 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing People, Places, and Cameras
Dec 23, 2024



We present "Humans and Structure from Motion" (HSfM), a method for jointly reconstructing multiple human meshes, scene point clouds, and camera parameters in a metric world coordinate system from a sparse set of uncalibrated multi-view images featuring people. Our approach combines data-driven scene reconstruction with the traditional Structure-from-Motion (SfM) framework to achieve more accurate scene reconstruction and camera estimation, while simultaneously recovering human meshes. In contrast to existing scene reconstruction and SfM methods that lack metric scale information, our method estimates approximate metric scale by leveraging a human statistical model. Furthermore, it reconstructs multiple human meshes within the same world coordinate system alongside the scene point cloud, effectively capturing spatial relationships among individuals and their positions in the environment. We initialize the reconstruction of humans, scenes, and cameras using robust foundational models and jointly optimize these elements. This joint optimization synergistically improves the accuracy of each component. We compare our method to existing approaches on two challenging benchmarks, EgoHumans and EgoExo4D, demonstrating significant improvements in human localization accuracy within the world coordinate frame (reducing error from 3.51m to 1.04m in EgoHumans and from 2.9m to 0.56m in EgoExo4D). Notably, our results show that incorporating human data into the SfM pipeline improves camera pose estimation (e.g., increasing RRA@15 by 20.3% on EgoHumans). Additionally, qualitative results show that our approach improves overall scene reconstruction quality. Our code is available at: muelea.github.io/hsfm.
Estimating Body and Hand Motion in an Ego-sensed World
Oct 04, 2024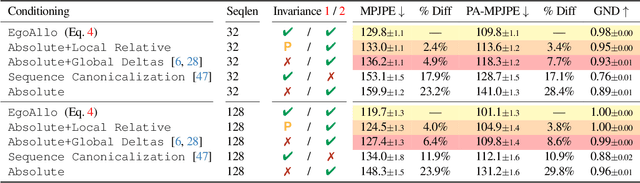
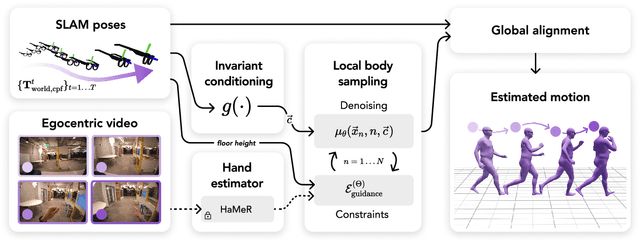
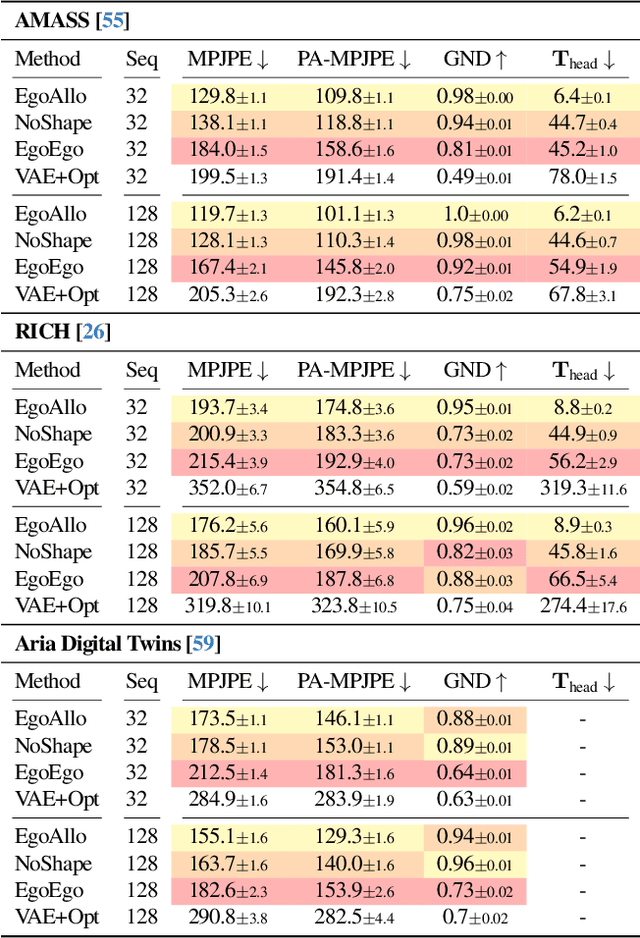
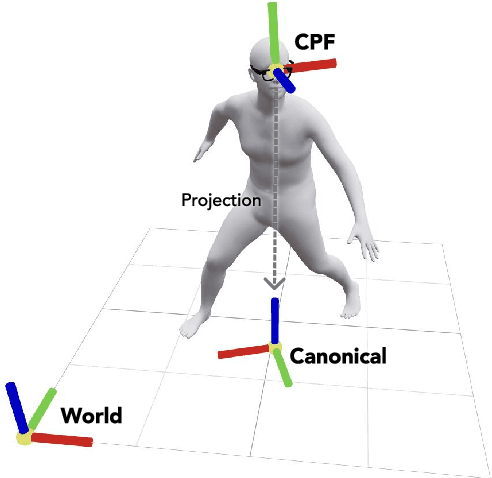
We present EgoAllo, a system for human motion estimation from a head-mounted device. Using only egocentric SLAM poses and images, EgoAllo guides sampling from a conditional diffusion model to estimate 3D body pose, height, and hand parameters that capture the wearer's actions in the allocentric coordinate frame of the scene. To achieve this, our key insight is in representation: we propose spatial and temporal invariance criteria for improving model performance, from which we derive a head motion conditioning parameterization that improves estimation by up to 18%. We also show how the bodies estimated by our system can improve the hands: the resulting kinematic and temporal constraints result in over 40% lower hand estimation errors compared to noisy monocular estimates. Project page: https://egoallo.github.io/
Synergy and Synchrony in Couple Dances
Sep 06, 2024
