 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC-OmniGS: Self-Calibrating Omnidirectional Gaussian Splatting
Feb 07, 2025



360-degree cameras streamline data collection for radiance field 3D reconstruction by capturing comprehensive scene data. However, traditional radiance field methods do not address the specific challenges inherent to 360-degree images. We present SC-OmniGS, a novel self-calibrating omnidirectional Gaussian splatting system for fast and accurate omnidirectional radiance field reconstruction using 360-degree images. Rather than converting 360-degree images to cube maps and performing perspective image calibration, we treat 360-degree images as a whole sphere and derive a mathematical framework that enables direct omnidirectional camera pose calibration accompanied by 3D Gaussians optimization. Furthermore, we introduce a differentiable omnidirectional camera model in order to rectify the distortion of real-world data for performance enhancement. Overall, the omnidirectional camera intrinsic model, extrinsic poses, and 3D Gaussians are jointly optimized by minimizing weighted spherical photometric loss. Extensive experiments have demonstrated that our proposed SC-OmniGS is able to recover a high-quality radiance field from noisy camera poses or even no pose prior in challenging scenarios characterized by wide baselines and non-object-centric configurations. The noticeable performance gain in the real-world dataset captured by consumer-grade omnidirectional cameras verifies the effectiveness of our general omnidirectional camera model in reducing the distortion of 360-degree images.
Localized Gaussian Splatting Editing with Contextual Awareness
Jul 31, 2024



Recent text-guided generation of individual 3D object has achieved great success using diffusion priors. However, these methods are not suitable for object insertion and replacement tasks as they do not consider the background, leading to illumination mismatches within the environment. To bridge the gap, we introduce an illumination-aware 3D scene editing pipeline for 3D Gaussian Splatting (3DGS) representation. Our key observation is that inpainting by the state-of-the-art conditional 2D diffusion model is consistent with background in lighting. To leverage the prior knowledge from the well-trained diffusion models for 3D object generation, our approach employs a coarse-to-fine objection optimization pipeline with inpainted views. In the first coarse step, we achieve image-to-3D lifting given an ideal inpainted view. The process employs 3D-aware diffusion prior from a view-conditioned diffusion model, which preserves illumination present in the conditioning image. To acquire an ideal inpainted image, we introduce an Anchor View Proposal (AVP) algorithm to find a single view that best represents the scene illumination in target region. In the second Texture Enhancement step, we introduce a novel Depth-guided Inpainting Score Distillation Sampling (DI-SDS), which enhances geometry and texture details with the inpainting diffusion prior, beyond the scope of the 3D-aware diffusion prior knowledge in the first coarse step. DI-SDS not only provides fine-grained texture enhancement, but also urges optimization to respect scene lighting. Our approach efficiently achieves local editing with global illumination consistency without explicitly modeling light transport. We demonstrate robustness of our method by evaluating editing in real scenes containing explicit highlight and shadows, and compare against the state-of-the-art text-to-3D editing methods.
360VOTS: Visual Object Tracking and Segmentation in Omnidirectional Videos
Apr 22, 2024Visual object tracking and segmentation in omnidirectional videos are challenging due to the wide field-of-view and large spherical distortion brought by 360{\deg} images. To alleviate these problems, we introduce a novel representation, extended bounding field-of-view (eBFoV), for target localization and use it as the foundation of a general 360 tracking framework which is applicable for both omnidirectional visual object tracking and segmentation tasks. Building upon our previous work on omnidirectional visual object tracking (360VOT), we propose a comprehensive dataset and benchmark that incorporates a new component called omnidirectional video object segmentation (360VOS). The 360VOS dataset includes 290 sequences accompanied by dense pixel-wise masks and covers a broader range of target categories. To support both the development and evaluation of algorithms in this domain, we divide the dataset into a training subset with 170 sequences and a testing subset with 120 sequences. Furthermore, we tailor evaluation metrics for both omnidirectional tracking and segmentation to ensure rigorous assessment. Through extensive experiments, we benchmark state-of-the-art approaches and demonstrate the effectiveness of our proposed 360 tracking framework and training dataset. Homepage: https://360vots.hkustvgd.com/
StyleCity: Large-Scale 3D Urban Scenes Stylization with Vision-and-Text Reference via Progressive Optimization
Apr 16, 2024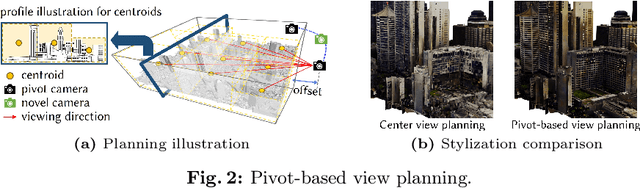



