 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCon3R: Contact-aware 3D Human-Scene Reconstruction from Monocular Video
Apr 21, 2026We introduce UniCon3R (Unified Contact-aware 3D Reconstruction), a unified feed-forward framework for online human-scene 4D reconstruction from monocular videos. Recent feed-forward methods enable real-time world-coordinate human motion and scene reconstruction, but they often produce physically implausible artifacts such as bodies floating above the ground or penetrating parts of the scene. The key reason is that existing approaches fail to model physical interactions between the human and the environment. A natural next step is to predict human-scene contact as an auxiliary output -- yet we find this alone is not sufficient: contact must actively correct the reconstruction. To address this, we explicitly model interaction by inferring 3D contact from the human pose and scene geometry and use the contact as a corrective cue for generating the final pose. This enables UniCon3R to jointly recover high-fidelity scene geometry and spatially aligned 3D humans within the scene. Experiments on standard human-centric video benchmarks such as RICH, EMDB, 3DPW and SLOPER4D show that UniCon3R outperforms state-of-the-art baselines on physical plausibility and global human motion estimation while achieving real-time online inference. We experimentally demonstrate that contact serves as a powerful internal prior rather than just an external metric, thus establishing a new paradigm for physically grounded joint human-scene reconstruction. Project page is available at https://surtantheta.github.io/UniCon3R .
Reconstructing Objects along Hand Interaction Timelines in Egocentric Video
Dec 08, 2025We introduce the task of Reconstructing Objects along Hand Interaction Timelines (ROHIT). We first define the Hand Interaction Timeline (HIT) from a rigid object's perspective. In a HIT, an object is first static relative to the scene, then is held in hand following contact, where its pose changes. This is usually followed by a firm grip during use, before it is released to be static again w.r.t. to the scene. We model these pose constraints over the HIT, and propose to propagate the object's pose along the HIT enabling superior reconstruction using our proposed Constrained Optimisation and Propagation (COP) framework. Importantly, we focus on timelines with stable grasps - i.e. where the hand is stably holding an object, effectively maintaining constant contact during use. This allows us to efficiently annotate, study, and evaluate object reconstruction in videos without 3D ground truth. We evaluate our proposed task, ROHIT, over two egocentric datasets, HOT3D and in-the-wild EPIC-Kitchens. In HOT3D, we curate 1.2K clips of stable grasps. In EPIC-Kitchens, we annotate 2.4K clips of stable grasps including 390 object instances across 9 categories from videos of daily interactions in 141 environments. Without 3D ground truth, we utilise 2D projection error to assess the reconstruction. Quantitatively, COP improves stable grasp reconstruction by 6.2-11.3% and HIT reconstruction by up to 24.5% with constrained pose propagation.
PICO: Reconstructing 3D People In Contact with Objects
Apr 24, 2025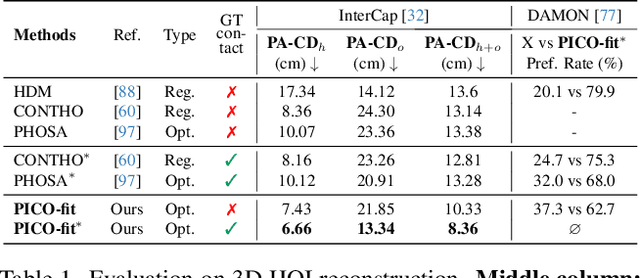


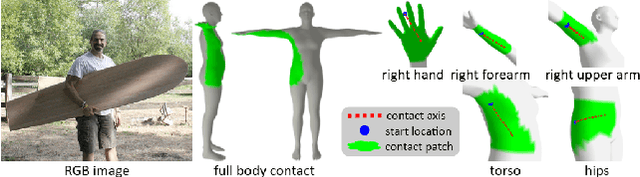
Recovering 3D Human-Object Interaction (HOI) from single color images is challenging due to depth ambiguities, occlusions, and the huge variation in object shape and appearance. Thus, past work requires controlled settings such as known object shapes and contacts, and tackles only limited object classes. Instead, we need methods that generalize to natural images and novel object classes. We tackle this in two main ways: (1) We collect PICO-db, a new dataset of natural images uniquely paired with dense 3D contact on both body and object meshes. To this end, we use images from the recent DAMON dataset that are paired with contacts, but these contacts are only annotated on a canonical 3D body. In contrast, we seek contact labels on both the body and the object. To infer these given an image, we retrieve an appropriate 3D object mesh from a database by leveraging vision foundation models. Then, we project DAMON's body contact patches onto the object via a novel method needing only 2 clicks per patch. This minimal human input establishes rich contact correspondences between bodies and objects. (2) We exploit our new dataset of contact correspondences in a novel render-and-compare fitting method, called PICO-fit, to recover 3D body and object meshes in interaction. PICO-fit infers contact for the SMPL-X body, retrieves a likely 3D object mesh and contact from PICO-db for that object, and uses the contact to iteratively fit the 3D body and object meshes to image evidence via optimization. Uniquely, PICO-fit works well for many object categories that no existing method can tackle. This is crucial to enable HOI understanding to scale in the wild. Our data and code are available at https://pico.is.tue.mpg.de.