This paper asks to what extent social interaction influences one's behavior. We study this in the setting of two dancers dancing as a couple. We first consider a baseline in which we predict a dancer's future moves conditioned only on their past motion without regard to their partner. We then investigate the advantage of taking social information into account by conditioning also on the motion of their dancing partner. We focus our analysis on Swing, a dance genre with tight physical coupling for which we present an in-the-wild video dataset. We demonstrate that single-person future motion prediction in this context is challenging. Instead, we observe that prediction greatly benefits from considering the interaction partners' behavior, resulting in surprisingly compelling couple dance synthesis results (see supp. video). Our contributions are a demonstration of the advantages of socially conditioned future motion prediction and an in-the-wild, couple dance video dataset to enable future research in this direction. Video results are available on the project website: https://von31.github.io/synNsync
Pose Priors from Language Models
May 06, 2024We present a zero-shot pose optimization method that enforces accurate physical contact constraints when estimating the 3D pose of humans. Our central insight is that since language is often used to describe physical interaction, large pretrained text-based models can act as priors on pose estimation. We can thus leverage this insight to improve pose estimation by converting natural language descriptors, generated by a large multimodal model (LMM), into tractable losses to constrain the 3D pose optimization. Despite its simplicity, our method produces surprisingly compelling pose reconstructions of people in close contact, correctly capturing the semantics of the social and physical interactions. We demonstrate that our method rivals more complex state-of-the-art approaches that require expensive human annotation of contact points and training specialized models. Moreover, unlike previous approaches, our method provides a unified framework for resolving self-contact and person-to-person contact.
Generative Proxemics: A Prior for 3D Social Interaction from Images
Jun 15, 2023Social interaction is a fundamental aspect of human behavior and communication. The way individuals position themselves in relation to others, also known as proxemics, conveys social cues and affects the dynamics of social interaction. We present a novel approach that learns a 3D proxemics prior of two people in close social interaction. Since collecting a large 3D dataset of interacting people is a challenge, we rely on 2D image collections where social interactions are abundant. We achieve this by reconstructing pseudo-ground truth 3D meshes of interacting people from images with an optimization approach using existing ground-truth contact maps. We then model the proxemics using a novel denoising diffusion model called BUDDI that learns the joint distribution of two people in close social interaction directly in the SMPL-X parameter space. Sampling from our generative proxemics model produces realistic 3D human interactions, which we validate through a user study. Additionally, we introduce a new optimization method that uses the diffusion prior to reconstruct two people in close proximity from a single image without any contact annotation. Our approach recovers more accurate and plausible 3D social interactions from noisy initial estimates and outperforms state-of-the-art methods. See our project site for code, data, and model: muelea.github.io/buddi.
