 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOAP: Style-Omniscient Animatable Portraits
May 08, 2025
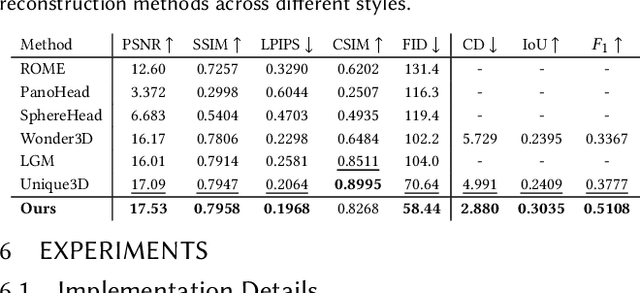
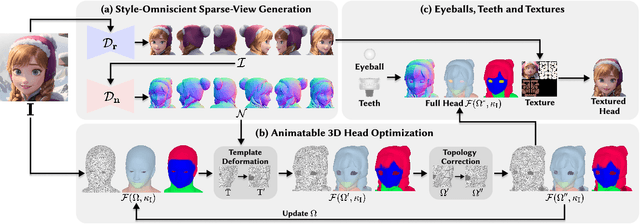
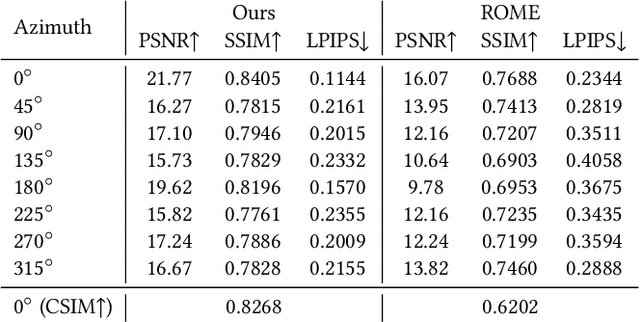
Creating animatable 3D avatars from a single image remains challenging due to style limitations (realistic, cartoon, anime) and difficulties in handling accessories or hairstyles. While 3D diffusion models advance single-view reconstruction for general objects, outputs often lack animation controls or suffer from artifacts because of the domain gap. We propose SOAP, a style-omniscient framework to generate rigged, topology-consistent avatars from any portrait. Our method leverages a multiview diffusion model trained on 24K 3D heads with multiple styles and an adaptive optimization pipeline to deform the FLAME mesh while maintaining topology and rigging via differentiable rendering. The resulting textured avatars support FACS-based animation, integrate with eyeballs and teeth, and preserve details like braided hair or accessories. Extensive experiments demonstrate the superiority of our method over state-of-the-art techniques for both single-view head modeling and diffusion-based generation of Image-to-3D. Our code and data are publicly available for research purposes at https://github.com/TingtingLiao/soap.
DiffPortrait360: Consistent Portrait Diffusion for 360 View Synthesis
Mar 19, 2025



Generating high-quality 360-degree views of human heads from single-view images is essential for enabling accessible immersive telepresence applications and scalable personalized content creation. While cutting-edge methods for full head generation are limited to modeling realistic human heads, the latest diffusion-based approaches for style-omniscient head synthesis can produce only frontal views and struggle with view consistency, preventing their conversion into true 3D models for rendering from arbitrary angles. We introduce a novel approach that generates fully consistent 360-degree head views, accommodating human, stylized, and anthropomorphic forms, including accessories like glasses and hats. Our method builds on the DiffPortrait3D framework, incorporating a custom ControlNet for back-of-head detail generation and a dual appearance module to ensure global front-back consistency. By training on continuous view sequences and integrating a back reference image, our approach achieves robust, locally continuous view synthesis. Our model can be used to produce high-quality neural radiance fields (NeRFs) for real-time, free-viewpoint rendering, outperforming state-of-the-art methods in object synthesis and 360-degree head generation for very challenging input portraits.
VOODOO XP: Expressive One-Shot Head Reenactment for VR Telepresence
May 28, 2024We introduce VOODOO XP: a 3D-aware one-shot head reenactment method that can generate highly expressive facial expressions from any input driver video and a single 2D portrait. Our solution is real-time, view-consistent, and can be instantly used without calibration or fine-tuning. We demonstrate our solution on a monocular video setting and an end-to-end VR telepresence system for two-way communication. Compared to 2D head reenactment methods, 3D-aware approaches aim to preserve the identity of the subject and ensure view-consistent facial geometry for novel camera poses, which makes them suitable for immersive applications. While various facial disentanglement techniques have been introduced, cutting-edge 3D-aware neural reenactment techniques still lack expressiveness and fail to reproduce complex and fine-scale facial expressions. We present a novel cross-reenactment architecture that directly transfers the driver's facial expressions to transformer blocks of the input source's 3D lifting module. We show that highly effective disentanglement is possible using an innovative multi-stage self-supervision approach, which is based on a coarse-to-fine strategy, combined with an explicit face neutralization and 3D lifted frontalization during its initial training stage. We further integrate our novel head reenactment solution into an accessible high-fidelity VR telepresence system, where any person can instantly build a personalized neural head avatar from any photo and bring it to life using the headset. We demonstrate state-of-the-art performance in terms of expressiveness and likeness preservation on a large set of diverse subjects and capture conditions.
Efficient Test-Time Adaptation of Vision-Language Models
Mar 27, 2024
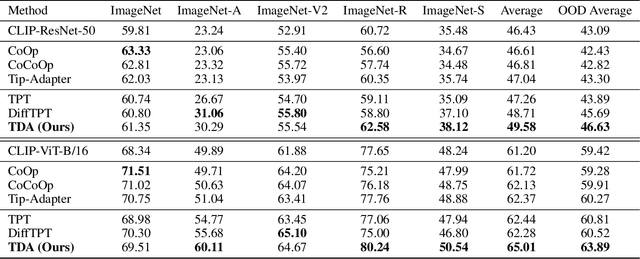
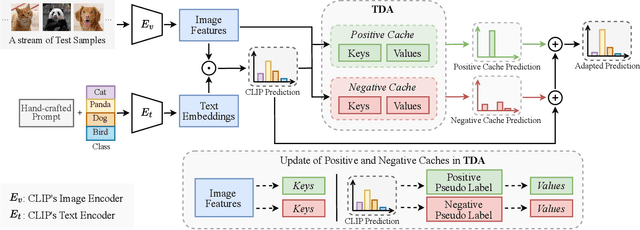

Test-time adaptation with pre-trained vision-language models has attracted increasing attention for tackling distribution shifts during the test time. Though prior studies have achieved very promising performance, they involve intensive computation which is severely unaligned with test-time adaptation. We design TDA, a training-free dynamic adapter that enables effective and efficient test-time adaptation with vision-language models. TDA works with a lightweight key-value cache that maintains a dynamic queue with few-shot pseudo labels as values and the corresponding test-sample features as keys. Leveraging the key-value cache, TDA allows adapting to test data gradually via progressive pseudo label refinement which is super-efficient without incurring any backpropagation. In addition, we introduce negative pseudo labeling that alleviates the adverse impact of pseudo label noises by assigning pseudo labels to certain negative classes when the model is uncertain about its pseudo label predictions. Extensive experiments over two benchmarks demonstrate TDA's superior effectiveness and efficiency as compared with the state-of-the-art. The code has been released in \url{https://kdiaaa.github.io/tda/}.