 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Forcing for Multi-Agent Interaction Sequence Modeling
Dec 19, 2025Understanding and generating multi-person interactions is a fundamental challenge with broad implications for robotics and social computing. While humans naturally coordinate in groups, modeling such interactions remains difficult due to long temporal horizons, strong inter-agent dependencies, and variable group sizes. Existing motion generation methods are largely task-specific and do not generalize to flexible multi-agent generation. We introduce MAGNet (Multi-Agent Diffusion Forcing Transformer), a unified autoregressive diffusion framework for multi-agent motion generation that supports a wide range of interaction tasks through flexible conditioning and sampling. MAGNet performs dyadic prediction, partner inpainting, and full multi-agent motion generation within a single model, and can autoregressively generate ultra-long sequences spanning hundreds of v. Building on Diffusion Forcing, we introduce key modifications that explicitly model inter-agent coupling during autoregressive denoising, enabling coherent coordination across agents. As a result, MAGNet captures both tightly synchronized activities (e.g, dancing, boxing) and loosely structured social interactions. Our approach performs on par with specialized methods on dyadic benchmarks while naturally extending to polyadic scenarios involving three or more interacting people, enabled by a scalable architecture that is agnostic to the number of agents. We refer readers to the supplemental video, where the temporal dynamics and spatial coordination of generated interactions are best appreciated. Project page: https://von31.github.io/MAGNet/
Pose Priors from Language Models
May 06, 2024We present a zero-shot pose optimization method that enforces accurate physical contact constraints when estimating the 3D pose of humans. Our central insight is that since language is often used to describe physical interaction, large pretrained text-based models can act as priors on pose estimation. We can thus leverage this insight to improve pose estimation by converting natural language descriptors, generated by a large multimodal model (LMM), into tractable losses to constrain the 3D pose optimization. Despite its simplicity, our method produces surprisingly compelling pose reconstructions of people in close contact, correctly capturing the semantics of the social and physical interactions. We demonstrate that our method rivals more complex state-of-the-art approaches that require expensive human annotation of contact points and training specialized models. Moreover, unlike previous approaches, our method provides a unified framework for resolving self-contact and person-to-person contact.
From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
Jan 03, 2024



We present a framework for generating full-bodied photorealistic avatars that gesture according to the conversational dynamics of a dyadic interaction. Given speech audio, we output multiple possibilities of gestural motion for an individual, including face, body, and hands. The key behind our method is in combining the benefits of sample diversity from vector quantization with the high-frequency details obtained through diffusion to generate more dynamic, expressive motion. We visualize the generated motion using highly photorealistic avatars that can express crucial nuances in gestures (e.g. sneers and smirks). To facilitate this line of research, we introduce a first-of-its-kind multi-view conversational dataset that allows for photorealistic reconstruction. Experiments show our model generates appropriate and diverse gestures, outperforming both diffusion- and VQ-only methods. Furthermore, our perceptual evaluation highlights the importance of photorealism (vs. meshes) in accurately assessing subtle motion details in conversational gestures. Code and dataset available online.
Can Language Models Learn to Listen?
Aug 21, 2023



We present a framework for generating appropriate facial responses from a listener in dyadic social interactions based on the speaker's words. Given an input transcription of the speaker's words with their timestamps, our approach autoregressively predicts a response of a listener: a sequence of listener facial gestures, quantized using a VQ-VAE. Since gesture is a language component, we propose treating the quantized atomic motion elements as additional language token inputs to a transformer-based large language model. Initializing our transformer with the weights of a language model pre-trained only on text results in significantly higher quality listener responses than training a transformer from scratch. We show that our generated listener motion is fluent and reflective of language semantics through quantitative metrics and a qualitative user study. In our evaluation, we analyze the model's ability to utilize temporal and semantic aspects of spoken text. Project page: https://people.eecs.berkeley.edu/~evonne_ng/projects/text2listen/
Nerfstudio: A Modular Framework for Neural Radiance Field Development
Feb 08, 2023



Neural Radiance Fields (NeRF) are a rapidly growing area of research with wide-ranging applications in computer vision, graphics, robotics, and more. In order to streamline the development and deployment of NeRF research, we propose a modular PyTorch framework, Nerfstudio. Our framework includes plug-and-play components for implementing NeRF-based methods, which make it easy for researchers and practitioners to incorporate NeRF into their projects. Additionally, the modular design enables support for extensive real-time visualization tools, streamlined pipelines for importing captured in-the-wild data, and tools for exporting to video, point cloud and mesh representations. The modularity of Nerfstudio enables the development of Nerfacto, our method that combines components from recent papers to achieve a balance between speed and quality, while also remaining flexible to future modifications. To promote community-driven development, all associated code and data are made publicly available with open-source licensing at https://nerf.studio.
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion
Apr 18, 2022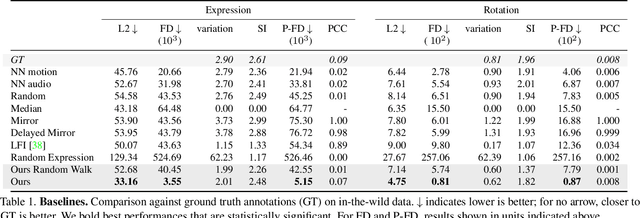


