 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Autoregressive Video Generation via Diagonal Distillation
Mar 11, 2026Large pretrained diffusion models have significantly enhanced the quality of generated videos, and yet their use in real-time streaming remains limited. Autoregressive models offer a natural framework for sequential frame synthesis but require heavy computation to achieve high fidelity. Diffusion distillation can compress these models into efficient few-step variants, but existing video distillation approaches largely adapt image-specific methods that neglect temporal dependencies. These techniques often excel in image generation but underperform in video synthesis, exhibiting reduced motion coherence, error accumulation over long sequences, and a latency-quality trade-off. We identify two factors that result in these limitations: insufficient utilization of temporal context during step reduction and implicit prediction of subsequent noise levels in next-chunk prediction (i.e., exposure bias). To address these issues, we propose Diagonal Distillation, which operates orthogonally to existing approaches and better exploits temporal information across both video chunks and denoising steps. Central to our approach is an asymmetric generation strategy: more steps early, fewer steps later. This design allows later chunks to inherit rich appearance information from thoroughly processed early chunks, while using partially denoised chunks as conditional inputs for subsequent synthesis. By aligning the implicit prediction of subsequent noise levels during chunk generation with the actual inference conditions, our approach mitigates error propagation and reduces oversaturation in long-range sequences. We further incorporate implicit optical flow modeling to preserve motion quality under strict step constraints. Our method generates a 5-second video in 2.61 seconds (up to 31 FPS), achieving a 277.3x speedup over the undistilled model.
Symbolic Graphics Programming with Large Language Models
Sep 05, 2025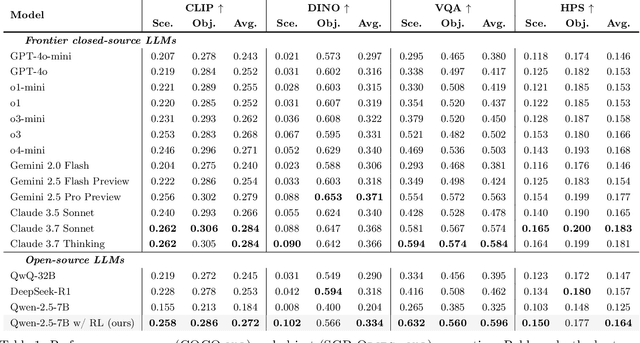
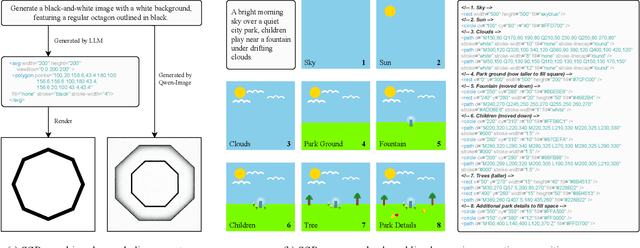
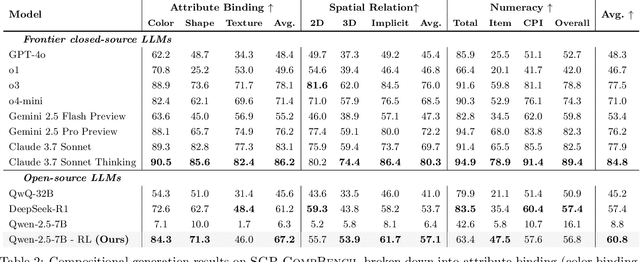
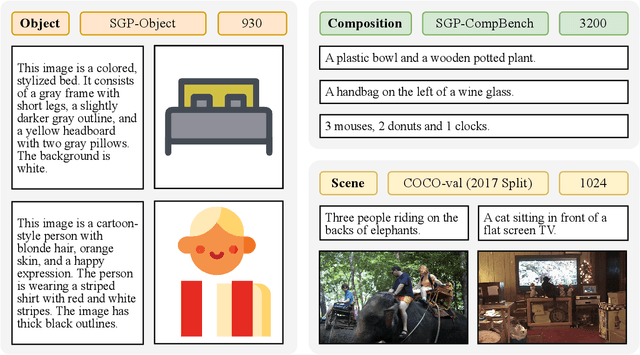
Large language models (LLMs) excel at program synthesis, yet their ability to produce symbolic graphics programs (SGPs) that render into precise visual content remains underexplored. We study symbolic graphics programming, where the goal is to generate an SGP from a natural-language description. This task also serves as a lens into how LLMs understand the visual world by prompting them to generate images rendered from SGPs. Among various SGPs, our paper sticks to scalable vector graphics (SVGs). We begin by examining the extent to which LLMs can generate SGPs. To this end, we introduce SGP-GenBench, a comprehensive benchmark covering object fidelity, scene fidelity, and compositionality (attribute binding, spatial relations, numeracy). On SGP-GenBench, we discover that frontier proprietary models substantially outperform open-source models, and performance correlates well with general coding capabilities. Motivated by this gap, we aim to improve LLMs' ability to generate SGPs. We propose a reinforcement learning (RL) with verifiable rewards approach, where a format-validity gate ensures renderable SVG, and a cross-modal reward aligns text and the rendered image via strong vision encoders (e.g., SigLIP for text-image and DINO for image-image). Applied to Qwen-2.5-7B, our method substantially improves SVG generation quality and semantics, achieving performance on par with frontier systems. We further analyze training dynamics, showing that RL induces (i) finer decomposition of objects into controllable primitives and (ii) contextual details that improve scene coherence. Our results demonstrate that symbolic graphics programming offers a precise and interpretable lens on cross-modal grounding.
FormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models
May 05, 2025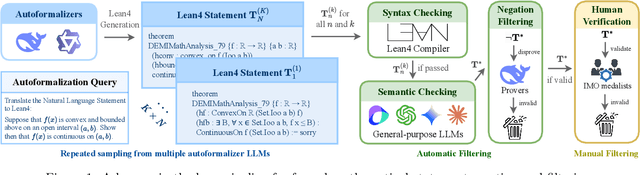

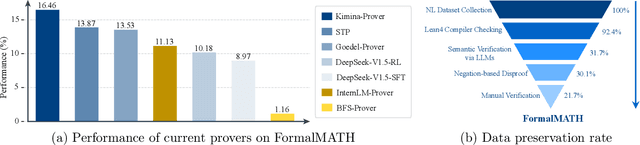

Formal mathematical reasoning remains a critical challenge for artificial intelligence, hindered by limitations of existing benchmarks in scope and scale. To address this, we present FormalMATH, a large-scale Lean4 benchmark comprising 5,560 formally verified problems spanning from high-school Olympiad challenges to undergraduate-level theorems across diverse domains (e.g., algebra, applied mathematics, calculus, number theory, and discrete mathematics). To mitigate the inefficiency of manual formalization, we introduce a novel human-in-the-loop autoformalization pipeline that integrates: (1) specialized large language models (LLMs) for statement autoformalization, (2) multi-LLM semantic verification, and (3) negation-based disproof filtering strategies using off-the-shelf LLM-based provers. This approach reduces expert annotation costs by retaining 72.09% of statements before manual verification while ensuring fidelity to the original natural-language problems. Our evaluation of state-of-the-art LLM-based theorem provers reveals significant limitations: even the strongest models achieve only 16.46% success rate under practical sampling budgets, exhibiting pronounced domain bias (e.g., excelling in algebra but failing in calculus) and over-reliance on simplified automation tactics. Notably, we identify a counterintuitive inverse relationship between natural-language solution guidance and proof success in chain-of-thought reasoning scenarios, suggesting that human-written informal reasoning introduces noise rather than clarity in the formal reasoning settings. We believe that FormalMATH provides a robust benchmark for benchmarking formal mathematical reasoning.
