 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCondition Matters in Full-head 3D GANs
Feb 06, 2026Conditioning is crucial for stable training of full-head 3D GANs. Without any conditioning signal, the model suffers from severe mode collapse, making it impractical to training. However, a series of previous full-head 3D GANs conventionally choose the view angle as the conditioning input, which leads to a bias in the learned 3D full-head space along the conditional view direction. This is evident in the significant differences in generation quality and diversity between the conditional view and non-conditional views of the generated 3D heads, resulting in global incoherence across different head regions. In this work, we propose to use view-invariant semantic feature as the conditioning input, thereby decoupling the generative capability of 3D heads from the viewing direction. To construct a view-invariant semantic condition for each training image, we create a novel synthesized head image dataset. We leverage FLUX.1 Kontext to extend existing high-quality frontal face datasets to a wide range of view angles. The image clip feature extracted from the frontal view is then used as a shared semantic condition across all views in the extended images, ensuring semantic alignment while eliminating directional bias. This also allows supervision from different views of the same subject to be consolidated under a shared semantic condition, which accelerates training and enhances the global coherence of the generated 3D heads. Moreover, as GANs often experience slower improvements in diversity once the generator learns a few modes that successfully fool the discriminator, our semantic conditioning encourages the generator to follow the true semantic distribution, thereby promoting continuous learning and diverse generation. Extensive experiments on full-head synthesis and single-view GAN inversion demonstrate that our method achieves significantly higher fidelity, diversity, and generalizability.
Envision: Embodied Visual Planning via Goal-Imagery Video Diffusion
Dec 27, 2025Embodied visual planning aims to enable manipulation tasks by imagining how a scene evolves toward a desired goal and using the imagined trajectories to guide actions. Video diffusion models, through their image-to-video generation capability, provide a promising foundation for such visual imagination. However, existing approaches are largely forward predictive, generating trajectories conditioned on the initial observation without explicit goal modeling, thus often leading to spatial drift and goal misalignment. To address these challenges, we propose Envision, a diffusion-based framework that performs visual planning for embodied agents. By explicitly constraining the generation with a goal image, our method enforces physical plausibility and goal consistency throughout the generated trajectory. Specifically, Envision operates in two stages. First, a Goal Imagery Model identifies task-relevant regions, performs region-aware cross attention between the scene and the instruction, and synthesizes a coherent goal image that captures the desired outcome. Then, an Env-Goal Video Model, built upon a first-and-last-frame-conditioned video diffusion model (FL2V), interpolates between the initial observation and the goal image, producing smooth and physically plausible video trajectories that connect the start and goal states. Experiments on object manipulation and image editing benchmarks demonstrate that Envision achieves superior goal alignment, spatial consistency, and object preservation compared to baselines. The resulting visual plans can directly support downstream robotic planning and control, providing reliable guidance for embodied agents.
DiffPortrait360: Consistent Portrait Diffusion for 360 View Synthesis
Mar 19, 2025



Generating high-quality 360-degree views of human heads from single-view images is essential for enabling accessible immersive telepresence applications and scalable personalized content creation. While cutting-edge methods for full head generation are limited to modeling realistic human heads, the latest diffusion-based approaches for style-omniscient head synthesis can produce only frontal views and struggle with view consistency, preventing their conversion into true 3D models for rendering from arbitrary angles. We introduce a novel approach that generates fully consistent 360-degree head views, accommodating human, stylized, and anthropomorphic forms, including accessories like glasses and hats. Our method builds on the DiffPortrait3D framework, incorporating a custom ControlNet for back-of-head detail generation and a dual appearance module to ensure global front-back consistency. By training on continuous view sequences and integrating a back reference image, our approach achieves robust, locally continuous view synthesis. Our model can be used to produce high-quality neural radiance fields (NeRFs) for real-time, free-viewpoint rendering, outperforming state-of-the-art methods in object synthesis and 360-degree head generation for very challenging input portraits.
Leveraging Synthetic Data for Generalizable and Fair Facial Action Unit Detection
Mar 15, 2024



Facial action unit (AU) detection is a fundamental block for objective facial expression analysis. Supervised learning approaches require a large amount of manual labeling which is costly. The limited labeled data are also not diverse in terms of gender which can affect model fairness. In this paper, we propose to use synthetically generated data and multi-source domain adaptation (MSDA) to address the problems of the scarcity of labeled data and the diversity of subjects. Specifically, we propose to generate a diverse dataset through synthetic facial expression re-targeting by transferring the expressions from real faces to synthetic avatars. Then, we use MSDA to transfer the AU detection knowledge from a real dataset and the synthetic dataset to a target dataset. Instead of aligning the overall distributions of different domains, we propose Paired Moment Matching (PM2) to align the features of the paired real and synthetic data with the same facial expression. To further improve gender fairness, PM2 matches the features of the real data with a female and a male synthetic image. Our results indicate that synthetic data and the proposed model improve both AU detection performance and fairness across genders, demonstrating its potential to solve AU detection in-the-wild.
DiffPortrait3D: Controllable Diffusion for Zero-Shot Portrait View Synthesis
Dec 22, 2023