Creating large-scale virtual urban scenes with variant styles is inherently challenging. To facilitate prototypes of virtual production and bypass the need for complex materials and lighting setups, we introduce the first vision-and-text-driven texture stylization system for large-scale urban scenes, StyleCity. Taking an image and text as references, StyleCity stylizes a 3D textured mesh of a large-scale urban scene in a semantics-aware fashion and generates a harmonic omnidirectional sky background. To achieve that, we propose to stylize a neural texture field by transferring 2D vision-and-text priors to 3D globally and locally. During 3D stylization, we progressively scale the planned training views of the input 3D scene at different levels in order to preserve high-quality scene content. We then optimize the scene style globally by adapting the scale of the style image with the scale of the training views. Moreover, we enhance local semantics consistency by the semantics-aware style loss which is crucial for photo-realistic stylization. Besides texture stylization, we further adopt a generative diffusion model to synthesize a style-consistent omnidirectional sky image, which offers a more immersive atmosphere and assists the semantic stylization process. The stylized neural texture field can be baked into an arbitrary-resolution texture, enabling seamless integration into conventional rendering pipelines and significantly easing the virtual production prototyping process. Extensive experiments demonstrate our stylized scenes' superiority in qualitative and quantitative performance and user preferences.
Advances in 3D Neural Stylization: A Survey
Nov 30, 2023


Modern artificial intelligence provides a novel way of producing digital art in styles. The expressive power of neural networks enables the realm of visual style transfer methods, which can be used to edit images, videos, and 3D data to make them more artistic and diverse. This paper reports on recent advances in neural stylization for 3D data. We provide a taxonomy for neural stylization by considering several important design choices, including scene representation, guidance data, optimization strategies, and output styles. Building on such taxonomy, our survey first revisits the background of neural stylization on 2D images, and then provides in-depth discussions on recent neural stylization methods for 3D data, where we also provide a mini-benchmark on artistic stylization methods. Based on the insights gained from the survey, we then discuss open challenges, future research, and potential applications and impacts of neural stylization.
360VOT: A New Benchmark Dataset for Omnidirectional Visual Object Tracking
Jul 27, 2023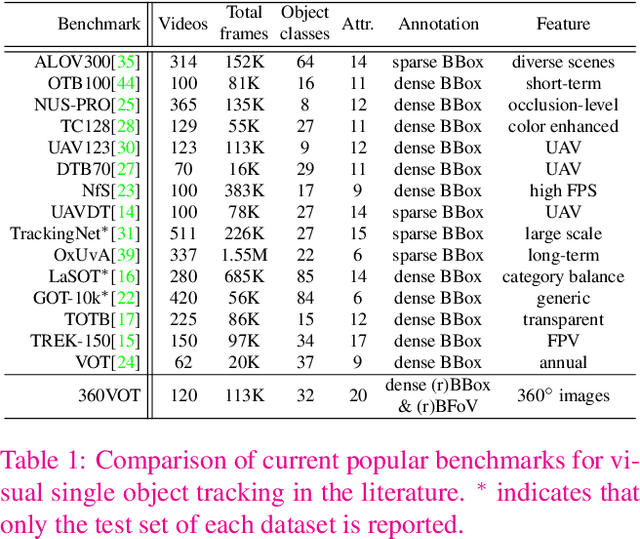



360{\deg} images can provide an omnidirectional field of view which is important for stable and long-term scene perception. In this paper, we explore 360{\deg} images for visual object tracking and perceive new challenges caused by large distortion, stitching artifacts, and other unique attributes of 360{\deg} images. To alleviate these problems, we take advantage of novel representations of target localization, i.e., bounding field-of-view, and then introduce a general 360 tracking framework that can adopt typical trackers for omnidirectional tracking. More importantly, we propose a new large-scale omnidirectional tracking benchmark dataset, 360VOT, in order to facilitate future research. 360VOT contains 120 sequences with up to 113K high-resolution frames in equirectangular projection. The tracking targets cover 32 categories in diverse scenarios. Moreover, we provide 4 types of unbiased ground truth, including (rotated) bounding boxes and (rotated) bounding field-of-views, as well as new metrics tailored for 360{\deg} images which allow for the accurate evaluation of omnidirectional tracking performance. Finally, we extensively evaluated 20 state-of-the-art visual trackers and provided a new baseline for future comparisons. Homepage: https://360vot.hkustvgd.com
Time-of-Day Neural Style Transfer for Architectural Photographs
Sep 13, 2022