Patch Matters: Training-free Fine-grained Image Caption Enhancement via Local Perception
Apr 09, 2025



High-quality image captions play a crucial role in improving the performance of cross-modal applications such as text-to-image generation, text-to-video generation, and text-image retrieval. To generate long-form, high-quality captions, many recent studies have employed multimodal large language models (MLLMs). However, current MLLMs often produce captions that lack fine-grained details or suffer from hallucinations, a challenge that persists in both open-source and closed-source models. Inspired by Feature-Integration theory, which suggests that attention must focus on specific regions to integrate visual information effectively, we propose a \textbf{divide-then-aggregate} strategy. Our method first divides the image into semantic and spatial patches to extract fine-grained details, enhancing the model's local perception of the image. These local details are then hierarchically aggregated to generate a comprehensive global description. To address hallucinations and inconsistencies in the generated captions, we apply a semantic-level filtering process during hierarchical aggregation. This training-free pipeline can be applied to both open-source models (LLaVA-1.5, LLaVA-1.6, Mini-Gemini) and closed-source models (Claude-3.5-Sonnet, GPT-4o, GLM-4V-Plus). Extensive experiments demonstrate that our method generates more detailed, reliable captions, advancing multimodal description generation without requiring model retraining. The source code are available at https://github.com/GeWu-Lab/Patch-Matters
Towards Variable and Coordinated Holistic Co-Speech Motion Generation
Mar 30, 2024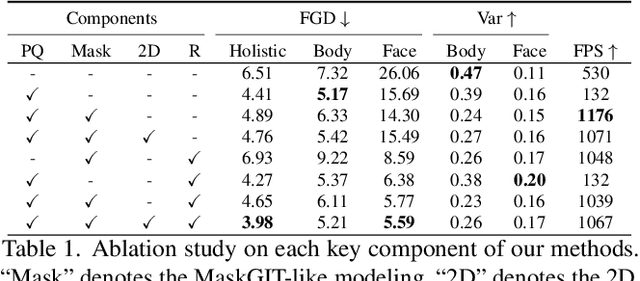
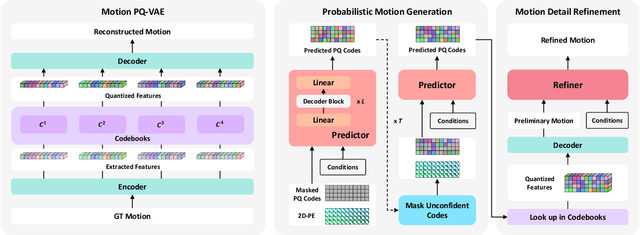
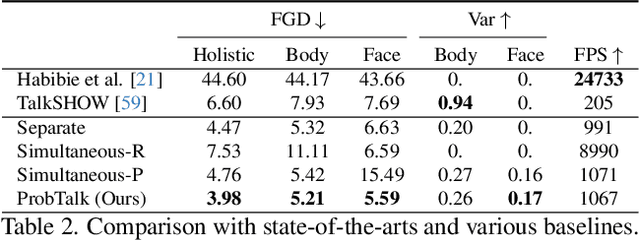
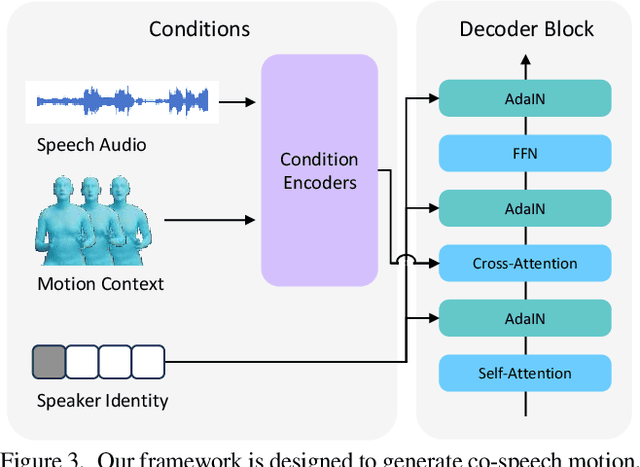
This paper addresses the problem of generating lifelike holistic co-speech motions for 3D avatars, focusing on two key aspects: variability and coordination. Variability allows the avatar to exhibit a wide range of motions even with similar speech content, while coordination ensures a harmonious alignment among facial expressions, hand gestures, and body poses. We aim to achieve both with ProbTalk, a unified probabilistic framework designed to jointly model facial, hand, and body movements in speech. ProbTalk builds on the variational autoencoder (VAE) architecture and incorporates three core designs. First, we introduce product quantization (PQ) to the VAE, which enriches the representation of complex holistic motion. Second, we devise a novel non-autoregressive model that embeds 2D positional encoding into the product-quantized representation, thereby preserving essential structure information of the PQ codes. Last, we employ a secondary stage to refine the preliminary prediction, further sharpening the high-frequency details. Coupling these three designs enables ProbTalk to generate natural and diverse holistic co-speech motions, outperforming several state-of-the-art methods in qualitative and quantitative evaluations, particularly in terms of realism. Our code and model will be released for research purposes at https://feifeifeiliu.github.io/probtalk/.