InteractVLM: 3D Interaction Reasoning from 2D Foundational Models
Apr 07, 2025We introduce InteractVLM, a novel method to estimate 3D contact points on human bodies and objects from single in-the-wild images, enabling accurate human-object joint reconstruction in 3D. This is challenging due to occlusions, depth ambiguities, and widely varying object shapes. Existing methods rely on 3D contact annotations collected via expensive motion-capture systems or tedious manual labeling, limiting scalability and generalization. To overcome this, InteractVLM harnesses the broad visual knowledge of large Vision-Language Models (VLMs), fine-tuned with limited 3D contact data. However, directly applying these models is non-trivial, as they reason only in 2D, while human-object contact is inherently 3D. Thus we introduce a novel Render-Localize-Lift module that: (1) embeds 3D body and object surfaces in 2D space via multi-view rendering, (2) trains a novel multi-view localization model (MV-Loc) to infer contacts in 2D, and (3) lifts these to 3D. Additionally, we propose a new task called Semantic Human Contact estimation, where human contact predictions are conditioned explicitly on object semantics, enabling richer interaction modeling. InteractVLM outperforms existing work on contact estimation and also facilitates 3D reconstruction from an in-the wild image. Code and models are available at https://interactvlm.is.tue.mpg.de.
SDFit: 3D Object Pose and Shape by Fitting a Morphable SDF to a Single Image
Sep 24, 2024
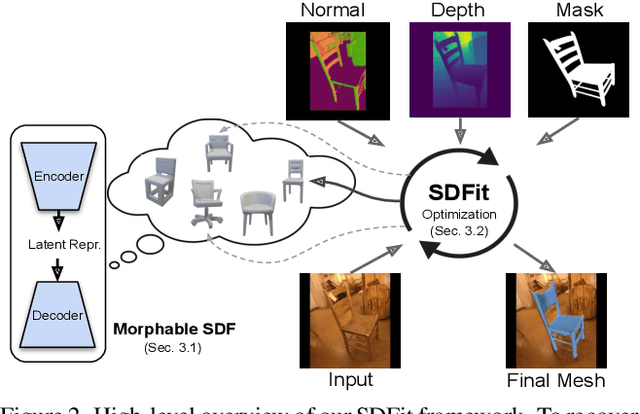


We focus on recovering 3D object pose and shape from single images. This is highly challenging due to strong (self-)occlusions, depth ambiguities, the enormous shape variance, and lack of 3D ground truth for natural images. Recent work relies mostly on learning from finite datasets, so it struggles generalizing, while it focuses mostly on the shape itself, largely ignoring the alignment with pixels. Moreover, it performs feed-forward inference, so it cannot refine estimates. We tackle these limitations with a novel framework, called SDFit. To this end, we make three key observations: (1) Learned signed-distance-function (SDF) models act as a strong morphable shape prior. (2) Foundational models embed 2D images and 3D shapes in a joint space, and (3) also infer rich features from images. SDFit exploits these as follows. First, it uses a category-level morphable SDF (mSDF) model, called DIT, to generate 3D shape hypotheses. This mSDF is initialized by querying OpenShape's latent space conditioned on the input image. Then, it computes 2D-to-3D correspondences, by extracting and matching features from the image and mSDF. Last, it fits the mSDF to the image in an render-and-compare fashion, to iteratively refine estimates. We evaluate SDFit on the Pix3D and Pascal3D+ datasets of real-world images. SDFit performs roughly on par with state-of-the-art learned methods, but, uniquely, requires no re-training. Thus, SDFit is promising for generalizing in the wild, paving the way for future research. Code will be released
