 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAST: Non-Privileged Clipped Asymmetric Self-Teaching with Advantage Flipping for GRPO
May 29, 2026Reinforcement learning with verifiable rewards (RLVR), especially Group Relative Policy Optimization (GRPO), has been widely used to improve reasoning in large language models. However, outcome-level rewards provide only sparse supervision, and group-relative advantages vanish when all sampled trajectories for a prompt are either correct or incorrect. On-Policy Self-Distillation (OPSD) offers dense token-level guidance, but its token preferences are not necessarily aligned with trajectory correctness; empirical diagnostics show that OPSD signals behave differently on correct and incorrect rollouts, with teacher-positive and teacher-negative gap signals exhibiting different noise profiles. These diagnostics are conducted under an OPSD-style privileged teacher context for analysis only, whereas CAST training uses answer-free self-teacher scoring.Motivated by these observations, this work proposes CAST, an answer-free self-distillation method for GRPO-style RLVR. CAST keeps the verifier-grounded GRPO objective, but uses a stop-gradient self-teacher to shape token-level advantages according to trajectory correctness. Unlike prior self-distilled RLVR methods, CAST does not require reference-solution-conditioned teacher scoring, keeps the self-teacher log-probability gap active throughout training, and applies bidirectional local advantage sign reversal: teacher-negative tokens in correct trajectories can receive negative token-level advantages, while teacher-positive tokens in incorrect trajectories can receive bounded positive local advantages. For zero-variance all-correct and all-wrong groups, CAST assigns bounded sign-constrained base advantages, so these otherwise zero-gradient groups can contribute verifier-signed token feedback. Experiments on mathematical reasoning show that CAST improves RLVR training while retaining a lightweight, verifier-grounded trajectory-level objective.
On-the-fly Large-scale 3D Reconstruction from Multi-Camera Rigs
Dec 09, 2025Recent advances in 3D Gaussian Splatting (3DGS) have enabled efficient free-viewpoint rendering and photorealistic scene reconstruction. While on-the-fly extensions of 3DGS have shown promise for real-time reconstruction from monocular RGB streams, they often fail to achieve complete 3D coverage due to the limited field of view (FOV). Employing a multi-camera rig fundamentally addresses this limitation. In this paper, we present the first on-the-fly 3D reconstruction framework for multi-camera rigs. Our method incrementally fuses dense RGB streams from multiple overlapping cameras into a unified Gaussian representation, achieving drift-free trajectory estimation and efficient online reconstruction. We propose a hierarchical camera initialization scheme that enables coarse inter-camera alignment without calibration, followed by a lightweight multi-camera bundle adjustment that stabilizes trajectories while maintaining real-time performance. Furthermore, we introduce a redundancy-free Gaussian sampling strategy and a frequency-aware optimization scheduler to reduce the number of Gaussian primitives and the required optimization iterations, thereby maintaining both efficiency and reconstruction fidelity. Our method reconstructs hundreds of meters of 3D scenes within just 2 minutes using only raw multi-camera video streams, demonstrating unprecedented speed, robustness, and Fidelity for on-the-fly 3D scene reconstruction.
