 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Synthetic Data for Generalizable and Fair Facial Action Unit Detection
Mar 15, 2024



Facial action unit (AU) detection is a fundamental block for objective facial expression analysis. Supervised learning approaches require a large amount of manual labeling which is costly. The limited labeled data are also not diverse in terms of gender which can affect model fairness. In this paper, we propose to use synthetically generated data and multi-source domain adaptation (MSDA) to address the problems of the scarcity of labeled data and the diversity of subjects. Specifically, we propose to generate a diverse dataset through synthetic facial expression re-targeting by transferring the expressions from real faces to synthetic avatars. Then, we use MSDA to transfer the AU detection knowledge from a real dataset and the synthetic dataset to a target dataset. Instead of aligning the overall distributions of different domains, we propose Paired Moment Matching (PM2) to align the features of the paired real and synthetic data with the same facial expression. To further improve gender fairness, PM2 matches the features of the real data with a female and a male synthetic image. Our results indicate that synthetic data and the proposed model improve both AU detection performance and fairness across genders, demonstrating its potential to solve AU detection in-the-wild.
Hearing Loss Detection from Facial Expressions in One-on-one Conversations
Jan 17, 2024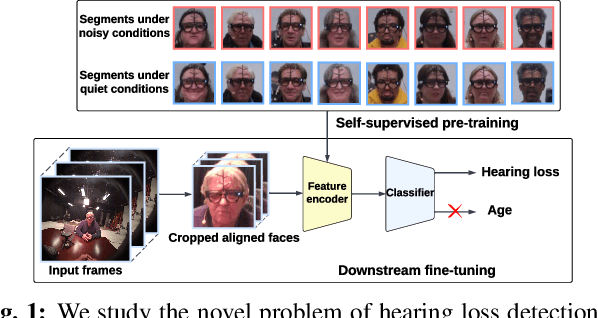
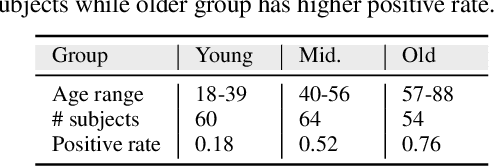
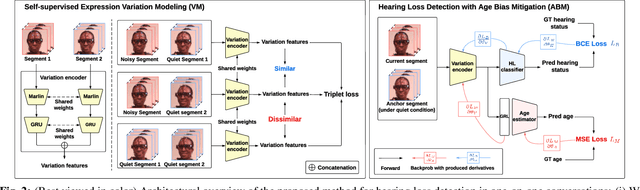
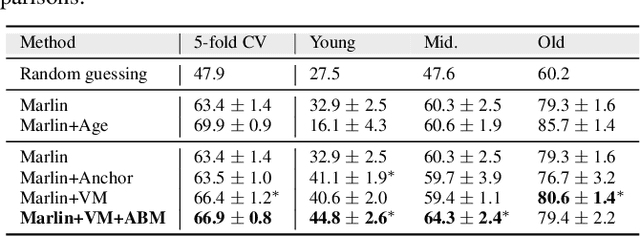
Individuals with impaired hearing experience difficulty in conversations, especially in noisy environments. This difficulty often manifests as a change in behavior and may be captured via facial expressions, such as the expression of discomfort or fatigue. In this work, we build on this idea and introduce the problem of detecting hearing loss from an individual's facial expressions during a conversation. Building machine learning models that can represent hearing-related facial expression changes is a challenge. In addition, models need to disentangle spurious age-related correlations from hearing-driven expressions. To this end, we propose a self-supervised pre-training strategy tailored for the modeling of expression variations. We also use adversarial representation learning to mitigate the age bias. We evaluate our approach on a large-scale egocentric dataset with real-world conversational scenarios involving subjects with hearing loss and show that our method for hearing loss detection achieves superior performance over baselines.
Personalized Adaptation with Pre-trained Speech Encoders for Continuous Emotion Recognition
Sep 05, 2023There are individual differences in expressive behaviors driven by cultural norms and personality. This between-person variation can result in reduced emotion recognition performance. Therefore, personalization is an important step in improving the generalization and robustness of speech emotion recognition. In this paper, to achieve unsupervised personalized emotion recognition, we first pre-train an encoder with learnable speaker embeddings in a self-supervised manner to learn robust speech representations conditioned on speakers. Second, we propose an unsupervised method to compensate for the label distribution shifts by finding similar speakers and leveraging their label distributions from the training set. Extensive experimental results on the MSP-Podcast corpus indicate that our method consistently outperforms strong personalization baselines and achieves state-of-the-art performance for valence estimation.
LibreFace: An Open-Source Toolkit for Deep Facial Expression Analysis
Aug 24, 2023



Facial expression analysis is an important tool for human-computer interaction. In this paper, we introduce LibreFace, an open-source toolkit for facial expression analysis. This open-source toolbox offers real-time and offline analysis of facial behavior through deep learning models, including facial action unit (AU) detection, AU intensity estimation, and facial expression recognition. To accomplish this, we employ several techniques, including the utilization of a large-scale pre-trained network, feature-wise knowledge distillation, and task-specific fine-tuning. These approaches are designed to effectively and accurately analyze facial expressions by leveraging visual information, thereby facilitating the implementation of real-time interactive applications. In terms of Action Unit (AU) intensity estimation, we achieve a Pearson Correlation Coefficient (PCC) of 0.63 on DISFA, which is 7% higher than the performance of OpenFace 2.0 while maintaining highly-efficient inference that runs two times faster than OpenFace 2.0. Despite being compact, our model also demonstrates competitive performance to state-of-the-art facial expression analysis methods on AffecNet, FFHQ, and RAF-DB. Our code will be released at https://github.com/ihp-lab/LibreFace
FG-Net: Facial Action Unit Detection with Generalizable Pyramidal Features
Aug 23, 2023



Automatic detection of facial Action Units (AUs) allows for objective facial expression analysis. Due to the high cost of AU labeling and the limited size of existing benchmarks, previous AU detection methods tend to overfit the dataset, resulting in a significant performance loss when evaluated across corpora. To address this problem, we propose FG-Net for generalizable facial action unit detection. Specifically, FG-Net extracts feature maps from a StyleGAN2 model pre-trained on a large and diverse face image dataset. Then, these features are used to detect AUs with a Pyramid CNN Interpreter, making the training efficient and capturing essential local features. The proposed FG-Net achieves a strong generalization ability for heatmap-based AU detection thanks to the generalizable and semantic-rich features extracted from the pre-trained generative model. Extensive experiments are conducted to evaluate within- and cross-corpus AU detection with the widely-used DISFA and BP4D datasets. Compared with the state-of-the-art, the proposed method achieves superior cross-domain performance while maintaining competitive within-domain performance. In addition, FG-Net is data-efficient and achieves competitive performance even when trained on 1000 samples. Our code will be released at \url{https://github.com/ihp-lab/FG-Net}
Multi-modal Facial Action Unit Detection with Large Pre-trained Models for the 5th Competition on Affective Behavior Analysis in-the-wild
Mar 23, 2023Facial action unit detection has emerged as an important task within facial expression analysis, aimed at detecting specific pre-defined, objective facial expressions, such as lip tightening and cheek raising. This paper presents our submission to the Affective Behavior Analysis in-the-wild (ABAW) 2023 Competition for AU detection. We propose a multi-modal method for facial action unit detection with visual, acoustic, and lexical features extracted from the large pre-trained models. To provide high-quality details for visual feature extraction, we apply super-resolution and face alignment to the training data and show potential performance gain. Our approach achieves the F1 score of 52.3% on the official validation set of the 5th ABAW Challenge.