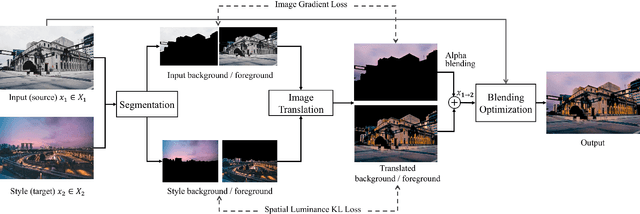

Architectural photography is a genre of photography that focuses on capturing a building or structure in the foreground with dramatic lighting in the background. Inspired by recent successes in image-to-image translation methods, we aim to perform style transfer for architectural photographs. However, the special composition in architectural photography poses great challenges for style transfer in this type of photographs. Existing neural style transfer methods treat the architectural images as a single entity, which would generate mismatched chrominance and destroy geometric features of the original architecture, yielding unrealistic lighting, wrong color rendition, and visual artifacts such as ghosting, appearance distortion, or color mismatching. In this paper, we specialize a neural style transfer method for architectural photography. Our method addresses the composition of the foreground and background in an architectural photograph in a two-branch neural network that separately considers the style transfer of the foreground and the background, respectively. Our method comprises a segmentation module, a learning-based image-to-image translation module, and an image blending optimization module. We trained our image-to-image translation neural network with a new dataset of unconstrained outdoor architectural photographs captured at different magic times of a day, utilizing additional semantic information for better chrominance matching and geometry preservation. Our experiments show that our method can produce photorealistic lighting and color rendition on both the foreground and background, and outperforms general image-to-image translation and arbitrary style transfer baselines quantitatively and qualitatively. Our code and data are available at https://github.com/hkust-vgd/architectural_style_transfer.
360Roam: Real-Time Indoor Roaming Using Geometry-Aware ${360^\circ}$ Radiance Fields
Aug 04, 2022
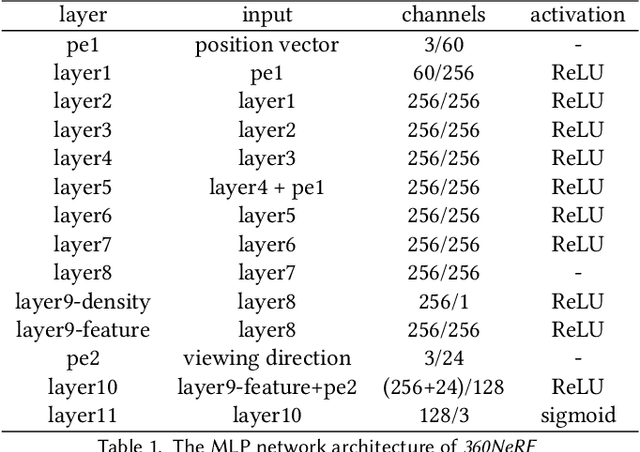
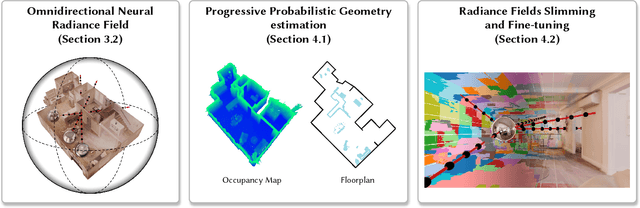
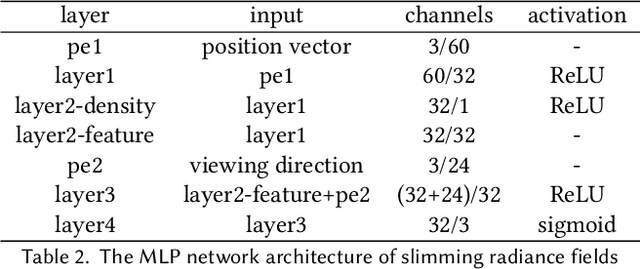