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Nov 10, 2023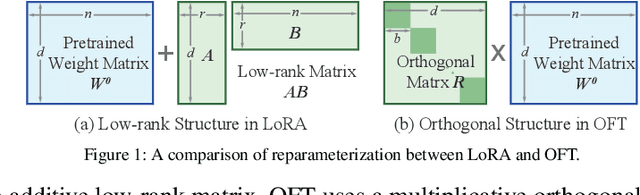
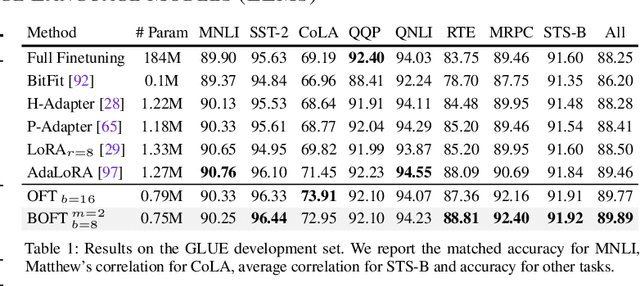
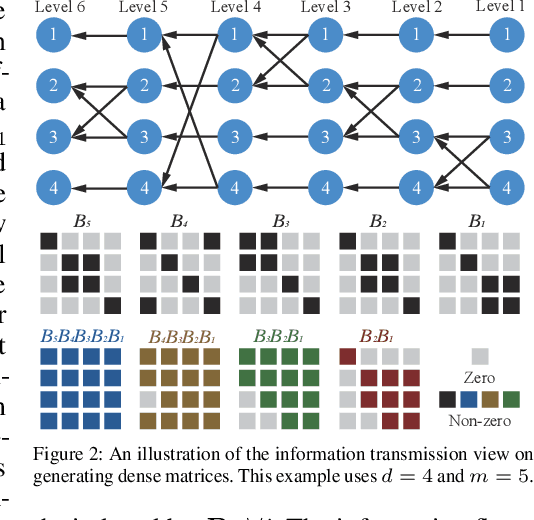
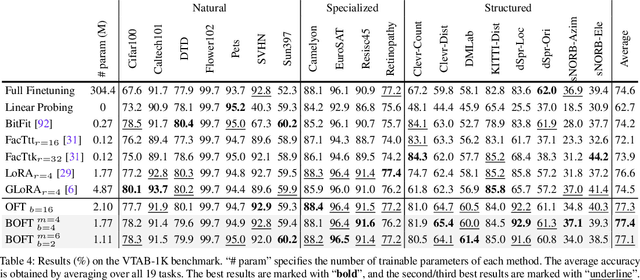
Large foundation models are becoming ubiquitous, but training them from scratch is prohibitively expensive. Thus, efficiently adapting these powerful models to downstream tasks is increasingly important. In this paper, we study a principled finetuning paradigm -- Orthogonal Finetuning (OFT) -- for downstream task adaptation. Despite demonstrating good generalizability, OFT still uses a fairly large number of trainable parameters due to the high dimensionality of orthogonal matrices. To address this, we start by examining OFT from an information transmission perspective, and then identify a few key desiderata that enable better parameter-efficiency. Inspired by how the Cooley-Tukey fast Fourier transform algorithm enables efficient information transmission, we propose an efficient orthogonal parameterization using butterfly structures. We apply this parameterization to OFT, creating a novel parameter-efficient finetuning method, called Orthogonal Butterfly (BOFT). By subsuming OFT as a special case, BOFT introduces a generalized orthogonal finetuning framework. Finally, we conduct an extensive empirical study of adapting large vision transformers, large language models, and text-to-image diffusion models to various downstream tasks in vision and language.
