 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching AI Through Benchmark Construction: QuestBench as a Course-Based Practice for Accountable Knowledge Work
May 21, 2026As AI becomes part of everyday learning, many courses teach students to use it mainly as a productivity tool: how to prompt, search, summarize, write, code, and use tools more efficiently. We argue that AI education also needs a setting in which students learn to test AI and understand their own role in judging machine-produced knowledge. To this end, we introduce a course-based practice that teaches AI through benchmark construction, using deep research systems as a concrete example of AI-era knowledge work. Students turn disciplinary knowledge into verifiable expert-level questions, review one another's designs for ambiguity and shortcuts, and evaluate AI systems on the resulting tasks. This activity gives students direct exposure to a powerful tool while asking them to specify what a trustworthy answer would require. The produced benchmark, QuestBench, consists of 256 questions across 14 humanities and social-science domains. Evaluation on QuestBench shows that student-designed tasks reveal hidden failures in current deep research systems: across thirteen evaluated systems, the mean question-level pass rate is only 16.85%, and the best-performing system, GPT-5.5, reaches a 57.58% pass rate. The failures are educationally useful because they show how fluent, source-backed answers can still miss the right query, source, term, or evidence standard. Reflections from five student contributors suggest that benchmark construction can help students see professional knowledge not only as content AI may retrieve, but as the basis for judging AI outputs. We present QuestBench as a benchmark artifact and as a reusable classroom setting for a larger educational question: how students can remain responsible knowledge actors as AI enters learning and professional work. The dataset is available at https://huggingface.co/datasets/PKUAIWeb/QuestBench/tree/main.
The Last Human-Written Paper: Agent-Native Research Artifacts
Apr 27, 2026Scientific publication compresses a branching, iterative research process into a linear narrative, discarding the majority of what was discovered along the way. This compilation imposes two structural costs: a Storytelling Tax, where failed experiments, rejected hypotheses, and the branching exploration process are discarded to fit a linear narrative; and an Engineering Tax, where the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten. Tolerable for human readers, these costs become critical when AI agents must understand, reproduce, and extend published work. We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers: scientific logic, executable code with full specifications, an exploration graph that preserves the failures compilation discards, and evidence grounding every claim in raw outputs. Three mechanisms support the ecosystem: a Live Research Manager that captures decisions and dead ends during ordinary development; an Ara Compiler that translates legacy PDFs and repos into Aras; and an Ara-native review system that automates objective checks so human reviewers can focus on significance, novelty, and taste. On PaperBench and RE-Bench, Ara raises question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4%. On RE-Bench's five open-ended extension tasks, preserved failure traces in Ara accelerate progress, but can also constrain a capable agent from stepping outside the prior-run box depending on the agent's capabilities.
GBQA: A Game Benchmark for Evaluating LLMs as Quality Assurance Engineers
Apr 03, 2026The autonomous discovery of bugs remains a significant challenge in modern software development. Compared to code generation, the complexity of dynamic runtime environments makes bug discovery considerably harder for large language models (LLMs). In this paper, we take game development as a representative domain and introduce the Game Benchmark for Quality Assurance (GBQA), a benchmark containing 30 games and 124 human-verified bugs across three difficulty levels, to evaluate whether LLMs can autonomously detect software bugs. The benchmark is constructed using a multi-agent system that develops games and injects bugs in a scalable manner, with human experts in the loop to ensure correctness. Moreover, we provide a baseline interactive agent equipped with a multi-round ReAct loop and a memory mechanism, enabling long-horizon exploration of game environments for bug detection across different LLMs. Extensive experiments on frontier LLMs demonstrate that autonomous bug discovery remains highly challenging: the best-performing model, Claude-4.6-Opus in thinking mode, identifies only 48.39% of the verified bugs. We believe GBQA provides an adequate testbed and evaluation criterion, and that further progress on it will help close the gap in autonomous software engineering.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Minimum-Cost Network Flow with Dual Predictions
Jan 28, 2026Recent work has shown that machine-learned predictions can provably improve the performance of classic algorithms. In this work, we propose the first minimum-cost network flow algorithm augmented with a dual prediction. Our method is based on a classic minimum-cost flow algorithm, namely $\varepsilon$-relaxation. We provide time complexity bounds in terms of the infinity norm prediction error, which is both consistent and robust. We also prove sample complexity bounds for PAC-learning the prediction. We empirically validate our theoretical results on two applications of minimum-cost flow, i.e., traffic networks and chip escape routing, in which we learn a fixed prediction, and a feature-based neural network model to infer the prediction, respectively. Experimental results illustrate $12.74\times$ and $1.64\times$ average speedup on two applications.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
Empowering DINO Representations for Underwater Instance Segmentation via Aligner and Prompter
Nov 11, 2025Underwater instance segmentation (UIS), integrating pixel-level understanding and instance-level discrimination, is a pivotal technology in marine resource exploration and ecological protection. In recent years, large-scale pretrained visual foundation models, exemplified by DINO, have advanced rapidly and demonstrated remarkable performance on complex downstream tasks. In this paper, we demonstrate that DINO can serve as an effective feature learner for UIS, and we introduce DiveSeg, a novel framework built upon two insightful components: (1) The AquaStyle Aligner, designed to embed underwater color style features into the DINO fine-tuning process, facilitating better adaptation to the underwater domain. (2) The ObjectPrior Prompter, which incorporates binary segmentation-based prompts to deliver object-level priors, provides essential guidance for instance segmentation task that requires both object- and instance-level reasoning. We conduct thorough experiments on the popular UIIS and USIS10K datasets, and the results show that DiveSeg achieves the state-of-the-art performance. Code: https://github.com/ettof/Diveseg.