3D Human Pose Estimation via Intuitive Physics
Apr 06, 2023



Estimating 3D humans from images often produces implausible bodies that lean, float, or penetrate the floor. Such methods ignore the fact that bodies are typically supported by the scene. A physics engine can be used to enforce physical plausibility, but these are not differentiable, rely on unrealistic proxy bodies, and are difficult to integrate into existing optimization and learning frameworks. In contrast, we exploit novel intuitive-physics (IP) terms that can be inferred from a 3D SMPL body interacting with the scene. Inspired by biomechanics, we infer the pressure heatmap on the body, the Center of Pressure (CoP) from the heatmap, and the SMPL body's Center of Mass (CoM). With these, we develop IPMAN, to estimate a 3D body from a color image in a "stable" configuration by encouraging plausible floor contact and overlapping CoP and CoM. Our IP terms are intuitive, easy to implement, fast to compute, differentiable, and can be integrated into existing optimization and regression methods. We evaluate IPMAN on standard datasets and MoYo, a new dataset with synchronized multi-view images, ground-truth 3D bodies with complex poses, body-floor contact, CoM and pressure. IPMAN produces more plausible results than the state of the art, improving accuracy for static poses, while not hurting dynamic ones. Code and data are available for research at https://ipman.is.tue.mpg.de.
SPEC: Seeing People in the Wild with an Estimated Camera
Oct 01, 2021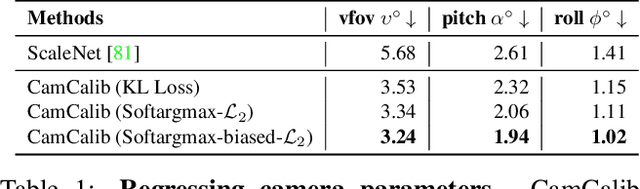
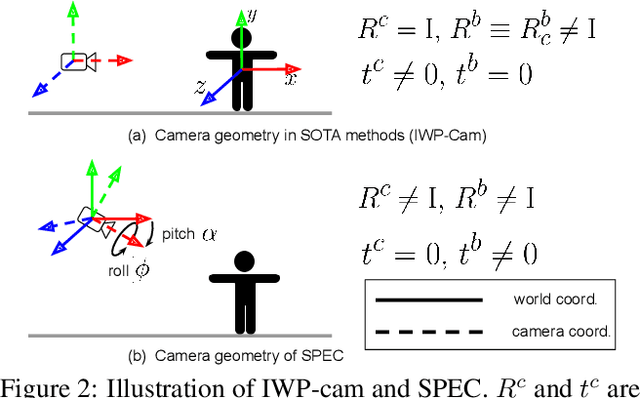
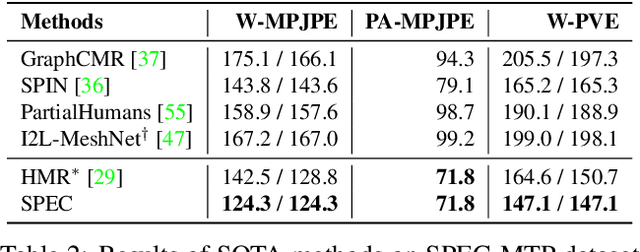
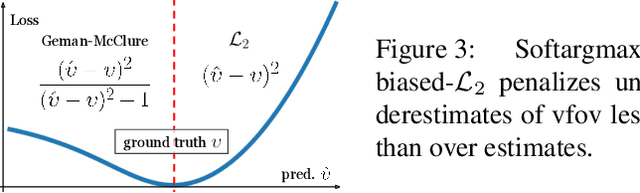
Due to the lack of camera parameter information for in-the-wild images, existing 3D human pose and shape (HPS) estimation methods make several simplifying assumptions: weak-perspective projection, large constant focal length, and zero camera rotation. These assumptions often do not hold and we show, quantitatively and qualitatively, that they cause errors in the reconstructed 3D shape and pose. To address this, we introduce SPEC, the first in-the-wild 3D HPS method that estimates the perspective camera from a single image and employs this to reconstruct 3D human bodies more accurately. %regress 3D human bodies. First, we train a neural network to estimate the field of view, camera pitch, and roll given an input image. We employ novel losses that improve the calibration accuracy over previous work. We then train a novel network that concatenates the camera calibration to the image features and uses these together to regress 3D body shape and pose. SPEC is more accurate than the prior art on the standard benchmark (3DPW) as well as two new datasets with more challenging camera views and varying focal lengths. Specifically, we create a new photorealistic synthetic dataset (SPEC-SYN) with ground truth 3D bodies and a novel in-the-wild dataset (SPEC-MTP) with calibration and high-quality reference bodies. Both qualitative and quantitative analysis confirm that knowing camera parameters during inference regresses better human bodies. Code and datasets are available for research purposes at https://spec.is.tue.mpg.de.