Pairwise Similarity Learning is SimPLE
Oct 13, 2023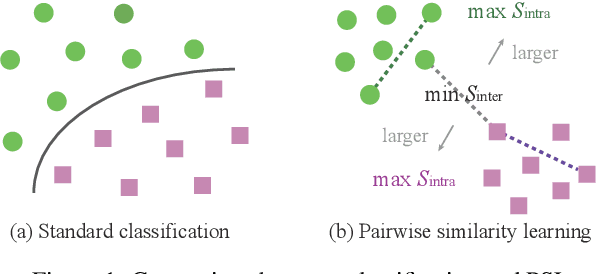
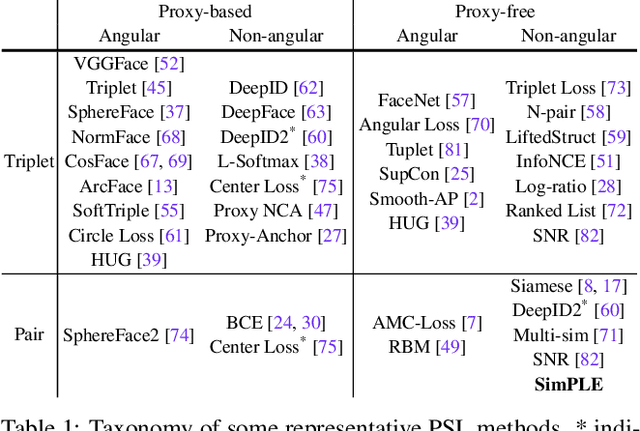
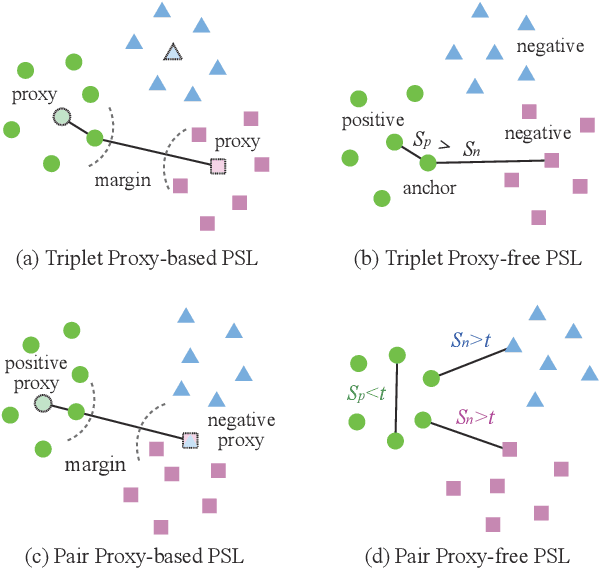
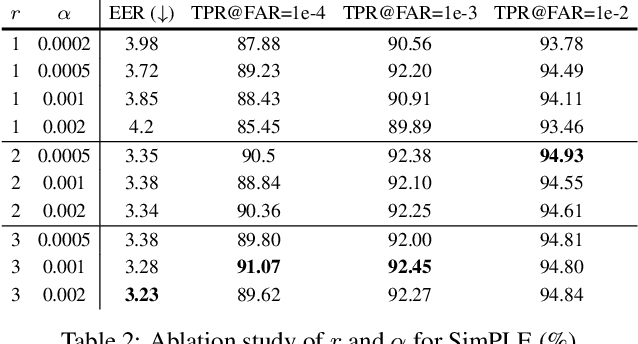
In this paper, we focus on a general yet important learning problem, pairwise similarity learning (PSL). PSL subsumes a wide range of important applications, such as open-set face recognition, speaker verification, image retrieval and person re-identification. The goal of PSL is to learn a pairwise similarity function assigning a higher similarity score to positive pairs (i.e., a pair of samples with the same label) than to negative pairs (i.e., a pair of samples with different label). We start by identifying a key desideratum for PSL, and then discuss how existing methods can achieve this desideratum. We then propose a surprisingly simple proxy-free method, called SimPLE, which requires neither feature/proxy normalization nor angular margin and yet is able to generalize well in open-set recognition. We apply the proposed method to three challenging PSL tasks: open-set face recognition, image retrieval and speaker verification. Comprehensive experimental results on large-scale benchmarks show that our method performs significantly better than current state-of-the-art methods.