We present DiffPortrait3D, a conditional diffusion model that is capable of synthesizing 3D-consistent photo-realistic novel views from as few as a single in-the-wild portrait. Specifically, given a single RGB input, we aim to synthesize plausible but consistent facial details rendered from novel camera views with retained both identity and facial expression. In lieu of time-consuming optimization and fine-tuning, our zero-shot method generalizes well to arbitrary face portraits with unposed camera views, extreme facial expressions, and diverse artistic depictions. At its core, we leverage the generative prior of 2D diffusion models pre-trained on large-scale image datasets as our rendering backbone, while the denoising is guided with disentangled attentive control of appearance and camera pose. To achieve this, we first inject the appearance context from the reference image into the self-attention layers of the frozen UNets. The rendering view is then manipulated with a novel conditional control module that interprets the camera pose by watching a condition image of a crossed subject from the same view. Furthermore, we insert a trainable cross-view attention module to enhance view consistency, which is further strengthened with a novel 3D-aware noise generation process during inference. We demonstrate state-of-the-art results both qualitatively and quantitatively on our challenging in-the-wild and multi-view benchmarks.
DisUnknown: Distilling Unknown Factors for Disentanglement Learning
Sep 16, 2021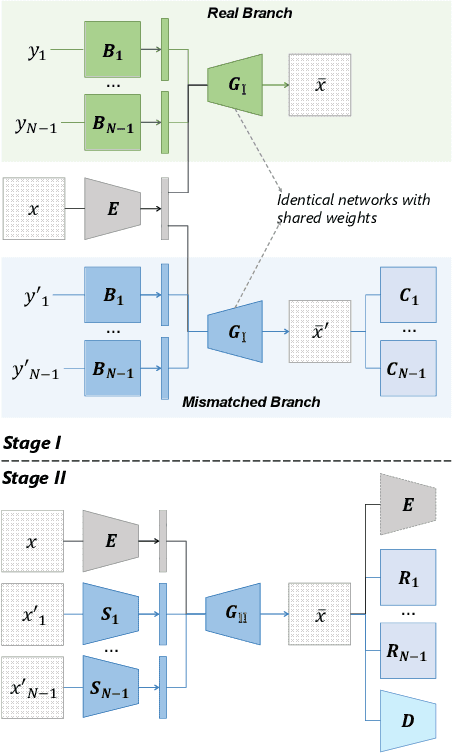
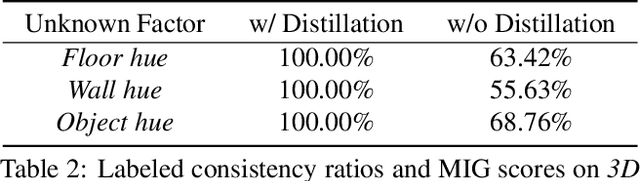


Disentangling data into interpretable and independent factors is critical for controllable generation tasks. With the availability of labeled data, supervision can help enforce the separation of specific factors as expected. However, it is often expensive or even impossible to label every single factor to achieve fully-supervised disentanglement. In this paper, we adopt a general setting where all factors that are hard to label or identify are encapsulated as a single unknown factor. Under this setting, we propose a flexible weakly-supervised multi-factor disentanglement framework DisUnknown, which Distills Unknown factors for enabling multi-conditional generation regarding both labeled and unknown factors. Specifically, a two-stage training approach is adopted to first disentangle the unknown factor with an effective and robust training method, and then train the final generator with the proper disentanglement of all labeled factors utilizing the unknown distillation. To demonstrate the generalization capacity and scalability of our method, we evaluate it on multiple benchmark datasets qualitatively and quantitatively and further apply it to various real-world applications on complicated datasets.
One-Shot Identity-Preserving Portrait Reenactment
Apr 26, 2020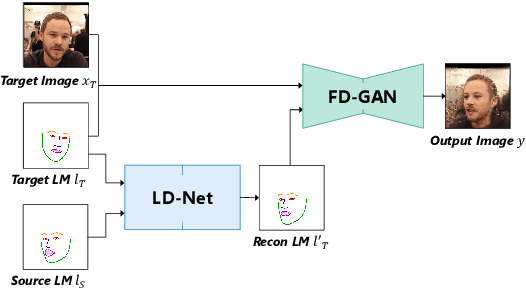

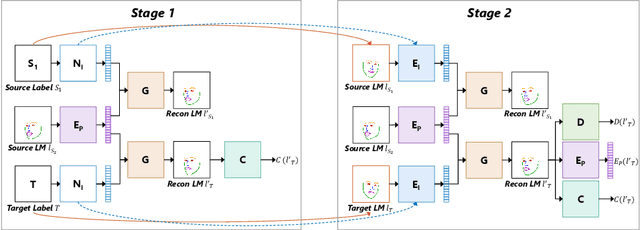

We present a deep learning-based framework for portrait reenactment from a single picture of a target (one-shot) and a video of a driving subject. Existing facial reenactment methods suffer from identity mismatch and produce inconsistent identities when a target and a driving subject are different (cross-subject), especially in one-shot settings. In this work, we aim to address identity preservation in cross-subject portrait reenactment from a single picture. We introduce a novel technique that can disentangle identity from expressions and poses, allowing identity preserving portrait reenactment even when the driver's identity is very different from that of the target. This is achieved by a novel landmark disentanglement network (LD-Net), which predicts personalized facial landmarks that combine the identity of the target with expressions and poses from a different subject. To handle portrait reenactment from unseen subjects, we also introduce a feature dictionary-based generative adversarial network (FD-GAN), which locally translates 2D landmarks into a personalized portrait, enabling one-shot portrait reenactment under large pose and expression variations. We validate the effectiveness of our identity disentangling capabilities via an extensive ablation study, and our method produces consistent identities for cross-subject portrait reenactment. Our comprehensive experiments show that our method significantly outperforms the state-of-the-art single-image facial reenactment methods. We will release our code and models for academic use.