HUMOS: Human Motion Model Conditioned on Body Shape
Sep 05, 2024
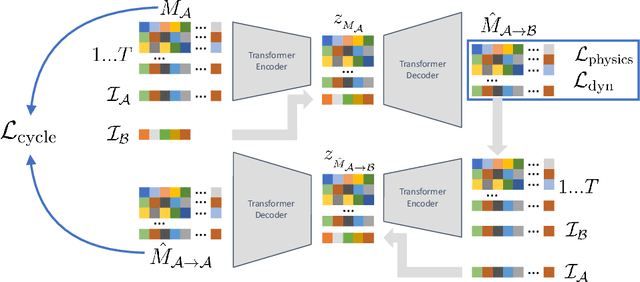
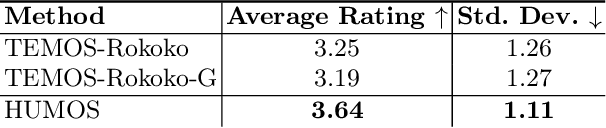

Generating realistic human motion is essential for many computer vision and graphics applications. The wide variety of human body shapes and sizes greatly impacts how people move. However, most existing motion models ignore these differences, relying on a standardized, average body. This leads to uniform motion across different body types, where movements don't match their physical characteristics, limiting diversity. To solve this, we introduce a new approach to develop a generative motion model based on body shape. We show that it's possible to train this model using unpaired data by applying cycle consistency, intuitive physics, and stability constraints, which capture the relationship between identity and movement. The resulting model generates diverse, physically plausible, and dynamically stable human motions that are both quantitatively and qualitatively more realistic than current state-of-the-art methods. More details are available on our project page https://CarstenEpic.github.io/humos/.
DECO: Dense Estimation of 3D Human-Scene Contact In The Wild
Sep 26, 2023
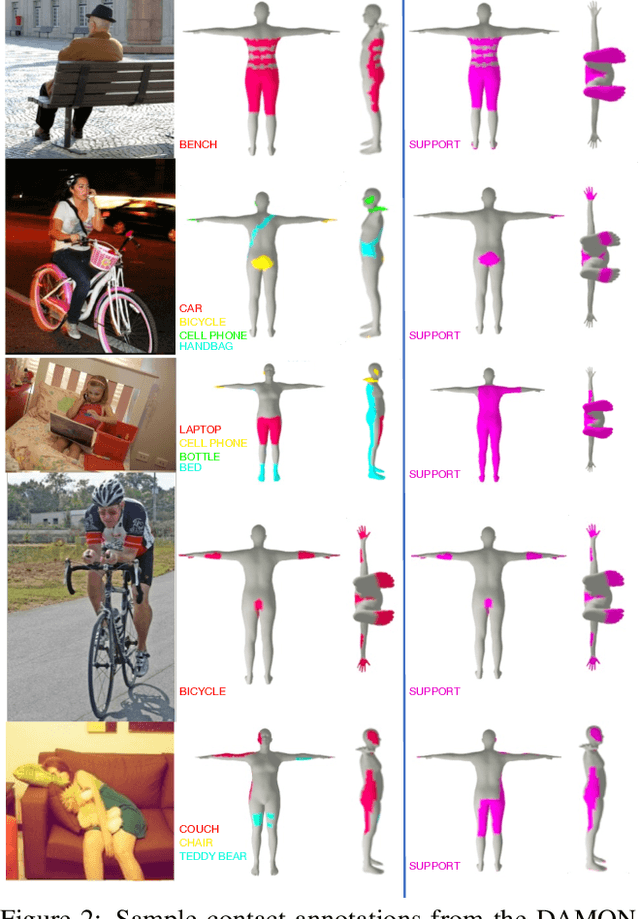
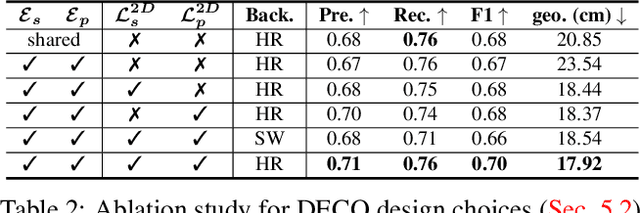
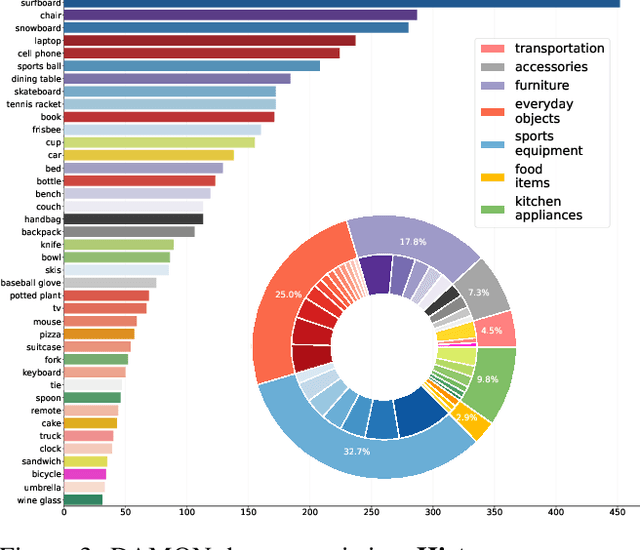
Understanding how humans use physical contact to interact with the world is key to enabling human-centric artificial intelligence. While inferring 3D contact is crucial for modeling realistic and physically-plausible human-object interactions, existing methods either focus on 2D, consider body joints rather than the surface, use coarse 3D body regions, or do not generalize to in-the-wild images. In contrast, we focus on inferring dense, 3D contact between the full body surface and objects in arbitrary images. To achieve this, we first collect DAMON, a new dataset containing dense vertex-level contact annotations paired with RGB images containing complex human-object and human-scene contact. Second, we train DECO, a novel 3D contact detector that uses both body-part-driven and scene-context-driven attention to estimate vertex-level contact on the SMPL body. DECO builds on the insight that human observers recognize contact by reasoning about the contacting body parts, their