 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReframing Long-Tailed Learning via Loss Landscape Geometry
Mar 22, 2026Balancing performance trade-off on long-tail (LT) data distributions remains a long-standing challenge. In this paper, we posit that this dilemma stems from a phenomenon called "tail performance degradation" (the model tends to severely overfit on head classes while quickly forgetting tail classes) and pose a solution from a loss landscape perspective. We observe that different classes possess divergent convergence points in the loss landscape. Besides, this divergence is aggravated when the model settles into sharp and non-robust minima, rather than a shared and flat solution that is beneficial for all classes. In light of this, we propose a continual learning inspired framework to prevent "tail performance degradation". To avoid inefficient per-class parameter preservation, a Grouped Knowledge Preservation module is proposed to memorize group-specific convergence parameters, promoting convergence towards a shared solution. Concurrently, our framework integrates a Grouped Sharpness Aware module to seek flatter minima by explicitly addressing the geometry of the loss landscape. Notably, our framework requires neither external training samples nor pre-trained models, facilitating the broad applicability. Extensive experiments on four benchmarks demonstrate significant performance gains over state-of-the-art methods. The code is available at:https://gkp-gsa.github.io/.
A Conditional Probability Framework for Compositional Zero-shot Learning
Jul 23, 2025Compositional Zero-Shot Learning (CZSL) aims to recognize unseen combinations of known objects and attributes by leveraging knowledge from previously seen compositions. Traditional approaches primarily focus on disentangling attributes and objects, treating them as independent entities during learning. However, this assumption overlooks the semantic constraints and contextual dependencies inside a composition. For example, certain attributes naturally pair with specific objects (e.g., "striped" applies to "zebra" or "shirts" but not "sky" or "water"), while the same attribute can manifest differently depending on context (e.g., "young" in "young tree" vs. "young dog"). Thus, capturing attribute-object interdependence remains a fundamental yet long-ignored challenge in CZSL. In this paper, we adopt