Neural radiance field (NeRF) has recently achieved impressive results in novel view synthesis. However, previous works on NeRF mainly focus on object-centric scenarios. In this work, we propose 360Roam, a novel scene-level NeRF system that can synthesize images of large-scale indoor scenes in real time and support VR roaming. Our system first builds an omnidirectional neural radiance field 360NeRF from multiple input $360^\circ$ images. Using 360NeRF, we then progressively estimate a 3D probabilistic occupancy map which represents the scene geometry in the form of spacial density. Skipping empty spaces and upsampling occupied voxels essentially allows us to accelerate volume rendering by using 360NeRF in a geometry-aware fashion. Furthermore, we use an adaptive divide-and-conquer strategy to slim and fine-tune the radiance fields for further improvement. The floorplan of the scene extracted from the occupancy map can provide guidance for ray sampling and facilitate a realistic roaming experience. To show the efficacy of our system, we collect a $360^\circ$ image dataset in a large variety of scenes and conduct extensive experiments. Quantitative and qualitative comparisons among baselines illustrated our predominant performance in novel view synthesis for complex indoor scenes.
Neural Scene Decoration from a Single Photograph
Aug 04, 2021
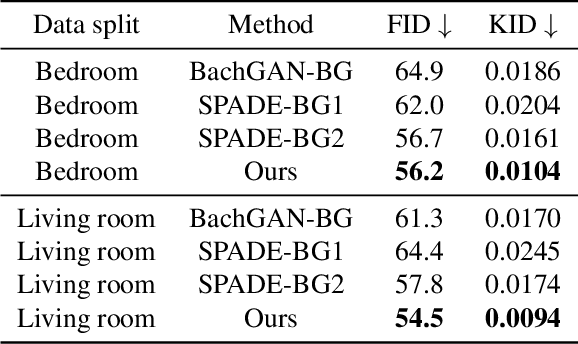
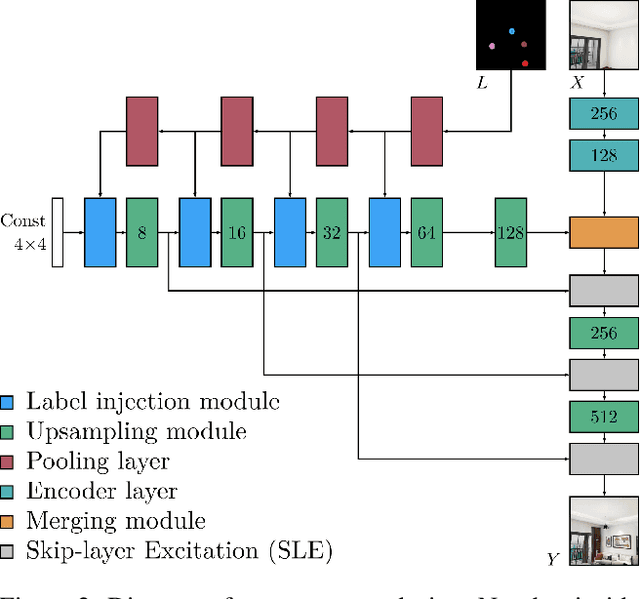
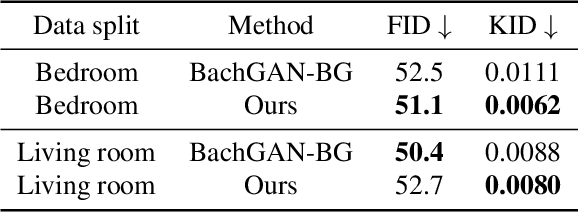
Furnishing and rendering an indoor scene is a common but tedious task for interior design: an artist needs to observe the space, create a conceptual design, build a 3D model, and perform rendering. In this paper, we introduce a new problem of domain-specific image synthesis using generative modeling, namely neural scene decoration. Given a photograph of an empty indoor space, we aim to synthesize a new image of the same space that is fully furnished and decorated. Neural scene decoration can be applied in practice to efficiently generate conceptual but realistic interior designs, bypassing the traditional multi-step and time-consuming pipeline. Our attempt to neural scene decoration in this paper is a generative adversarial neural network that takes the input photograph and directly produce the image of the desired furnishing and decorations. Our network contains a novel image generator that transforms an initial point-based object layout into a realistic photograph. We demonstrate the performance of our proposed method by showing that it outperforms the baselines built upon previous works on image translations both qualitatively and quantitatively. Our user study further validates the plausibility and aesthetics in the generated designs.