Text-Guided Generation and Editing of Compositional 3D Avatars
Sep 13, 2023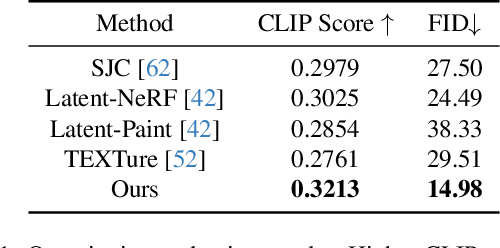
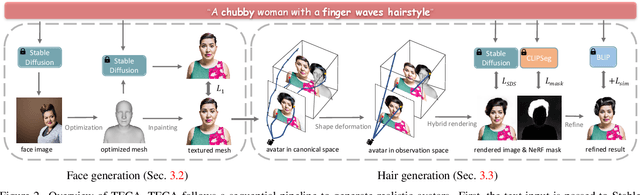
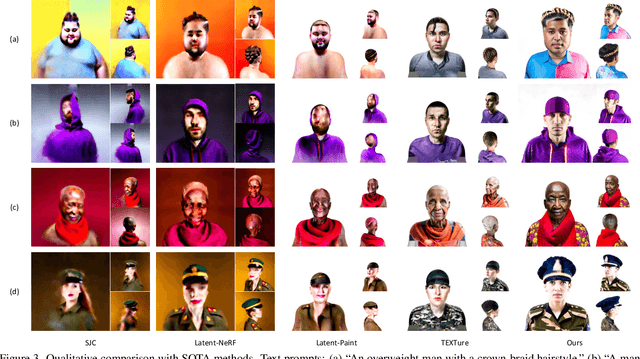
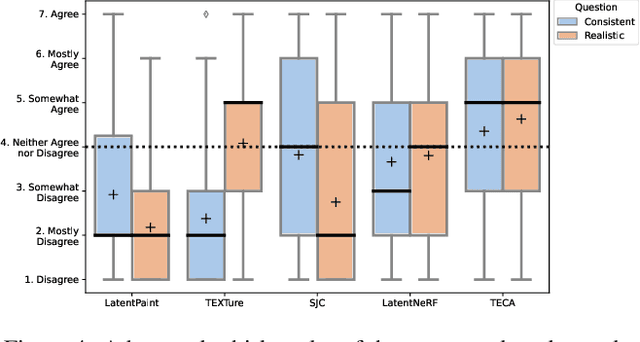
Our goal is to create a realistic 3D facial avatar with hair and accessories using only a text description. While this challenge has attracted significant recent interest, existing methods either lack realism, produce unrealistic shapes, or do not support editing, such as modifications to the hairstyle. We argue that existing methods are limited because they employ a monolithic modeling approach, using a single representation for the head, face, hair, and accessories. Our observation is that the hair and face, for example, have very different structural qualities that benefit from different representations. Building on this insight, we generate avatars with a compositional model, in which the head, face, and upper body are represented with traditional 3D meshes, and the hair, clothing, and accessories with neural radiance fields (NeRF). The model-based mesh representation provides a strong geometric prior for the face region, improving realism while enabling editing of the person's appearance. By using NeRFs to represent the remaining components, our method is able to model and synthesize parts with complex geometry and appearance, such as curly hair and fluffy scarves. Our novel system synthesizes these high-quality compositional avatars from text descriptions. The experimental results demonstrate that our method, Text-guided generation and Editing of Compositional Avatars (TECA), produces avatars that are more realistic than those of recent methods while being editable because of their compositional nature. For example, our TECA enables the seamless transfer of compositional features like hairstyles, scarves, and other accessories between avatars. This capability supports applications such as virtual try-on.
Rethinking Voice-Face Correlation: A Geometry View
Jul 26, 2023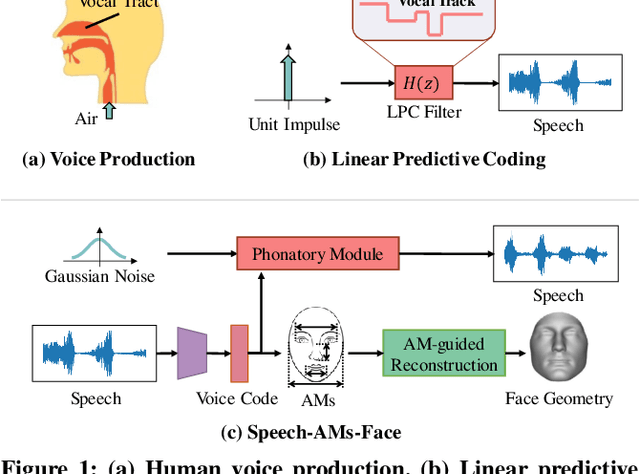

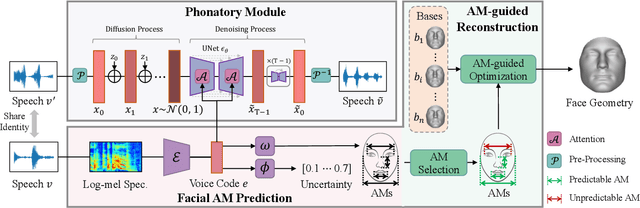

Previous works on voice-face matching and voice-guided face synthesis demonstrate strong correlations between voice and face, but mainly rely on coarse semantic cues such as gender, age, and emotion. In this paper, we aim to investigate the capability of reconstructing the 3D facial shape from voice from a geometry perspective without any semantic information. We propose a voice-anthropometric measurement (AM)-face paradigm, which identifies predictable facial AMs from the voice and uses them to guide 3D face reconstruction. By leveraging AMs as a proxy to link the voice and face geometry, we can eliminate the influence of unpredictable AMs and make the face geometry tractable. Our approach is evaluated on our proposed dataset with ground-truth 3D face scans and corresponding voice recordings, and we find significant correlations between voice and specific parts of the face geometry, such as the nasal cavity and cranium. Our work offers a new perspective on voice-face correlation and can serve as a good empirical study for anthropometry science.