proximity to scene objects, and the surrounding scene context. We perform extensive evaluations of our detector on DAMON as well as on the RICH and BEHAVE datasets. We significantly outperform existing SOTA methods across all benchmarks. We also show qualitatively that DECO generalizes well to diverse and challenging real-world human interactions in natural images. The code, data, and models are available at https://deco.is.tue.mpg.de.
Emotional Speech-Driven Animation with Content-Emotion Disentanglement
Jun 15, 2023
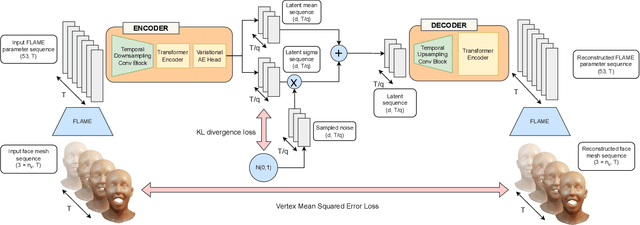
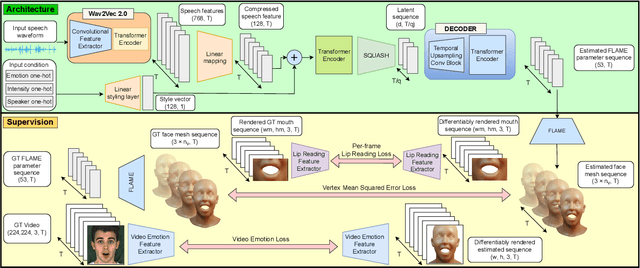
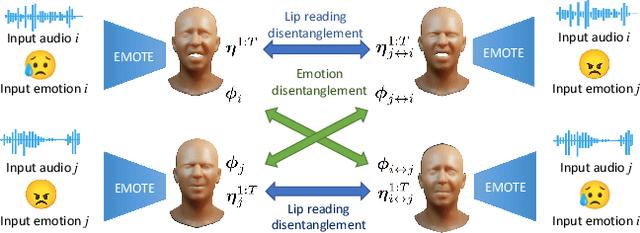
To be widely adopted, 3D facial avatars need to be animated easily, realistically, and directly, from speech signals. While the best recent methods generate 3D animations that are synchronized with the input audio, they largely ignore the impact of emotions on facial expressions. Instead, their focus is on modeling the correlations between speech and facial motion, resulting in animations that are unemotional or do not match the input emotion. We observe that there are two contributing factors resulting in facial animation - the speech and the emotion. We exploit these insights in EMOTE (Expressive Model Optimized for Talking with Emotion), which generates 3D talking head avatars that maintain lip sync while enabling explicit control over the expression of emotion. Due to the absence of high-quality aligned emotional 3D face datasets with speech, EMOTE is trained from an emotional video dataset (i.e., MEAD). To achieve this, we match speech-content between generated sequences and target videos differently from emotion content. Specifically, we train EMOTE with additional supervision in the form of a lip-reading objective to preserve the speech-dependent content (spatially local and high temporal frequency), while utilizing emotion supervision on a sequence-level (spatially global and low frequency). Furthermore, we employ a content-emotion exchange mechanism in order to supervise different emotion on the same audio, while maintaining the lip motion synchronized with the speech. To employ deep perceptual losses without getting undesirable artifacts, we devise a motion prior in form of a temporal VAE. Extensive qualitative, quantitative, and perceptual evaluations demonstrate that EMOTE produces state-of-the-art speech-driven facial animations, with lip sync on par with the best methods while offering additional, high-quality emotional control.
3D Human Pose Estimation via Intuitive Physics
Apr 06, 2023