SOAP: Style-Omniscient Animatable Portraits
May 08, 2025
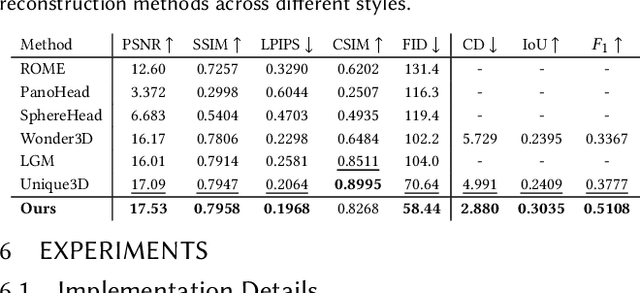
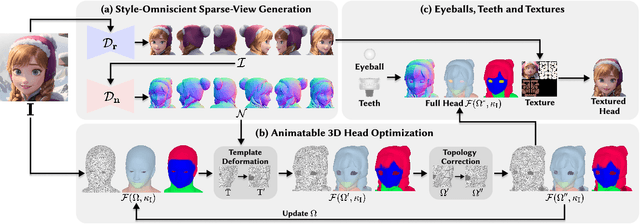
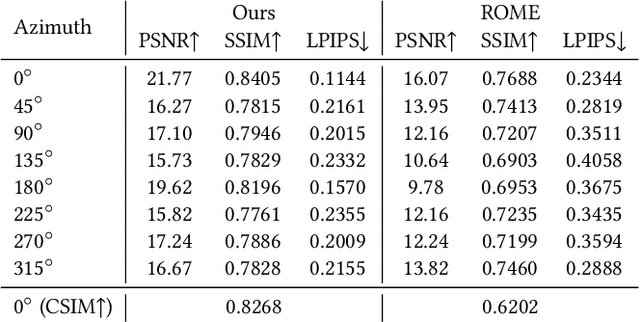
Creating animatable 3D avatars from a single image remains challenging due to style limitations (realistic, cartoon, anime) and difficulties in handling accessories or hairstyles. While 3D diffusion models advance single-view reconstruction for general objects, outputs often lack animation controls or suffer from artifacts because of the domain gap. We propose SOAP, a style-omniscient framework to generate rigged, topology-consistent avatars from any portrait. Our method leverages a multiview diffusion model trained on 24K 3D heads with multiple styles and an adaptive optimization pipeline to deform the FLAME mesh while maintaining topology and rigging via differentiable rendering. The resulting textured avatars support FACS-based animation, integrate with eyeballs and teeth, and preserve details like braided hair or accessories. Extensive experiments demonstrate the superiority of our method over state-of-the-art techniques for both single-view head modeling and diffusion-based generation of Image-to-3D. Our code and data are publicly available for research purposes at https://github.com/TingtingLiao/soap.
Splats in Splats: Embedding Invisible 3D Watermark within Gaussian Splatting
Dec 04, 2024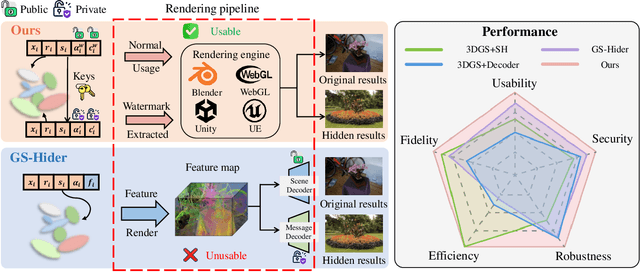
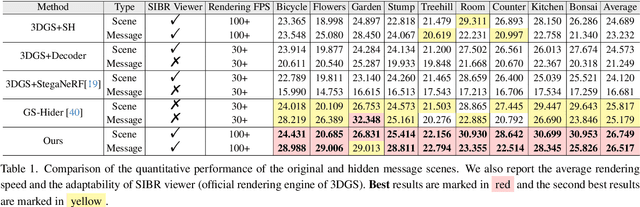
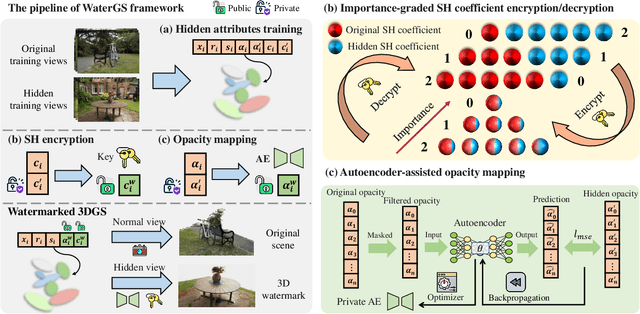
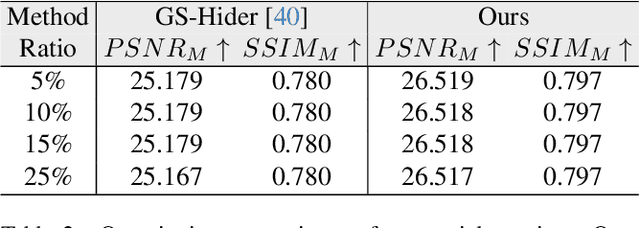
3D Gaussian splatting (3DGS) has demonstrated impressive 3D reconstruction performance with explicit scene representations. Given the widespread application of 3DGS in 3D reconstruction and generation tasks, there is an urgent need to protect the copyright of 3DGS assets. However, existing copyright protection techniques for 3DGS overlook the usability of 3D assets, posing challenges for practical deployment. Here we describe WaterGS, the first 3DGS watermarking framework that embeds 3D content in 3DGS itself without modifying any attributes of the vanilla 3DGS. To achieve this, we take a deep insight into spherical harmonics (SH) and devise an importance-graded SH coefficient encryption strategy to embed the hidden SH coefficients. Furthermore, we employ a convolutional autoencoder to establish a mapping between the original Gaussian primitives' opacity and the hidden Gaussian primitives' opacity. Extensive experiments indicate that WaterGS significantly outperforms existing 3D steganography techniques, with 5.31% higher scene fidelity and 3X faster rendering speed, while ensuring security, robustness, and user experience. Codes and data will be released at https://water-gs.github.io.