On Self-Contact and Human Pose
Apr 08, 2021


People touch their face 23 times an hour, they cross their arms and legs, put their hands on their hips, etc. While many images of people contain some form of self-contact, current 3D human pose and shape (HPS) regression methods typically fail to estimate this contact. To address this, we develop new datasets and methods that significantly improve human pose estimation with self-contact. First, we create a dataset of 3D Contact Poses (3DCP) containing SMPL-X bodies fit to 3D scans as well as poses from AMASS, which we refine to ensure good contact. Second, we leverage this to create the Mimic-The-Pose (MTP) dataset of images, collected via Amazon Mechanical Turk, containing people mimicking the 3DCP poses with selfcontact. Third, we develop a novel HPS optimization method, SMPLify-XMC, that includes contact constraints and uses the known 3DCP body pose during fitting to create near ground-truth poses for MTP images. Fourth, for more image variety, we label a dataset of in-the-wild images with Discrete Self-Contact (DSC) information and use another new optimization method, SMPLify-DC, that exploits discrete contacts during pose optimization. Finally, we use our datasets during SPIN training to learn a new 3D human pose regressor, called TUCH (Towards Understanding Contact in Humans). We show that the new self-contact training data significantly improves 3D human pose estimates on withheld test data and existing datasets like 3DPW. Not only does our method improve results for self-contact poses, but it also improves accuracy for non-contact poses. The code and data are available for research purposes at https://tuch.is.tue.mpg.de.
Causal Inference in Nonverbal Dyadic Communication with Relevant Interval Selection and Granger Causality
Oct 29, 2018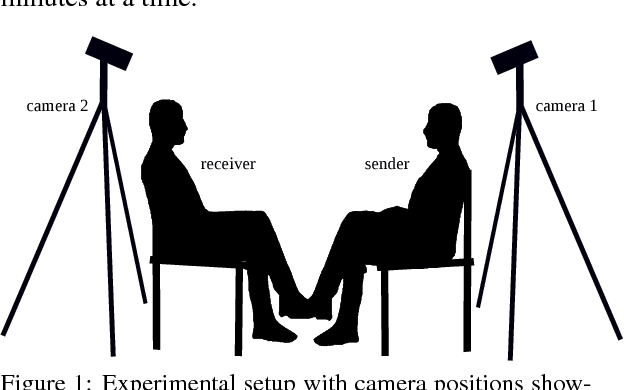
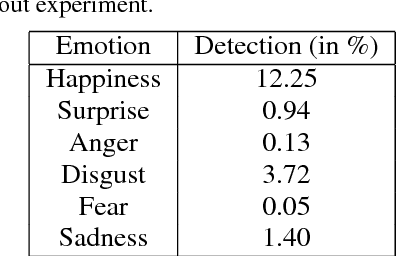
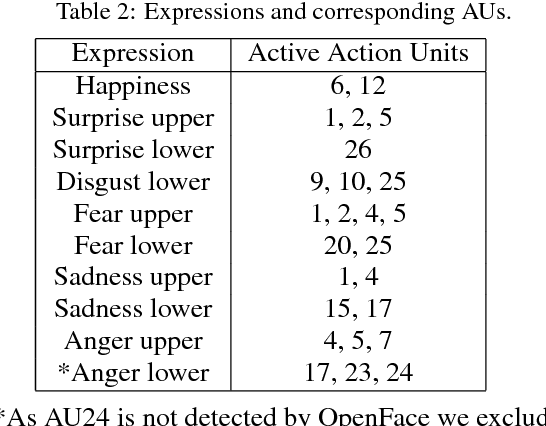

Human nonverbal emotional communication in dyadic dialogs is a process of mutual influence and adaptation. Identifying the direction of influence, or cause-effect relation between participants is a challenging task, due to two main obstacles. First, distinct emotions might not be clearly visible. Second, participants cause-effect relation is transient and variant over time. In this paper, we address these difficulties by using facial expressions that can be present even when strong distinct facial emotions are not visible. We also propose to apply a relevant interval selection approach prior to causal inference to identify those transient intervals where adaptation process occurs. To identify the direction of influence, we apply the concept of Granger causality to the time series of facial expressions on the set of relevant intervals. We tested our approach on synthetic data and then applied it to newly, experimentally obtained data. Here, we were able to show that a more sensitive facial expression detection algorithm and a relevant interval detection approach is most promising to reveal the cause-effect pattern for dyadic communication in various instructed interaction conditions.