Estimating 3D humans from images often produces implausible bodies that lean, float, or penetrate the floor. Such methods ignore the fact that bodies are typically supported by the scene. A physics engine can be used to enforce physical plausibility, but these are not differentiable, rely on unrealistic proxy bodies, and are difficult to integrate into existing optimization and learning frameworks. In contrast, we exploit novel intuitive-physics (IP) terms that can be inferred from a 3D SMPL body interacting with the scene. Inspired by biomechanics, we infer the pressure heatmap on the body, the Center of Pressure (CoP) from the heatmap, and the SMPL body's Center of Mass (CoM). With these, we develop IPMAN, to estimate a 3D body from a color image in a "stable" configuration by encouraging plausible floor contact and overlapping CoP and CoM. Our IP terms are intuitive, easy to implement, fast to compute, differentiable, and can be integrated into existing optimization and regression methods. We evaluate IPMAN on standard datasets and MoYo, a new dataset with synchronized multi-view images, ground-truth 3D bodies with complex poses, body-floor contact, CoM and pressure. IPMAN produces more plausible results than the state of the art, improving accuracy for static poses, while not hurting dynamic ones. Code and data are available for research at https://ipman.is.tue.mpg.de.
MIME: Human-Aware 3D Scene Generation
Dec 08, 2022

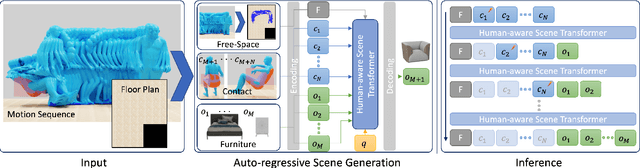
Generating realistic 3D worlds occupied by moving humans has many applications in games, architecture, and synthetic data creation. But generating such scenes is expensive and labor intensive. Recent work generates human poses and motions given a 3D scene. Here, we take the opposite approach and generate 3D indoor scenes given 3D human motion. Such motions can come from archival motion capture or from IMU sensors worn on the body, effectively turning human movement in a "scanner" of the 3D world. Intuitively, human movement indicates the free-space in a room and human contact indicates surfaces or objects that support activities such as sitting, lying or touching. We propose MIME (Mining Interaction and Movement to infer 3D Environments), which is a generative model of indoor scenes that produces furniture layouts that are consistent with the human movement. MIME uses an auto-regressive transformer architecture that takes the already generated objects in the scene as well as the human motion as input, and outputs the next plausible object. To train MIME, we build a dataset by populating the 3D FRONT scene dataset with 3D humans. Our experiments show that MIME produces more diverse and plausible 3D scenes than a recent generative scene method that does not know about human movement. Code and data will be available for research at https://mime.is.tue.mpg.de.