PRTGS: Precomputed Radiance Transfer of Gaussian Splats for Real-Time High-Quality Relighting
Aug 07, 2024We proposed Precomputed RadianceTransfer of GaussianSplats (PRTGS), a real-time high-quality relighting method for Gaussian splats in low-frequency lighting environments that captures soft shadows and interreflections by precomputing 3D Gaussian splats' radiance transfer. Existing studies have demonstrated that 3D Gaussian splatting (3DGS) outperforms neural fields' efficiency for dynamic lighting scenarios. However, the current relighting method based on 3DGS still struggles to compute high-quality shadow and indirect illumination in real time for dynamic light, leading to unrealistic rendering results. We solve this problem by precomputing the expensive transport simulations required for complex transfer functions like shadowing, the resulting transfer functions are represented as dense sets of vectors or matrices for every Gaussian splat. We introduce distinct precomputing methods tailored for training and rendering stages, along with unique ray tracing and indirect lighting precomputation techniques for 3D Gaussian splats to accelerate training speed and compute accurate indirect lighting related to environment light. Experimental analyses demonstrate that our approach achieves state-of-the-art visual quality while maintaining competitive training times and allows high-quality real-time (30+ fps) relighting for dynamic light and relatively complex scenes at 1080p resolution.
SpikeGS: Reconstruct 3D scene via fast-moving bio-inspired sensors
Jul 04, 2024
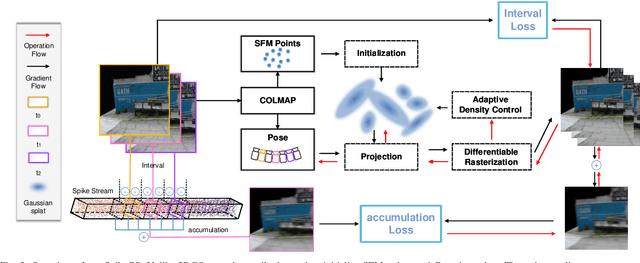


3D Gaussian Splatting (3DGS) demonstrates unparalleled superior performance in 3D scene reconstruction. However, 3DGS heavily relies on the sharp images. Fulfilling this requirement can be challenging in real-world scenarios especially when the camera moves fast, which severely limits the application of 3DGS. To address these challenges, we proposed Spike Gausian Splatting (SpikeGS), the first framework that integrates the spike streams into 3DGS pipeline to reconstruct 3D scenes via a fast-moving bio-inspired camera. With accumulation rasterization, interval supervision, and a specially designed pipeline, SpikeGS extracts detailed geometry and texture from high temporal resolution but texture lacking spike stream, reconstructs 3D scenes captured in 1 second. Extensive experiments on multiple synthetic and real-world datasets demonstrate the superiority of SpikeGS compared with existing spike-based and deblur 3D scene reconstruction methods. Codes and data will be released soon.
