 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
SUPR: A Sparse Unified Part-Based Human Representation
Oct 25, 2022Statistical 3D shape models of the head, hands, and fullbody are widely used in computer vision and graphics. Despite their wide use, we show that existing models of the head and hands fail to capture the full range of motion for these parts. Moreover, existing work largely ignores the feet, which are crucial for modeling human movement and have applications in biomechanics, animation, and the footwear industry. The problem is that previous body part models are trained using 3D scans that are isolated to the individual parts. Such data does not capture the full range of motion for such parts, e.g. the motion of head relative to the neck. Our observation is that full-body scans provide important information about the motion of the body parts. Consequently, we propose a new learning scheme that jointly trains a full-body model and specific part models using a federated dataset of full-body and body-part scans. Specifically, we train an expressive human body model called SUPR (Sparse Unified Part-Based Human Representation), where each joint strictly influences a sparse set of model vertices. The factorized representation enables separating SUPR into an entire suite of body part models. Note that the feet have received little attention and existing 3D body models have highly under-actuated feet. Using novel 4D scans of feet, we train a model with an extended kinematic tree that captures the range of motion of the toes. Additionally, feet deform due to ground contact. To model this, we include a novel non-linear deformation function that predicts foot deformation conditioned on the foot pose, shape, and ground contact. We train SUPR on an unprecedented number of scans: 1.2 million body, head, hand and foot scans. We quantitatively compare SUPR and the separated body parts and find that our suite of models generalizes better than existing models. SUPR is available at http://supr.is.tue.mpg.de
On Self-Contact and Human Pose
Apr 08, 2021