The Hidden Dance of Phonemes and Visage: Unveiling the Enigmatic Link between Phonemes and Facial Features
Jul 26, 2023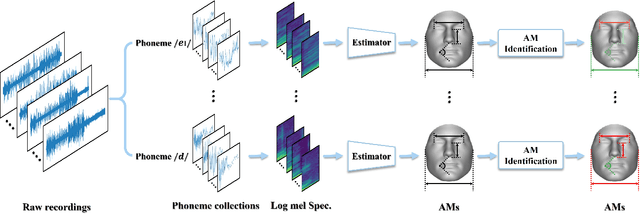
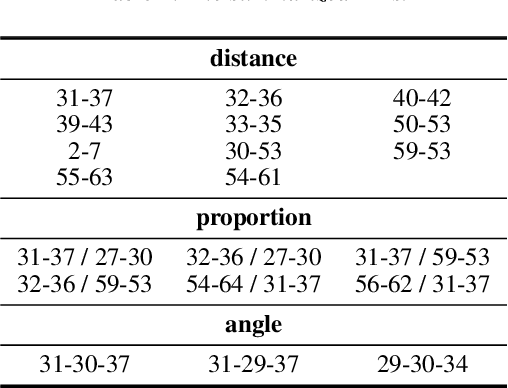
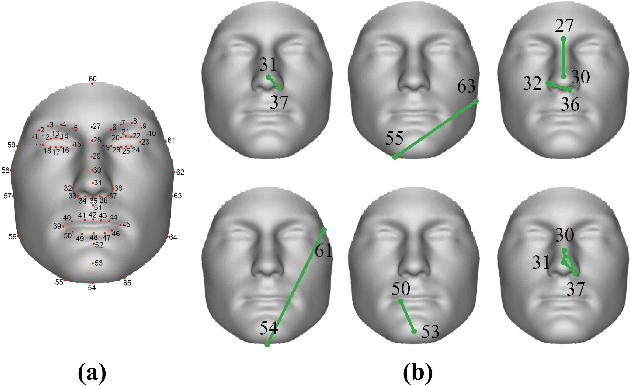
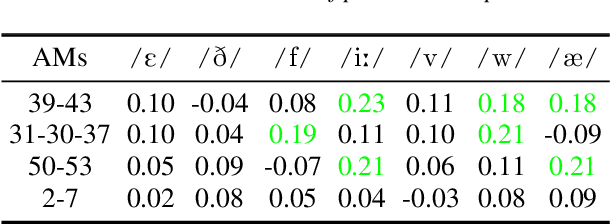
This work unveils the enigmatic link between phonemes and facial features. Traditional studies on voice-face correlations typically involve using a long period of voice input, including generating face images from voices and reconstructing 3D face meshes from voices. However, in situations like voice-based crimes, the available voice evidence may be short and limited. Additionally, from a physiological perspective, each segment of speech -- phoneme -- corresponds to different types of airflow and movements in the face. Therefore, it is advantageous to discover the hidden link between phonemes and face attributes. In this paper, we propose an analysis pipeline to help us explore the voice-face relationship in a fine-grained manner, i.e., phonemes v.s. facial anthropometric measurements (AM). We build an estimator for each phoneme-AM pair and evaluate the correlation through hypothesis testing. Our results indicate that AMs are more predictable from vowels compared to consonants, particularly with plosives. Additionally, we observe that if a specific AM exhibits more movement during phoneme pronunciation, it is more predictable. Our findings support those in physiology regarding correlation and lay the groundwork for future research on speech-face multimodal learning.