VOODOO XP: Expressive One-Shot Head Reenactment for VR Telepresence
May 28, 2024We introduce VOODOO XP: a 3D-aware one-shot head reenactment method that can generate highly expressive facial expressions from any input driver video and a single 2D portrait. Our solution is real-time, view-consistent, and can be instantly used without calibration or fine-tuning. We demonstrate our solution on a monocular video setting and an end-to-end VR telepresence system for two-way communication. Compared to 2D head reenactment methods, 3D-aware approaches aim to preserve the identity of the subject and ensure view-consistent facial geometry for novel camera poses, which makes them suitable for immersive applications. While various facial disentanglement techniques have been introduced, cutting-edge 3D-aware neural reenactment techniques still lack expressiveness and fail to reproduce complex and fine-scale facial expressions. We present a novel cross-reenactment architecture that directly transfers the driver's facial expressions to transformer blocks of the input source's 3D lifting module. We show that highly effective disentanglement is possible using an innovative multi-stage self-supervision approach, which is based on a coarse-to-fine strategy, combined with an explicit face neutralization and 3D lifted frontalization during its initial training stage. We further integrate our novel head reenactment solution into an accessible high-fidelity VR telepresence system, where any person can instantly build a personalized neural head avatar from any photo and bring it to life using the headset. We demonstrate state-of-the-art performance in terms of expressiveness and likeness preservation on a large set of diverse subjects and capture conditions.
SCSim: A Realistic Spike Cameras Simulator
May 27, 2024
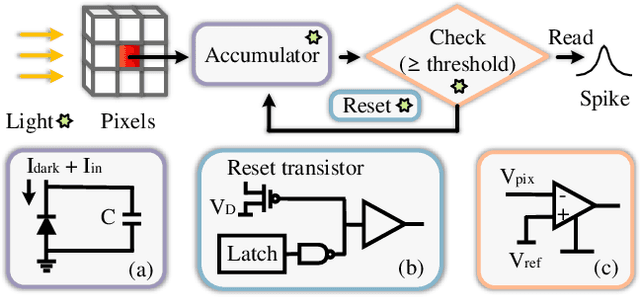
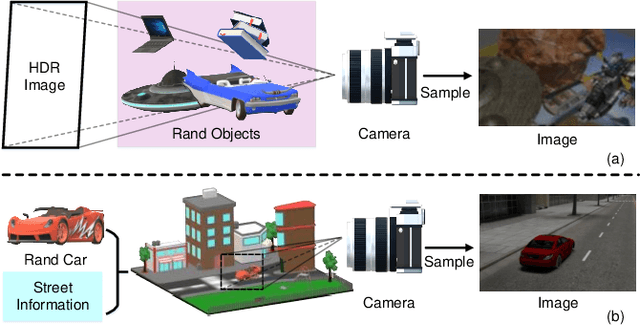

Spike cameras, with their exceptional temporal resolution, are revolutionizing high-speed visual applications. Large-scale synthetic datasets have significantly accelerated the development of these cameras, particularly in reconstruction and optical flow. However, current synthetic datasets for spike cameras lack sophistication. Addressing this gap, we introduce SCSim, a novel and more realistic spike camera simulator with a comprehensive noise model. SCSim is adept at autonomously generating driving scenarios and synthesizing corresponding spike streams. To enhance the fidelity of these streams, we've developed a comprehensive noise model tailored to the unique circuitry of spike cameras. Our evaluations demonstrate that SCSim outperforms existing simulation methods in generating authentic spike streams. Crucially, SCSim simplifies the creation of datasets, thereby greatly advancing spike-based visual tasks like reconstruction. Our project refers to https://github.com/Acnext/SCSim.
