 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 1st Solution for 4th PVUW MeViS Challenge: Unleashing the Potential of Large Multimodal Models for Referring Video Segmentation
Paper and Code
Apr 07, 2025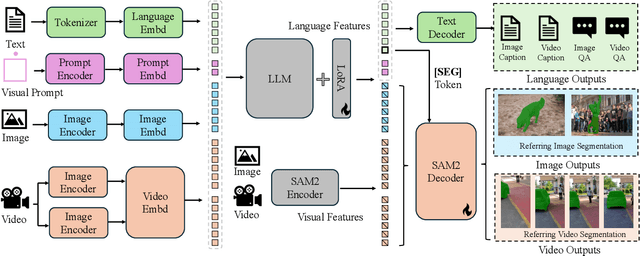
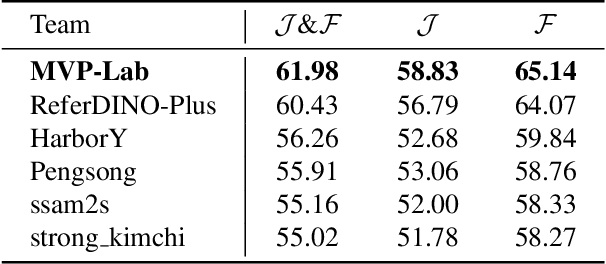
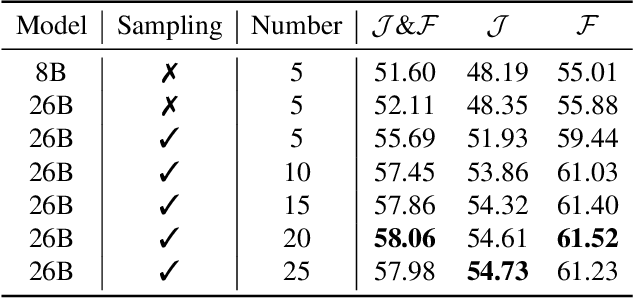

Motion expression video segmentation is designed to segment objects in accordance with the input motion expressions. In contrast to the conventional Referring Video Object Segmentation (RVOS), it places emphasis on motion as well as multi-object expressions, making it more arduous. Recently, Large Multimodal Models (LMMs) have begun to shine in RVOS due to their powerful vision-language perception capabilities. In this work, we propose a simple and effective inference optimization method to fully unleash the potential of LMMs in referring video segmentation. Firstly, we use Sa2VA as our baseline, which is a unified LMM for dense grounded understanding of both images and videos. Secondly, we uniformly sample the video frames during the inference process to enhance the model's understanding of the entire video. Finally, we integrate the results of multiple expert models to mitigate the erroneous predictions of a single model. Our solution achieved 61.98% J&F on the MeViS test set and ranked 1st place in the 4th PVUW Challenge MeViS Track at CVPR 2025.