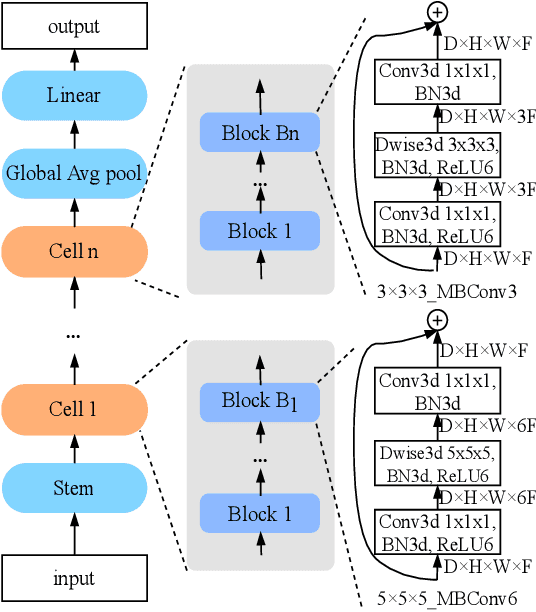
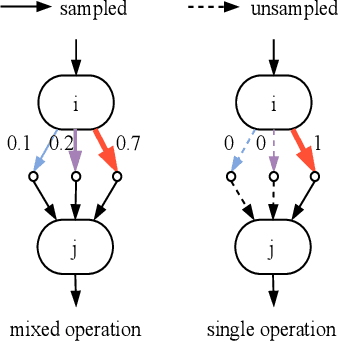
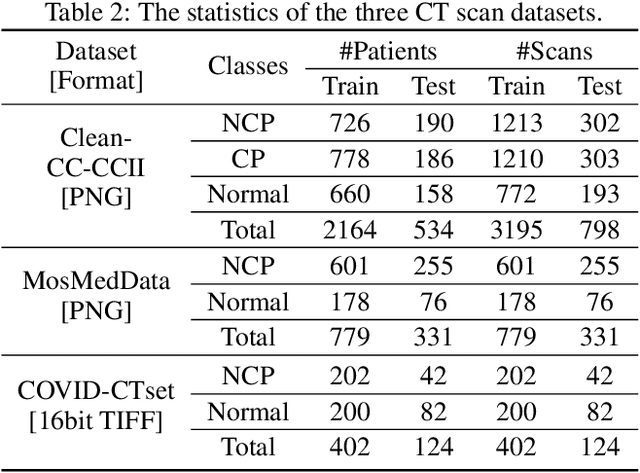
The COVID-19 pandemic has spread globally for several months. Because its transmissibility and high pathogenicity seriously threaten people's lives, it is crucial to accurately and quickly detect COVID-19 infection. Many recent studies have shown that deep learning (DL) based solutions can help detect COVID-19 based on chest CT scans. However, most existing work focuses on 2D datasets, which may result in low quality models as the real CT scans are 3D images. Besides, the reported results span a broad spectrum on different datasets with a relatively unfair comparison. In this paper, we first use three state-of-the-art 3D models (ResNet3D101, DenseNet3D121, and MC3\_18) to establish the baseline performance on the three publicly available chest CT scan datasets. Then we propose a differentiable neural architecture search (DNAS) framework to automatically search for the 3D DL models for 3D chest CT scans classification with the Gumbel Softmax technique to improve the searching efficiency. We further exploit the Class Activation Mapping (CAM) technique on our models to provide the interpretability of the results. The experimental results show that our automatically searched models (CovidNet3D) outperform the baseline human-designed models on the three datasets with tens of times smaller model size and higher accuracy. Furthermore, the results also verify that CAM can be well applied in CovidNet3D for COVID-19 datasets to provide interpretability for medical diagnosis.
TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition
Feb 09, 2021
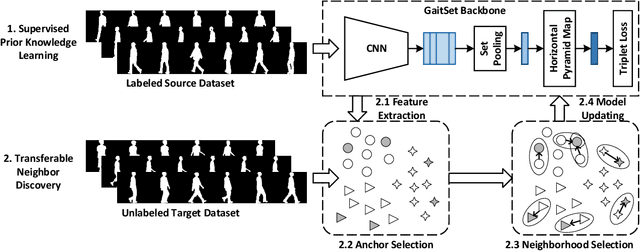
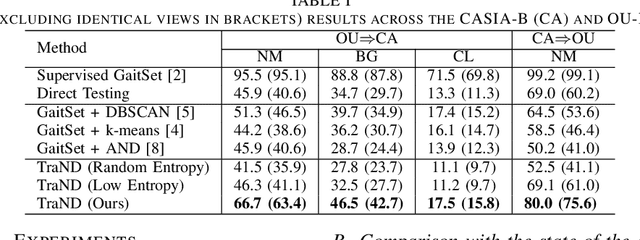
Gait, i.e., the movement pattern of human limbs during locomotion, is a promising biometric for the identification of persons. Despite significant improvement in gait recognition with deep learning, existing studies still neglect a more practical but challenging scenario -- unsupervised cross-domain gait recognition which aims to learn a model on a labeled dataset then adapts it to an unlabeled dataset. Due to the domain shift and class gap, directly applying a model trained on one source dataset to other target datasets usually obtains very poor results. Therefore, this paper proposes a Transferable Neighborhood Discovery (TraND) framework to bridge the domain gap for unsupervised cross-domain gait recognition. To learn effective prior knowledge for gait representation, we first adopt a backbone network pre-trained on the labeled source data in a supervised manner. Then we design an end-to-end trainable approach to automatically discover the confident neighborhoods of unlabeled samples in the latent space. During training, the class consistency indicator is adopted to select confident neighborhoods of samples based on their entropy measurements. Moreover, we explore a high-entropy-first neighbor selection strategy, which can effectively transfer prior knowledge to the target domain. Our method achieves state-of-the-art results on two public datasets, i.e., CASIA-B and OU-LP.
