 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models
May 05, 2025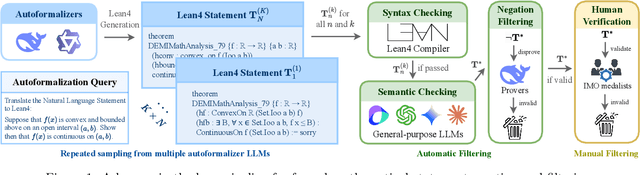

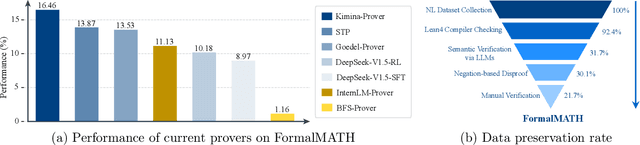

Formal mathematical reasoning remains a critical challenge for artificial intelligence, hindered by limitations of existing benchmarks in scope and scale. To address this, we present FormalMATH, a large-scale Lean4 benchmark comprising 5,560 formally verified problems spanning from high-school Olympiad challenges to undergraduate-level theorems across diverse domains (e.g., algebra, applied mathematics, calculus, number theory, and discrete mathematics). To mitigate the inefficiency of manual formalization, we introduce a novel human-in-the-loop autoformalization pipeline that integrates: (1) specialized large language models (LLMs) for statement autoformalization, (2) multi-LLM semantic verification, and (3) negation-based disproof filtering strategies using off-the-shelf LLM-based provers. This approach reduces expert annotation costs by retaining 72.09% of statements before manual verification while ensuring fidelity to the original natural-language problems. Our evaluation of state-of-the-art LLM-based theorem provers reveals significant limitations: even the strongest models achieve only 16.46% success rate under practical sampling budgets, exhibiting pronounced domain bias (e.g., excelling in algebra but failing in calculus) and over-reliance on simplified automation tactics. Notably, we identify a counterintuitive inverse relationship between natural-language solution guidance and proof success in chain-of-thought reasoning scenarios, suggesting that human-written informal reasoning introduces noise rather than clarity in the formal reasoning settings. We believe that FormalMATH provides a robust benchmark for benchmarking formal mathematical reasoning.
Patch Matters: Training-free Fine-grained Image Caption Enhancement via Local Perception
Apr 09, 2025



High-quality image captions play a crucial role in improving the performance of cross-modal applications such as text-to-image generation, text-to-video generation, and text-image retrieval. To generate long-form, high-quality captions, many recent studies have employed multimodal large language models (MLLMs). However, current MLLMs often produce captions that lack fine-grained details or suffer from hallucinations, a challenge that persists in both open-source and closed-source models. Inspired by Feature-Integration theory, which suggests that attention must focus on specific regions to integrate visual information effectively, we propose a \textbf{divide-then-aggregate} strategy. Our method first divides the image into semantic and spatial patches to extract fine-grained details, enhancing the model's local perception of the image. These local details are then hierarchically aggregated to generate a comprehensive global description. To address hallucinations and inconsistencies in the generated captions, we apply a semantic-level filtering process during hierarchical aggregation. This training-free pipeline can be applied to both open-source models (LLaVA-1.5, LLaVA-1.6, Mini-Gemini) and closed-source models (Claude-3.5-Sonnet, GPT-4o, GLM-4V-Plus). Extensive experiments demonstrate that our method generates more detailed, reliable captions, advancing multimodal description generation without requiring model retraining. The source code are available at https://github.com/GeWu-Lab/Patch-Matters
Openstory++: A Large-scale Dataset and Benchmark for Instance-aware Open-domain Visual Storytelling
Aug 07, 2024



Recent image generation models excel at creating high-quality images from brief captions. However, they fail to maintain consistency of multiple instances across images when encountering lengthy contexts. This inconsistency is largely due to in existing training datasets the absence of granular instance feature labeling in existing training datasets. To tackle these issues, we introduce Openstory++, a large-scale dataset combining additional instance-level annotations with both images and text. Furthermore, we develop a training methodology that emphasizes entity-centric image-text generation, ensuring that the models learn to effectively interweave visual and textual information. Specifically, Openstory++ streamlines the process of keyframe extraction from open-domain videos, employing vision-language models to generate captions that are then polished by a large language model for narrative continuity. It surpasses previous datasets by offering a more expansive open-domain resource, which incorporates automated captioning, high-resolution imagery tailored for instance count, and extensive frame sequences for temporal consistency. Additionally, we present Cohere-Bench, a pioneering benchmark framework for evaluating the image generation tasks when long multimodal context is provided, including the ability to keep the background, style, instances in the given context coherent. Compared to existing benchmarks, our work fills critical gaps in multi-modal generation, propelling the development of models that can adeptly generate and interpret complex narratives in open-domain environments. Experiments conducted within Cohere-Bench confirm the superiority of Openstory++ in nurturing high-quality visual storytelling models, enhancing their ability to address open-domain generation tasks. More details can be found at https://openstorypp.github.io/