 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervising 3D Talking Head Avatars with Analysis-by-Audio-Synthesis
Apr 18, 2025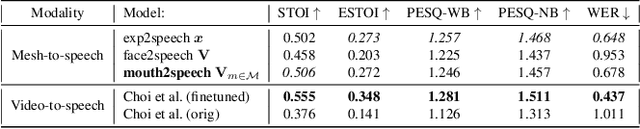
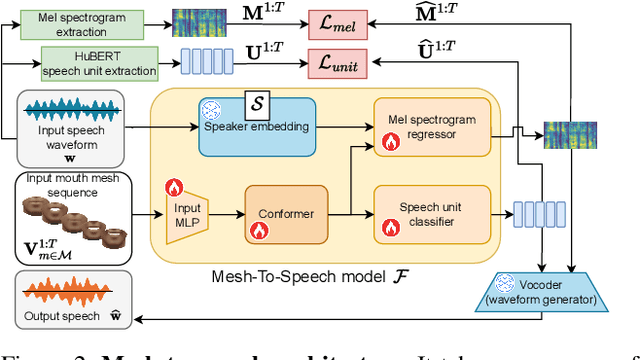

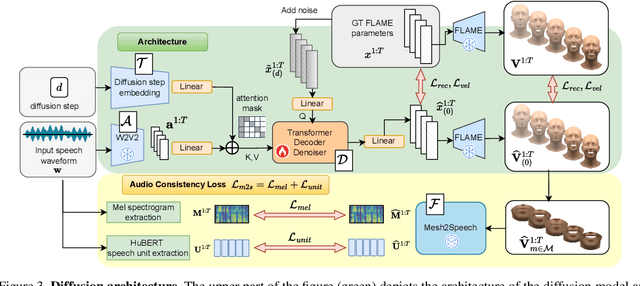
In order to be widely applicable, speech-driven 3D head avatars must articulate their lips in accordance with speech, while also conveying the appropriate emotions with dynamically changing facial expressions. The key problem is that deterministic models produce high-quality lip-sync but without rich expressions, whereas stochastic models generate diverse expressions but with lower lip-sync quality. To get the best of both, we seek a stochastic model with accurate lip-sync. To that end, we develop a new approach based on the following observation: if a method generates realistic 3D lip motions, it should be possible to infer the spoken audio from the lip motion. The inferred speech should match the original input audio, and erroneous predictions create a novel supervision signal for training 3D talking head avatars with accurate lip-sync. To demonstrate this effect, we propose THUNDER (Talking Heads Under Neural Differentiable Elocution Reconstruction), a 3D talking head avatar framework that introduces a novel supervision mechanism via differentiable sound production. First, we train a novel mesh-to-speech model that regresses audio from facial animation. Then, we incorporate this model into a diffusion-based talking avatar framework. During training, the mesh-to-speech model takes the generated animation and produces a sound that is compared to the input speech, creating a differentiable analysis-by-audio-synthesis supervision loop. Our extensive qualitative and quantitative experiments demonstrate that THUNDER significantly improves the quality of the lip-sync of talking head avatars while still allowing for generation of diverse, high-quality, expressive facial animations.