Efficient Multi-objective Evolutionary 3D Neural Architecture Search for COVID-19 Detection with Chest CT Scans
Jan 26, 2021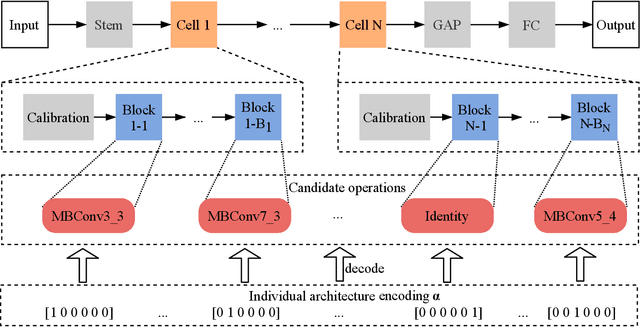
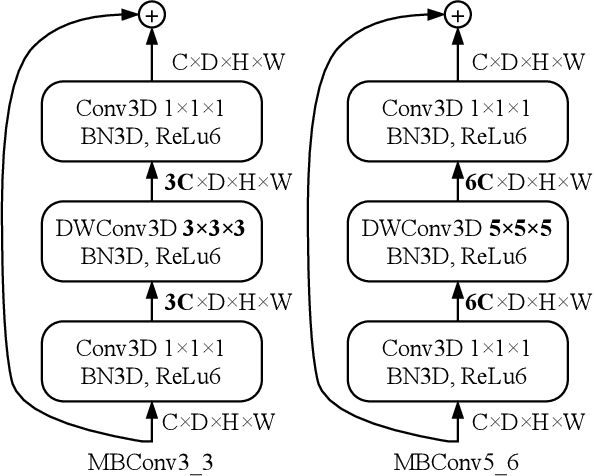

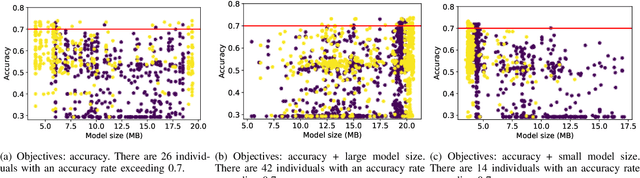
COVID-19 pandemic has spread globally for months. Due to its long incubation period and high testing cost, there is no clue showing its spread speed is slowing down, and hence a faster testing method is in dire need. This paper proposes an efficient Evolutionary Multi-objective neural ARchitecture Search (EMARS) framework, which can automatically search for 3D neural architectures based on a well-designed search space for COVID-19 chest CT scan classification. Within the framework, we use weight sharing strategy to significantly improve the search efficiency and finish the search process in 8 hours. We also propose a new objective, namely potential, which is of benefit to improve the search process's robustness. With the objectives of accuracy, potential, and model size, we find a lightweight model (3.39 MB), which outperforms three baseline human-designed models, i.e., ResNet3D101 (325.21 MB), DenseNet3D121 (43.06 MB), and MC3\_18 (43.84 MB). Besides, our well-designed search space enables the class activation mapping algorithm to be easily embedded into all searched models, which can provide the interpretability for medical diagnosis by visualizing the judgment based on the models to locate the lesion areas.