We present a framework for modeling interactional communication in dyadic conversations: given multimodal inputs of a speaker, we autoregressively output multiple possibilities of corresponding listener motion. We combine the motion and speech audio of the speaker using a motion-audio cross attention transformer. Furthermore, we enable non-deterministic prediction by learning a discrete latent representation of realistic listener motion with a novel motion-encoding VQ-VAE. Our method organically captures the multimodal and non-deterministic nature of nonverbal dyadic interactions. Moreover, it produces realistic 3D listener facial motion synchronous with the speaker (see video). We demonstrate that our method outperforms baselines qualitatively and quantitatively via a rich suite of experiments. To facilitate this line of research, we introduce a novel and large in-the-wild dataset of dyadic conversations. Code, data, and videos available at https://evonneng.github.io/learning2listen/.
Watch Those Words: Video Falsification Detection Using Word-Conditioned Facial Motion
Dec 21, 2021



In today's era of digital misinformation, we are increasingly faced with new threats posed by video falsification techniques. Such falsifications range from cheapfakes (e.g., lookalikes or audio dubbing) to deepfakes (e.g., sophisticated AI media synthesis methods), which are becoming perceptually indistinguishable from real videos. To tackle this challenge, we propose a multi-modal semantic forensic approach to discover clues that go beyond detecting discrepancies in visual quality, thereby handling both simpler cheapfakes and visually persuasive deepfakes. In this work, our goal is to verify that the purported person seen in the video is indeed themselves by detecting anomalous correspondences between their facial movements and the words they are saying. We leverage the idea of attribution to learn person-specific biometric patterns that distinguish a given speaker from others. We use interpretable Action Units (AUs) to capture a persons' face and head movement as opposed to deep CNN visual features, and we are the first to use word-conditioned facial motion analysis. Unlike existing person-specific approaches, our method is also effective against attacks that focus on lip manipulation. We further demonstrate our method's effectiveness on a range of fakes not seen in training including those without video manipulation, that were not addressed in prior work.
Body2Hands: Learning to Infer 3D Hands from Conversational Gesture Body Dynamics
Jul 23, 2020

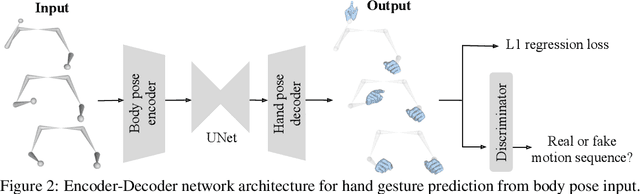

We propose a novel learned deep prior of body motion for 3D hand shape synthesis and estimation in the domain of conversational gestures. Our model builds upon the insight that body motion and hand gestures are strongly correlated in non-verbal communication settings. We formulate the learning of this prior as a prediction task of 3D hand shape over time given body motion input alone. Trained with 3D pose estimations obtained from a large-scale dataset of internet videos, our hand prediction model produces convincing 3D hand gestures given only the 3D motion of the speaker's arms as input. We demonstrate the efficacy of our method on hand gesture synthesis from body motion input, and as a strong body prior for single-view image-based 3D hand pose estimation. We demonstrate that our method outperforms previous state-of-the-art approaches and can generalize beyond the monologue-based training data to multi-person conversations. Video results are available at http://people.eecs.berkeley.edu/~evonne_ng/projects/body2hands/.
You2Me: Inferring Body Pose in Egocentric Video via First and Second Person Interactions
Apr 22, 2019
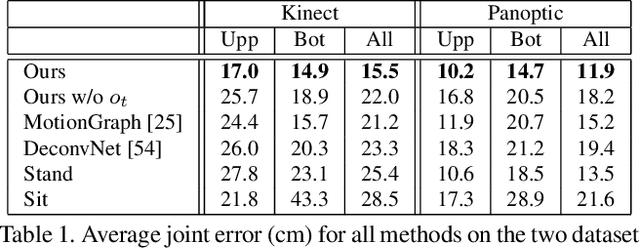

The body pose of a person wearing a camera is of great interest for applications in augmented reality, healthcare, and robotics, yet much of the person's body is out of view for a typical wearable camera. We propose a learning-based approach to estimate the camera wearer's 3D body pose from egocentric video sequences. Our key insight is to leverage interactions with another person---whose body pose we can directly observe---as a signal inherently linked to the body pose of the first-person subject. We show that since interactions between individuals often induce a well-ordered series of back-and-forth responses, it is possible to learn a temporal model of the interlinked poses even though one party is largely out of view. We demonstrate our idea on a variety of domains with dyadic interaction and show the substantial impact on egocentric body pose estimation, which improves the state of the art. Video results are available at http://vision.cs.utexas.edu/projects/you2me/