 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalized Gaussian Splatting Editing with Contextual Awareness
Jul 31, 2024



Recent text-guided generation of individual 3D object has achieved great success using diffusion priors. However, these methods are not suitable for object insertion and replacement tasks as they do not consider the background, leading to illumination mismatches within the environment. To bridge the gap, we introduce an illumination-aware 3D scene editing pipeline for 3D Gaussian Splatting (3DGS) representation. Our key observation is that inpainting by the state-of-the-art conditional 2D diffusion model is consistent with background in lighting. To leverage the prior knowledge from the well-trained diffusion models for 3D object generation, our approach employs a coarse-to-fine objection optimization pipeline with inpainted views. In the first coarse step, we achieve image-to-3D lifting given an ideal inpainted view. The process employs 3D-aware diffusion prior from a view-conditioned diffusion model, which preserves illumination present in the conditioning image. To acquire an ideal inpainted image, we introduce an Anchor View Proposal (AVP) algorithm to find a single view that best represents the scene illumination in target region. In the second Texture Enhancement step, we introduce a novel Depth-guided Inpainting Score Distillation Sampling (DI-SDS), which enhances geometry and texture details with the inpainting diffusion prior, beyond the scope of the 3D-aware diffusion prior knowledge in the first coarse step. DI-SDS not only provides fine-grained texture enhancement, but also urges optimization to respect scene lighting. Our approach efficiently achieves local editing with global illumination consistency without explicitly modeling light transport. We demonstrate robustness of our method by evaluating editing in real scenes containing explicit highlight and shadows, and compare against the state-of-the-art text-to-3D editing methods.
Leveraging Synthetic Data for Generalizable and Fair Facial Action Unit Detection
Mar 15, 2024



Facial action unit (AU) detection is a fundamental block for objective facial expression analysis. Supervised learning approaches require a large amount of manual labeling which is costly. The limited labeled data are also not diverse in terms of gender which can affect model fairness. In this paper, we propose to use synthetically generated data and multi-source domain adaptation (MSDA) to address the problems of the scarcity of labeled data and the diversity of subjects. Specifically, we propose to generate a diverse dataset through synthetic facial expression re-targeting by transferring the expressions from real faces to synthetic avatars. Then, we use MSDA to transfer the AU detection knowledge from a real dataset and the synthetic dataset to a target dataset. Instead of aligning the overall distributions of different domains, we propose Paired Moment Matching (PM2) to align the features of the paired real and synthetic data with the same facial expression. To further improve gender fairness, PM2 matches the features of the real data with a female and a male synthetic image. Our results indicate that synthetic data and the proposed model improve both AU detection performance and fairness across genders, demonstrating its potential to solve AU detection in-the-wild.
Learning Formation of Physically-Based Face Attributes
Apr 24, 2020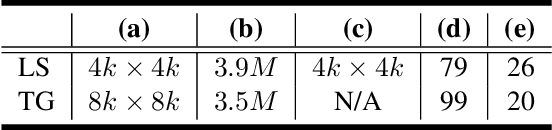

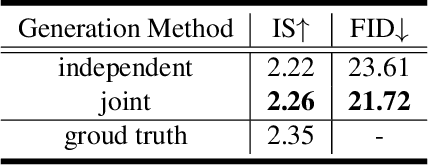
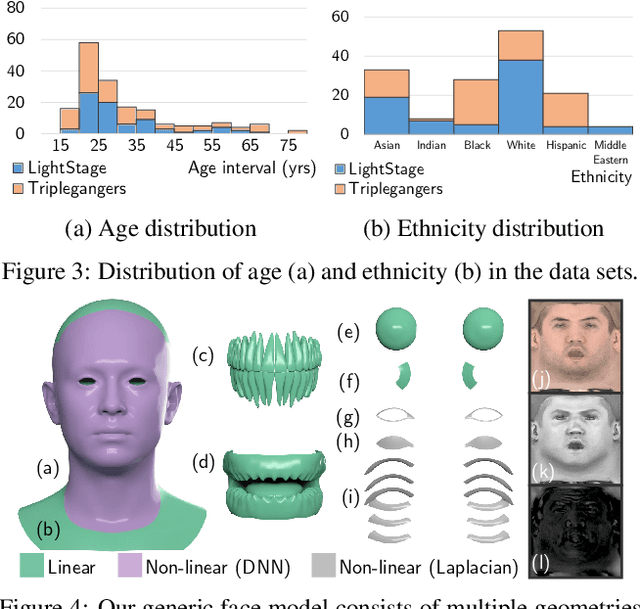
Based on a combined data set of 4000 high resolution facial scans, we introduce a non-linear morphable face model, capable of producing multifarious face geometry of pore-level resolution, coupled with material attributes for use in physically-based rendering. We aim to maximize the variety of face identities, while increasing the robustness of correspondence between unique components, including middle-frequency geometry, albedo maps, specular intensity maps and high-frequency displacement details. Our deep learning based generative model learns to correlate albedo and geometry, which ensures the anatomical correctness of the generated assets. We demonstrate potential use of our generative model for novel identity generation, model fitting, interpolation, animation, high fidelity data visualization, and low-to-high resolution data domain transferring. We hope the release of this generative model will encourage further cooperation between all graphics, vision, and data focused professionals while demonstrating the cumulative value of every individual's complete biometric profile.