 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing Loss Detection from Facial Expressions in One-on-one Conversations
Jan 17, 2024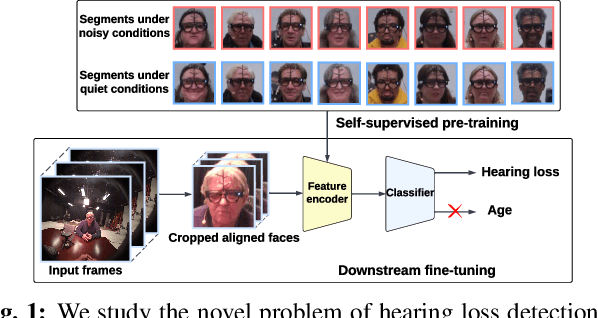
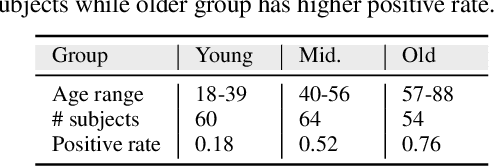
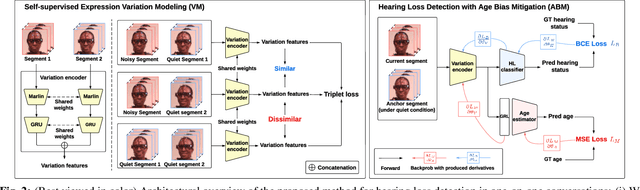
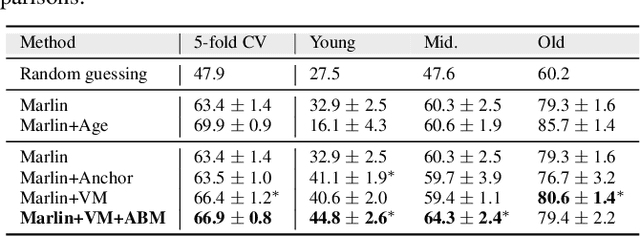
Individuals with impaired hearing experience difficulty in conversations, especially in noisy environments. This difficulty often manifests as a change in behavior and may be captured via facial expressions, such as the expression of discomfort or fatigue. In this work, we build on this idea and introduce the problem of detecting hearing loss from an individual's facial expressions during a conversation. Building machine learning models that can represent hearing-related facial expression changes is a challenge. In addition, models need to disentangle spurious age-related correlations from hearing-driven expressions. To this end, we propose a self-supervised pre-training strategy tailored for the modeling of expression variations. We also use adversarial representation learning to mitigate the age bias. We evaluate our approach on a large-scale egocentric dataset with real-world conversational scenarios involving subjects with hearing loss and show that our method for hearing loss detection achieves superior performance over baselines.
Evaluating and Optimizing Hearing-Aid Self-Fitting Methods using Population Coverage
Oct 25, 2022Adults with mild-to-moderate hearing loss can use over-the-counter hearing aids to treat their hearing loss at a fraction of traditional hearing care costs. These products incorporate self-fitting methods that allow end-users to configure their hearing aids without the help of an audiologist. A self-fitting method helps users configure the gain-frequency responses that control the amplification for each frequency band of the incoming sound. This paper considers how to design effective self-fitting methods and whether we may evaluate certain aspects of their design without resorting to expensive user studies. Most existing fitting methods provide various user interfaces to allow users to select a configuration from a predetermined set of presets. We propose a novel metric for evaluating the performance of preset-based approaches by computing their population coverage. The population coverage estimates the fraction of users for which it is possible to find a configuration they prefer. A unique aspect of our approach is a probabilistic model that captures how a user's unique preferences differ from other users with similar hearing loss. Next, we develop methods for determining presets to maximize population coverage. Exploratory results demonstrate that the proposed algorithms can effectively select a small number of presets that provide higher population coverage than clustering-based approaches. Moreover, we may use our algorithms to configure the number of increments for slider-based methods.