Spike-NeRF: Neural Radiance Field Based On Spike Camera
Mar 25, 2024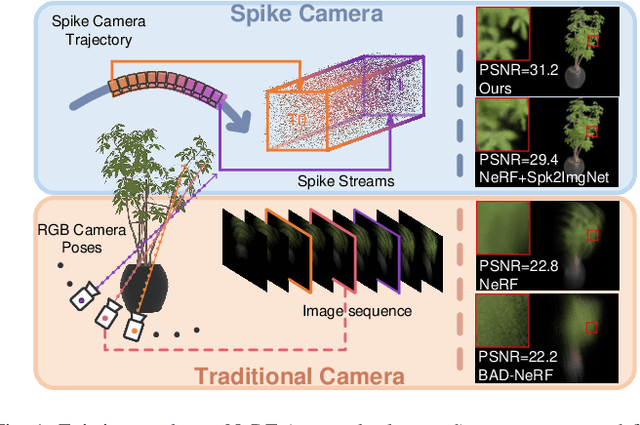
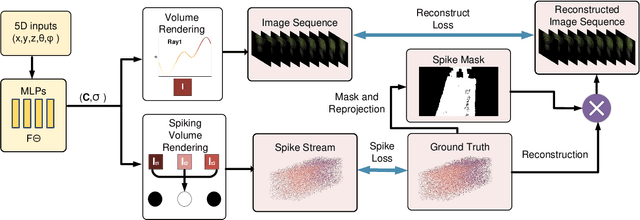


As a neuromorphic sensor with high temporal resolution, spike cameras offer notable advantages over traditional cameras in high-speed vision applications such as high-speed optical estimation, depth estimation, and object tracking. Inspired by the success of the spike camera, we proposed Spike-NeRF, the first Neural Radiance Field derived from spike data, to achieve 3D reconstruction and novel viewpoint synthesis of high-speed scenes. Instead of the multi-view images at the same time of NeRF, the inputs of Spike-NeRF are continuous spike streams captured by a moving spike camera in a very short time. To reconstruct a correct and stable 3D scene from high-frequency but unstable spike data, we devised spike masks along with a distinctive loss function. We evaluate our method qualitatively and numerically on several challenging synthetic scenes generated by blender with the spike camera simulator. Our results demonstrate that Spike-NeRF produces more visually appealing results than the existing methods and the baseline we proposed in high-speed scenes. Our code and data will be released soon.
Learning to Robustly Reconstruct Low-light Dynamic Scenes from Spike Streams
Jan 19, 2024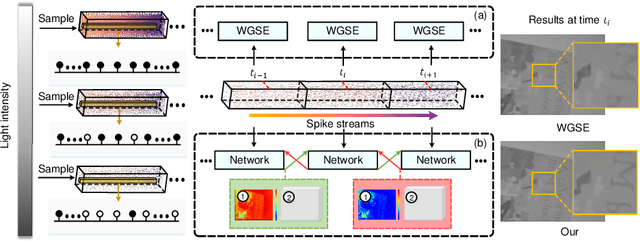


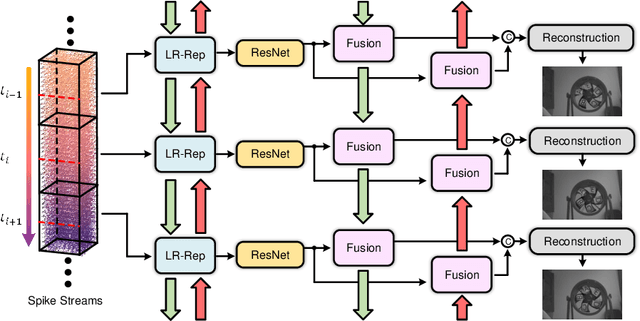
As a neuromorphic sensor with high temporal resolution, spike camera can generate continuous binary spike streams to capture per-pixel light intensity. We can use reconstruction methods to restore scene details in high-speed scenarios. However, due to limited information in spike streams, low-light scenes are difficult to effectively reconstruct. In this paper, we propose a bidirectional recurrent-based reconstruction framework, including a Light-Robust Representation (LR-Rep) and a fusion module, to better handle such extreme conditions. LR-Rep is designed to aggregate temporal information in spike streams, and a fusion module is utilized to extract temporal features. Additionally, we have developed a reconstruction benchmark for high-speed low-light scenes. Light sources in the scenes are carefully aligned to real-world conditions. Experimental results demonstrate the superiority of our method, which also generalizes well to real spike streams. Related codes and proposed datasets will be released after publication.