a Conditional Probability Framework (CPF) to explicitly model attribute-object dependencies. We decompose the probability of a composition into two components: the likelihood of an object and the conditional likelihood of its attribute. To enhance object feature learning, we incorporate textual descriptors to highlight semantically relevant image regions. These enhanced object features then guide attribute learning through a cross-attention mechanism, ensuring better contextual alignment. By jointly optimizing object likelihood and conditional attribute likelihood, our method effectively captures compositional dependencies and generalizes well to unseen compositions. Extensive experiments on multiple CZSL benchmarks demonstrate the superiority of our approach. Code is available at here.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025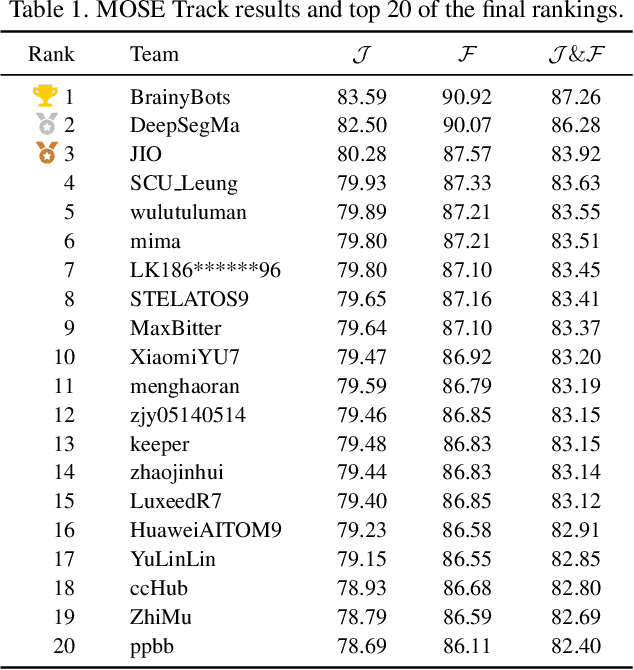
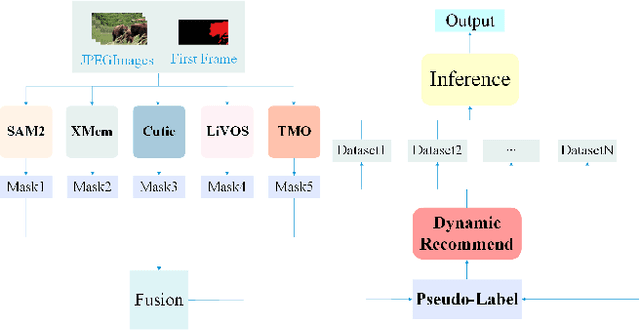
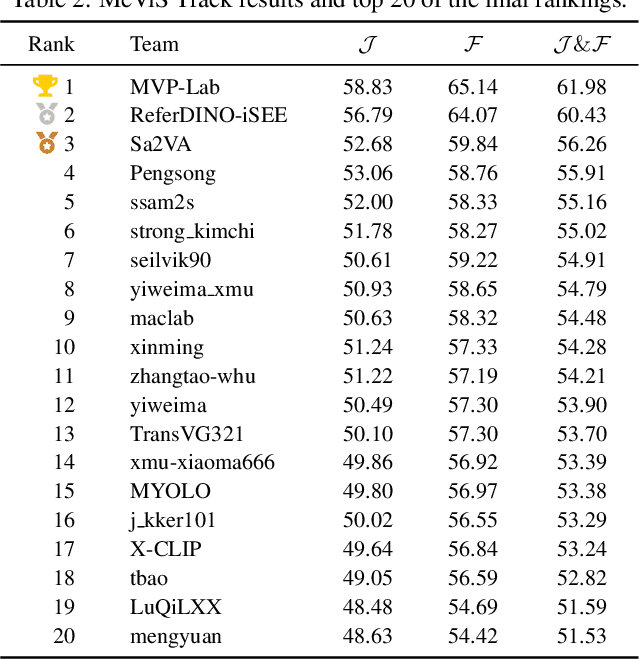
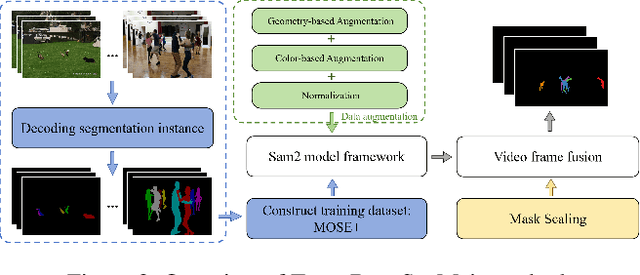
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
The 1st Solution for 4th PVUW MeViS Challenge: Unleashing the Potential of Large Multimodal Models for Referring Video Segmentation
Apr 07, 2025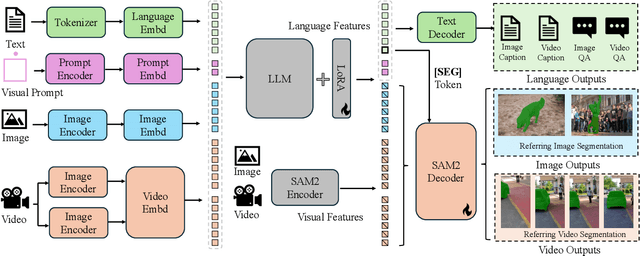
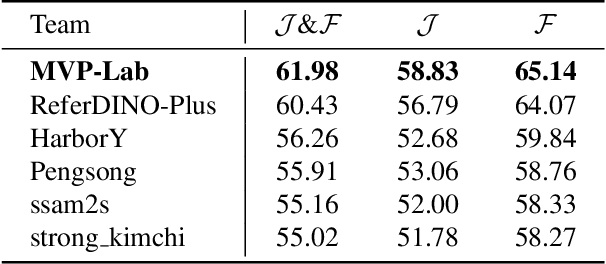
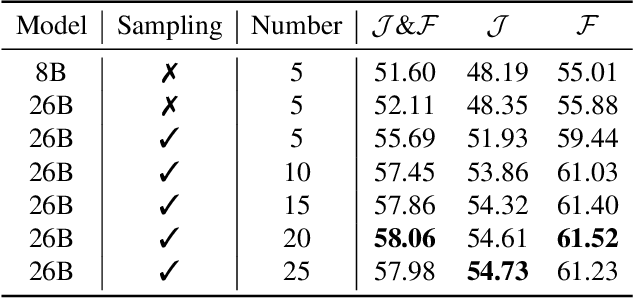

Motion expression video segmentation is designed to segment objects in accordance with the input motion expressions. In contrast to the conventional Referring Video Object Segmentation (RVOS), it places emphasis on motion as well as multi-object expressions, making it more arduous. Recently, Large Multimodal Models (LMMs) have begun to shine in RVOS due to their powerful vision-language perception capabilities. In this work, we propose a simple and effective inference optimization method to fully unleash the potential of LMMs in referring video segmentation. Firstly, we use Sa2VA as our baseline, which is a unified LMM for dense grounded understanding of both images and videos. Secondly, we uniformly sample the video frames during the inference process to enhance the model's understanding of the entire video. Finally, we integrate the results of multiple expert models to mitigate the erroneous predictions of a single model. Our solution achieved 61.98% J&F on the MeViS test set and ranked 1st place in the 4th PVUW Challenge MeViS Track at CVPR 2025.
LSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
UNINEXT-Cutie: The 1st Solution for LSVOS Challenge RVOS Track
Aug 19, 2024Referring video object segmentation (RVOS) relies on natural language expressions to segment target objects in video. In this year, LSVOS Challenge RVOS Track replaced the origin YouTube-RVOS benchmark with MeViS. MeViS focuses on referring the target object in a video through its motion descriptions instead of static attributes, posing a greater challenge to RVOS task. In this work, we integrate strengths of that leading RVOS and VOS models to build up a simple and effective pipeline for RVOS. Firstly, We finetune the state-of-the-art RVOS model to obtain mask sequences that are correlated with language descriptions. Secondly, based on a reliable and high-quality key frames, we leverage VOS model to enhance the quality and temporal consistency of the mask results. Finally, we further improve the performance of the RVOS model using semi-supervised learning. Our solution achieved 62.57 J&F on the MeViS test set and ranked 1st place for 6th LSVOS Challenge RVOS Track.
Video Object Segmentation via SAM 2: The 4th Solution for LSVOS Challenge VOS Track
Aug 19, 2024Video Object Segmentation (VOS) task aims to segmenting a particular object instance throughout the entire video sequence given only the object mask of the first frame. Recently, Segment Anything Model 2 (SAM 2) is proposed, which is a foundation model towards solving promptable visual segmentation in images and videos. SAM 2 builds a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. SAM 2 is a simple transformer architecture with streaming memory for real-time video processing, which trained on the date provides strong performance across a wide range of tasks. In this work, we evaluate the zero-shot performance of SAM 2 on the more challenging VOS datasets MOSE and LVOS. Without fine-tuning on the training set, SAM 2 achieved 75.79 J&F on the test set and ranked 4th place for 6th LSVOS Challenge VOS Track.
Unified Embedding Alignment for Open-Vocabulary Video Instance Segmentation
Jul 10, 2024



Open-Vocabulary Video Instance Segmentation (VIS) is attracting increasing attention due to its ability to segment and track arbitrary objects. However, the recent Open-Vocabulary VIS attempts obtained unsatisfactory results, especially in terms of generalization ability of novel categories. We discover that the domain gap between the VLM features (e.g., CLIP) and the instance queries and the underutilization of temporal consistency are two central causes. To mitigate these issues, we design and train a novel Open-Vocabulary VIS baseline called OVFormer. OVFormer utilizes a lightweight module for unified embedding alignment between query embeddings and CLIP image embeddings to remedy the domain gap. Unlike previous image-based training methods, we conduct video-based model training and deploy a semi-online inference scheme to fully mine the temporal consistency in the video. Without bells and whistles, OVFormer achieves 21.9 mAP with a ResNet-50 backbone on LV-VIS, exceeding the previous state-of-the-art performance by 7.7. Extensive experiments on some Close-Vocabulary VIS datasets also demonstrate the strong zero-shot generalization ability of OVFormer (+ 7.6 mAP on YouTube-VIS 2019, + 3.9 mAP on OVIS). Code is available at https://github.com/fanghaook/OVFormer.