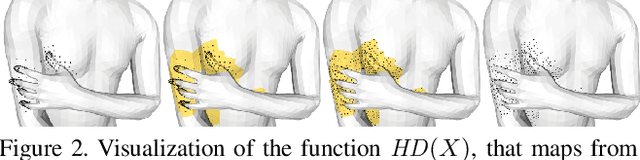

People touch their face 23 times an hour, they cross their arms and legs, put their hands on their hips, etc. While many images of people contain some form of self-contact, current 3D human pose and shape (HPS) regression methods typically fail to estimate this contact. To address this, we develop new datasets and methods that significantly improve human pose estimation with self-contact. First, we create a dataset of 3D Contact Poses (3DCP) containing SMPL-X bodies fit to 3D scans as well as poses from AMASS, which we refine to ensure good contact. Second, we leverage this to create the Mimic-The-Pose (MTP) dataset of images, collected via Amazon Mechanical Turk, containing people mimicking the 3DCP poses with selfcontact. Third, we develop a novel HPS optimization method, SMPLify-XMC, that includes contact constraints and uses the known 3DCP body pose during fitting to create near ground-truth poses for MTP images. Fourth, for more image variety, we label a dataset of in-the-wild images with Discrete Self-Contact (DSC) information and use another new optimization method, SMPLify-DC, that exploits discrete contacts during pose optimization. Finally, we use our datasets during SPIN training to learn a new 3D human pose regressor, called TUCH (Towards Understanding Contact in Humans). We show that the new self-contact training data significantly improves 3D human pose estimates on withheld test data and existing datasets like 3DPW. Not only does our method improve results for self-contact poses, but it also improves accuracy for non-contact poses. The code and data are available for research purposes at https://tuch.is.tue.mpg.de.
STAR: Sparse Trained Articulated Human Body Regressor
Aug 19, 2020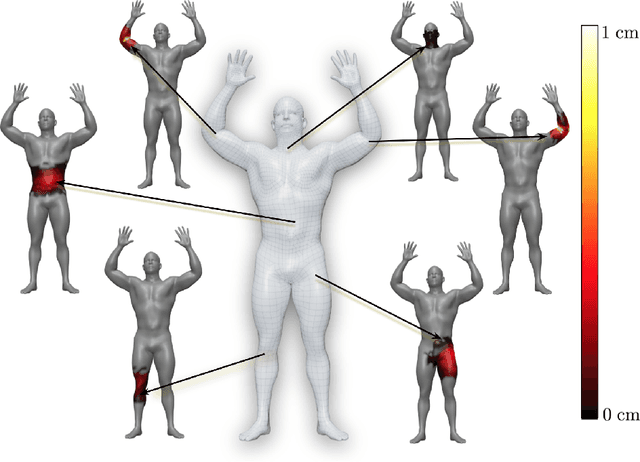
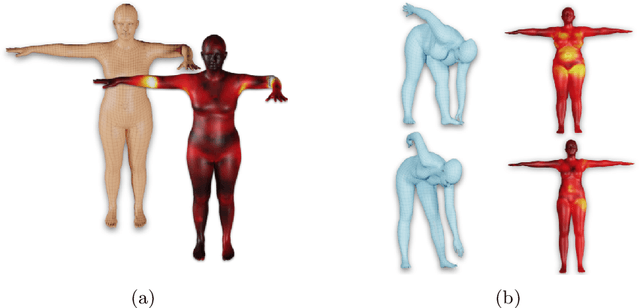
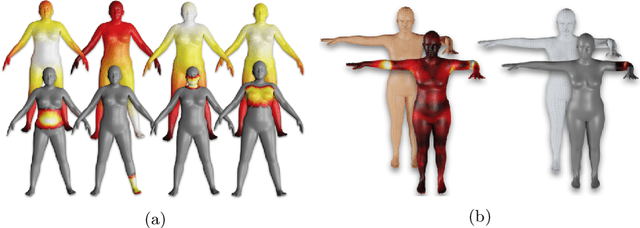
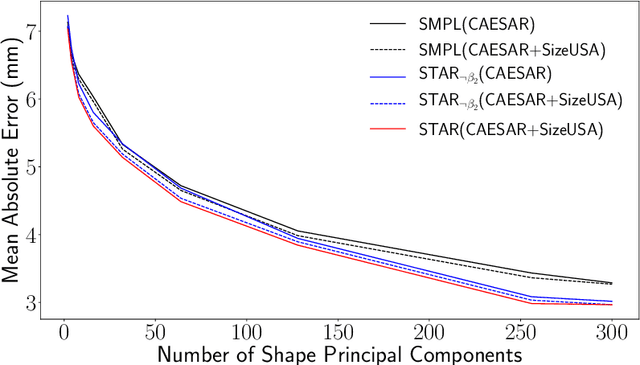
The SMPL body model is widely used for the estimation, synthesis, and analysis of 3D human pose and shape. While popular, we show that SMPL has several limitations and introduce STAR, which is quantitatively and qualitatively superior to SMPL. First, SMPL has a huge number of parameters resulting from its use of global blend shapes. These dense pose-corrective offsets relate every vertex on the mesh to all the joints in the kinematic tree, capturing spurious long-range correlations. To address this, we define per-joint pose correctives and learn the subset of mesh vertices that are influenced by each joint movement. This sparse formulation results in more realistic deformations and significantly reduces the number of model parameters to 20% of SMPL. When trained on the same data as SMPL, STAR generalizes better despite having many fewer parameters. Second, SMPL factors pose-dependent deformations from body shape while, in reality, people with different shapes deform differently. Consequently, we learn shape-dependent pose-corrective blend shapes that depend on both body pose and BMI. Third, we show that the shape space of SMPL is not rich enough to capture the variation in the human population. We address this by training STAR with an additional 10,000 scans of male and female subjects, and show that this results in better model generalization. STAR is compact, generalizes better to new bodies and is a drop-in replacement for SMPL. STAR is publicly available for research purposes at http://star.is.tue.mpg.de.
Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
Apr 11, 2019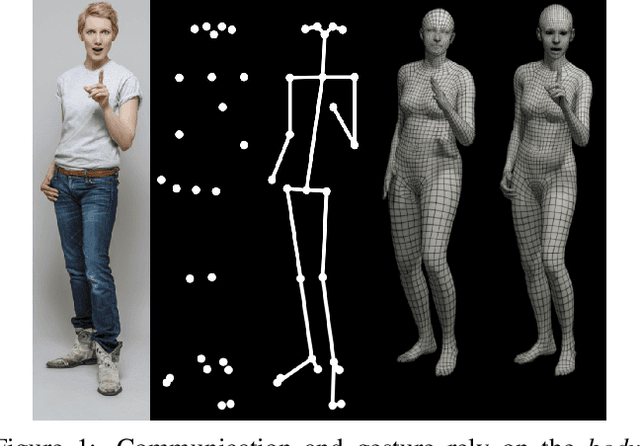

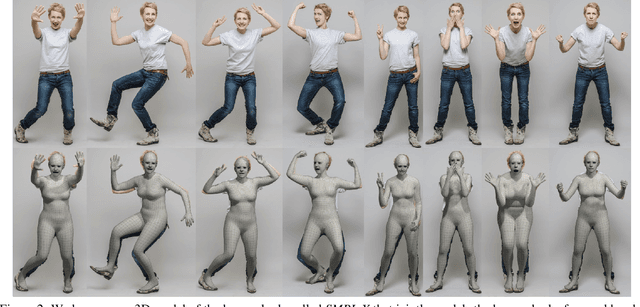

To facilitate the analysis of human actions, interactions and emotions, we compute a 3D model of human body pose, hand pose, and facial expression from a single monocular image. To achieve this, we use thousands of 3D scans to train a new, unified, 3D model of the human body, SMPL-X, that extends SMPL with fully articulated hands and an expressive face. Learning to regress the parameters of SMPL-X directly from images is challenging without paired images and 3D ground truth. Consequently, we follow the approach of SMPLify, which estimates 2D features and then optimizes model parameters to fit the features. We improve on SMPLify in several significant ways: (1) we detect 2D features corresponding to the face, hands, and feet and fit the full SMPL-X model to these; (2) we train a new neural network pose prior using a large MoCap dataset; (3) we define a new interpenetration penalty that is both fast and accurate; (4) we automatically detect gender and the appropriate body models (male, female, or neutral); (5) our PyTorch implementation achieves a speedup of more than 8x over Chumpy. We use the new method, SMPLify-X, to fit SMPL-X to both controlled images and images in the wild. We evaluate 3D accuracy on a new curated dataset comprising 100 images with pseudo ground-truth. This is a step towards automatic expressive human capture from monocular RGB data. The models, code, and data are available for research purposes at https://smpl-x.is.tue.mpg.de.