AdvExpander: Generating Natural Language Adversarial Examples by Expanding Text
Dec 18, 2020
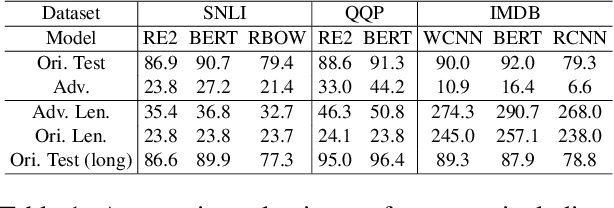
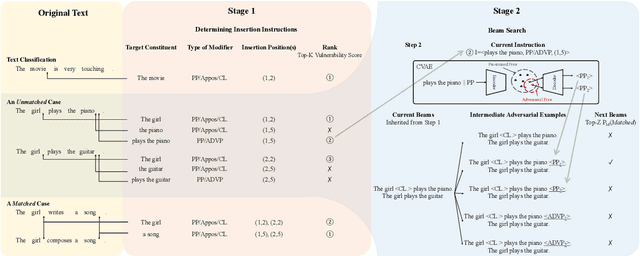
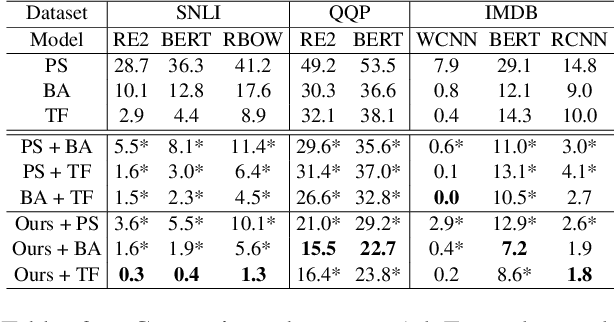
Adversarial examples are vital to expose the vulnerability of machine learning models. Despite the success of the most popular substitution-based methods which substitutes some characters or words in the original examples, only substitution is insufficient to uncover all robustness issues of models. In this paper, we present AdvExpander, a method that crafts new adversarial examples by expanding text, which is complementary to previous substitution-based methods. We first utilize linguistic rules to determine which constituents to expand and what types of modifiers to expand with. We then expand each constituent by inserting an adversarial modifier searched from a CVAE-based generative model which is pre-trained on a large scale corpus. To search adversarial modifiers, we directly search adversarial latent codes in the latent space without tuning the pre-trained parameters. To ensure that our adversarial examples are label-preserving for text matching, we also constrain the modifications with a heuristic rule. Experiments on three classification tasks verify the effectiveness of AdvExpander and the validity of our adversarial examples. AdvExpander crafts a new type of adversarial examples by text expansion, thereby promising to reveal new robustness issues.
Lane detection in complex scenes based on end-to-end neural network
Oct 26, 2020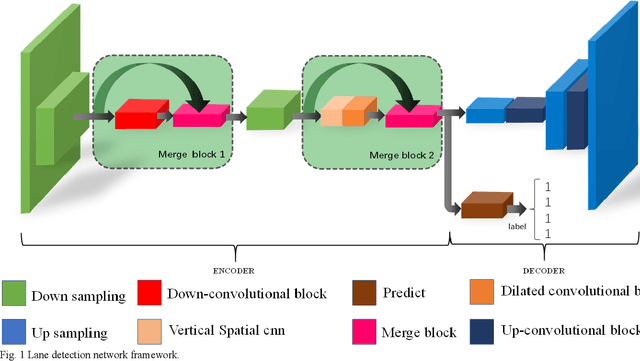
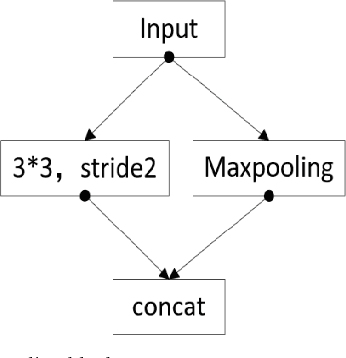
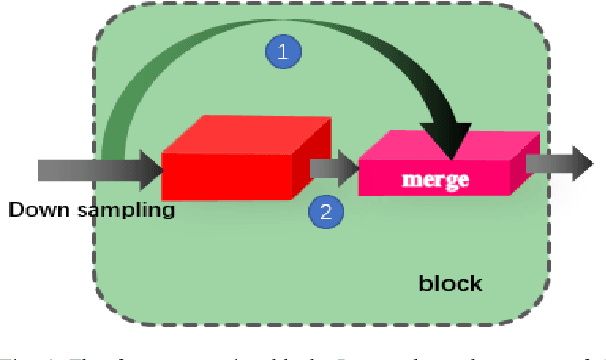

The lane detection is a key problem to solve the division of derivable areas in unmanned driving, and the detection accuracy of lane lines plays an important role in the decision-making of vehicle driving. Scenes faced by vehicles in daily driving are relatively complex. Bright light, insufficient light, and crowded vehicles will bring varying degrees of difficulty to lane detection. So we combine the advantages of spatial convolution in spatial information processing and the efficiency of ERFNet in semantic segmentation, propose an end-to-end network to lane detection in a variety of complex scenes. And we design the information exchange block by combining spatial convolution and dilated convolution, which plays a great role in understanding detailed information. Finally, our network was tested on the CULane database and its F1-measure with IOU threshold of 0.5 can reach 71.9%.