PVUW 2024 Challenge on Complex Video Understanding: Methods and Results
Jun 24, 2024



Pixel-level Video Understanding in the Wild Challenge (PVUW) focus on complex video understanding. In this CVPR 2024 workshop, we add two new tracks, Complex Video Object Segmentation Track based on MOSE dataset and Motion Expression guided Video Segmentation track based on MeViS dataset. In the two new tracks, we provide additional videos and annotations that feature challenging elements, such as the disappearance and reappearance of objects, inconspicuous small objects, heavy occlusions, and crowded environments in MOSE. Moreover, we provide a new motion expression guided video segmentation dataset MeViS to study the natural language-guided video understanding in complex environments. These new videos, sentences, and annotations enable us to foster the development of a more comprehensive and robust pixel-level understanding of video scenes in complex environments and realistic scenarios. The MOSE challenge had 140 registered teams in total, 65 teams participated the validation phase and 12 teams made valid submissions in the final challenge phase. The MeViS challenge had 225 registered teams in total, 50 teams participated the validation phase and 5 teams made valid submissions in the final challenge phase.
3rd Place Solution for MeViS Track in CVPR 2024 PVUW workshop: Motion Expression guided Video Segmentation
Jun 07, 2024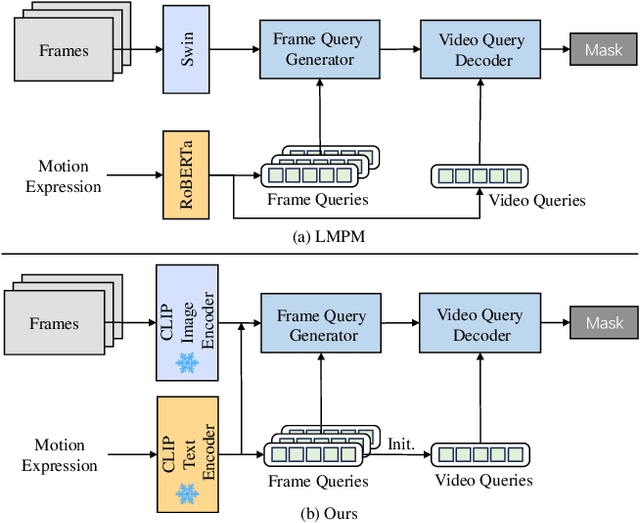
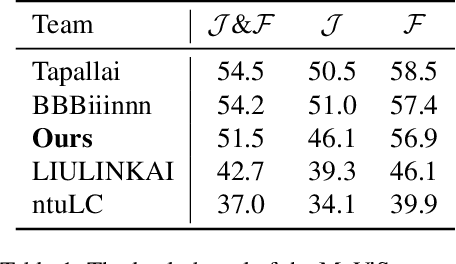
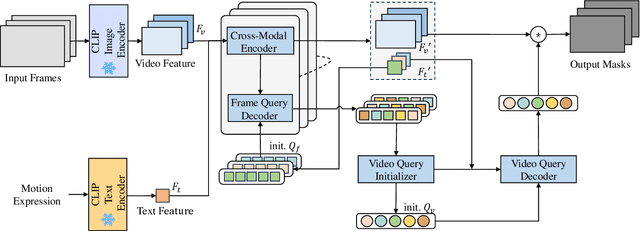

Referring video object segmentation (RVOS) relies on natural language expressions to segment target objects in video, emphasizing modeling dense text-video relations. The current RVOS methods typically use independently pre-trained vision and language models as backbones, resulting in a significant domain gap between video and text. In cross-modal feature interaction, text features are only used as query initialization and do not fully utilize important information in the text. In this work, we propose using frozen pre-trained vision-language models (VLM) as backbones, with a specific emphasis on enhancing cross-modal feature interaction. Firstly, we use frozen convolutional CLIP backbone to generate feature-aligned vision and text features, alleviating the issue of domain gap and reducing training costs. Secondly, we add more cross-modal feature fusion in the pipeline to enhance the utilization of multi-modal information. Furthermore, we propose a novel video query initialization method to generate higher quality video queries. Without bells and whistles, our method achieved 51.5 J&F on the MeViS test set and ranked 3rd place for MeViS Track in CVPR 2024 PVUW workshop: Motion Expression guided Video Segmentation.