From Seeing to Predicting: A Vision-Language Framework for Trajectory Forecasting and Controlled Video Generation
Oct 01, 2025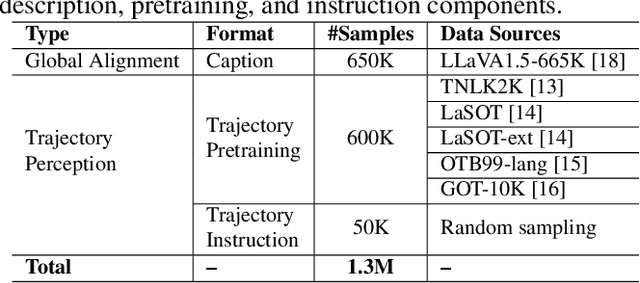
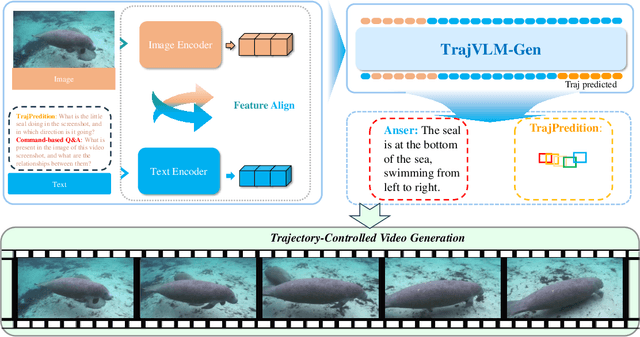
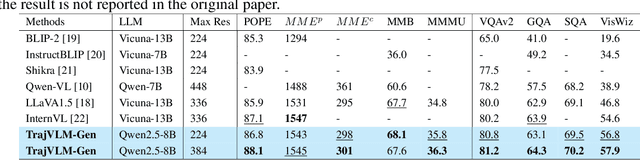

Current video generation models produce physically inconsistent motion that violates real-world dynamics. We propose TrajVLM-Gen, a two-stage framework for physics-aware image-to-video generation. First, we employ a Vision Language Model to predict coarse-grained motion trajectories that maintain consistency with real-world physics. Second, these trajectories guide video generation through attention-based mechanisms for fine-grained motion refinement. We build a trajectory prediction dataset based on video tracking data with realistic motion patterns. Experiments on UCF-101 and MSR-VTT demonstrate that TrajVLM-Gen outperforms existing methods, achieving competitive FVD scores of 545 on UCF-101 and 539 on MSR-VTT.
InfLVG: Reinforce Inference-Time Consistent Long Video Generation with GRPO
May 23, 2025Recent advances in text-to-video generation, particularly with autoregressive models, have enabled the synthesis of high-quality videos depicting individual scenes. However, extending these models to generate long, cross-scene videos remains a significant challenge. As the context length grows during autoregressive decoding, computational costs rise sharply, and the model's ability to maintain consistency and adhere to evolving textual prompts deteriorates. We introduce InfLVG, an inference-time framework that enables coherent long video generation without requiring additional long-form video data. InfLVG leverages a learnable context selection policy, optimized via Group Relative Policy Optimization (GRPO), to dynamically identify and retain the most semantically relevant context throughout the generation process. Instead of accumulating the entire generation history, the policy ranks and selects the top-$K$ most contextually relevant tokens, allowing the model to maintain a fixed computational budget while preserving content consistency and prompt alignment. To optimize the policy, we design a hybrid reward function that jointly captures semantic alignment, cross-scene consistency, and artifact reduction. To benchmark performance, we introduce the Cross-scene Video Benchmark (CsVBench) along with an Event Prompt Set (EPS) that simulates complex multi-scene transitions involving shared subjects and varied actions/backgrounds. Experimental results show that InfLVG can extend video length by up to 9$\times$, achieving strong consistency and semantic fidelity across scenes. Our code is available at https://github.com/MAPLE-AIGC/InfLVG.
SLOT: Sample-specific Language Model Optimization at Test-time
May 18, 2025We propose SLOT (Sample-specific Language Model Optimization at Test-time), a novel and parameter-efficient test-time inference approach that enhances a language model's ability to more accurately respond to individual prompts. Existing Large Language Models (LLMs) often struggle with complex instructions, leading to poor performances on those not well represented among general samples. To address this, SLOT conducts few optimization steps at test-time to update a light-weight sample-specific parameter vector. It is added to the final hidden layer before the output head, and enables efficient adaptation by caching the last layer features during per-sample optimization. By minimizing the cross-entropy loss on the input prompt only, SLOT helps the model better aligned with and follow each given instruction. In experiments, we demonstrate that our method outperforms the compared models across multiple benchmarks and LLMs. For example, Qwen2.5-7B with SLOT achieves an accuracy gain of 8.6% on GSM8K from 57.54% to 66.19%, while DeepSeek-R1-Distill-Llama-70B with SLOT achieves a SOTA accuracy of 68.69% on GPQA among 70B-level models. Our code is available at https://github.com/maple-research-lab/SLOT.