Emotional Speech-driven 3D Body Animation via Disentangled Latent Diffusion
Dec 07, 2023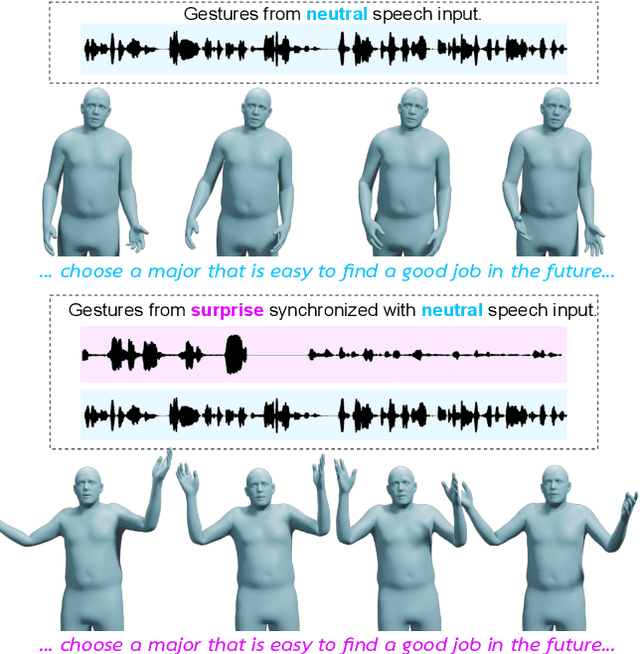



Existing methods for synthesizing 3D human gestures from speech have shown promising results, but they do not explicitly model the impact of emotions on the generated gestures. Instead, these methods directly output animations from speech without control over the expressed emotion. To address this limitation, we present AMUSE, an emotional speech-driven body animation model based on latent diffusion. Our observation is that content (i.e., gestures related to speech rhythm and word utterances), emotion, and personal style are separable. To account for this, AMUSE maps the driving audio to three disentangled latent vectors: one for content, one for emotion, and one for personal style. A latent diffusion model, trained to generate gesture motion sequences, is then conditioned on these latent vectors. Once trained, AMUSE synthesizes 3D human gestures directly from speech with control over the expressed emotions and style by combining the content from the driving speech with the emotion and style of another speech sequence. Randomly sampling the noise of the diffusion model further generates variations of the gesture with the same emotional expressivity. Qualitative, quantitative, and perceptual evaluations demonstrate that AMUSE outputs realistic gesture sequences. Compared to the state of the art, the generated gestures are better synchronized with the speech content and better represent the emotion expressed by the input speech. Our project website is amuse.is.tue.mpg.de.
Emotional Speech-Driven Animation with Content-Emotion Disentanglement
Jun 15, 2023
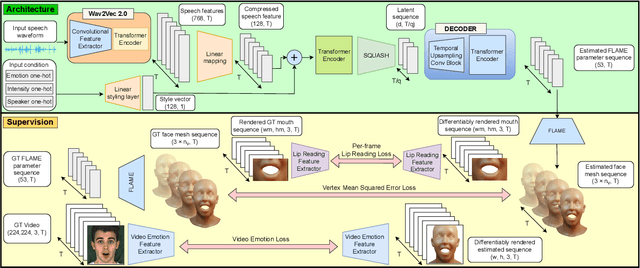
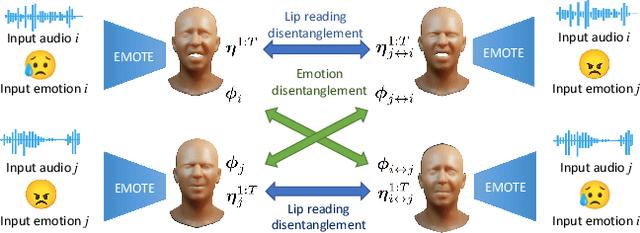
To be widely adopted, 3D facial avatars need to be animated easily, realistically, and directly, from speech signals. While the best recent methods generate 3D animations that are synchronized with the input audio, they largely ignore the impact of emotions on facial expressions. Instead, their focus is on modeling the correlations between speech and facial motion, resulting in animations that are unemotional or do not match the input emotion. We observe that there are two contributing factors resulting in facial animation - the speech and the emotion. We exploit these insights in EMOTE (Expressive Model Optimized for Talking with Emotion), which generates 3D talking head avatars that maintain lip sync while enabling explicit control over the expression of emotion. Due to the absence of high-quality aligned emotional 3D face datasets with speech, EMOTE is trained from an emotional video dataset (i.e., MEAD). To achieve this, we match speech-content between generated sequences and target videos differently from emotion content. Specifically, we train EMOTE with additional supervision in the form of a lip-reading objective to preserve the speech-dependent content (spatially local and high temporal frequency), while utilizing emotion supervision on a sequence-level (spatially global and low frequency). Furthermore, we employ a content-emotion exchange mechanism in order to supervise different emotion on the same audio, while maintaining the lip motion synchronized with the speech. To employ deep perceptual losses without getting undesirable artifacts, we devise a motion prior in form of a temporal VAE. Extensive qualitative, quantitative, and perceptual evaluations demonstrate that EMOTE produces state-of-the-art speech-driven facial animations, with lip sync on par with the best methods while offering additional, high-quality emotional control.