 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructMoLE: Instruction-Guided Mixture of Low-rank Experts for Multi-Conditional Image Generation
Dec 25, 2025Parameter-Efficient Fine-Tuning of Diffusion Transformers (DiTs) for diverse, multi-conditional tasks often suffers from task interference when using monolithic adapters like LoRA. The Mixture of Low-rank Experts (MoLE) architecture offers a modular solution, but its potential is usually limited by routing policies that operate at a token level. Such local routing can conflict with the global nature of user instructions, leading to artifacts like spatial fragmentation and semantic drift in complex image generation tasks. To address these limitations, we introduce InstructMoLE, a novel framework that employs an Instruction-Guided Mixture of Low-Rank Experts. Instead of per-token routing, InstructMoLE utilizes a global routing signal, Instruction-Guided Routing (IGR), derived from the user's comprehensive instruction. This ensures that a single, coherently chosen expert council is applied uniformly across all input tokens, preserving the global semantics and structural integrity of the generation process. To complement this, we introduce an output-space orthogonality loss, which promotes expert functional diversity and mitigates representational collapse. Extensive experiments demonstrate that InstructMoLE significantly outperforms existing LoRA adapters and MoLE variants across challenging multi-conditional generation benchmarks. Our work presents a robust and generalizable framework for instruction-driven fine-tuning of generative models, enabling superior compositional control and fidelity to user intent.
Lynx: Towards High-Fidelity Personalized Video Generation
Sep 19, 2025We present Lynx, a high-fidelity model for personalized video synthesis from a single input image. Built on an open-source Diffusion Transformer (DiT) foundation model, Lynx introduces two lightweight adapters to ensure identity fidelity. The ID-adapter employs a Perceiver Resampler to convert ArcFace-derived facial embeddings into compact identity tokens for conditioning, while the Ref-adapter integrates dense VAE features from a frozen reference pathway, injecting fine-grained details across all transformer layers through cross-attention. These modules collectively enable robust identity preservation while maintaining temporal coherence and visual realism. Through evaluation on a curated benchmark of 40 subjects and 20 unbiased prompts, which yielded 800 test cases, Lynx has demonstrated superior face resemblance, competitive prompt following, and strong video quality, thereby advancing the state of personalized video generation.
COAP: Memory-Efficient Training with Correlation-Aware Gradient Projection
Nov 26, 2024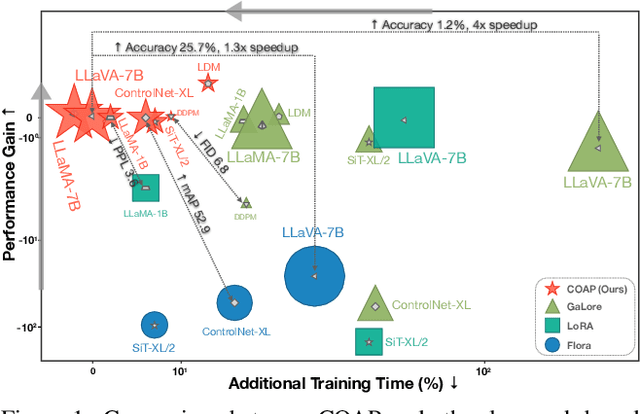
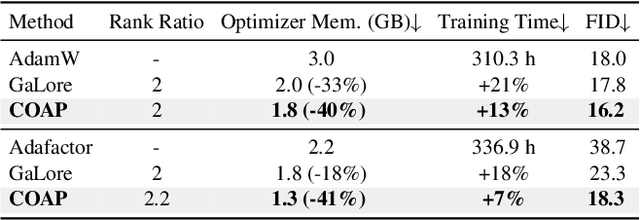
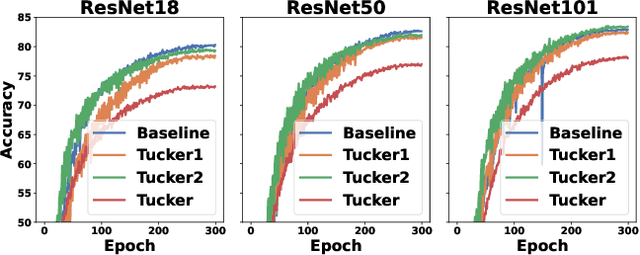
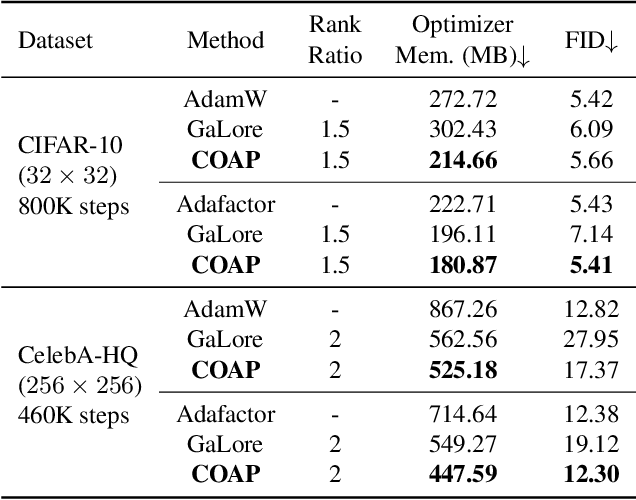
Training large-scale neural networks in vision, and multimodal domains demands substantial memory resources, primarily due to the storage of optimizer states. While LoRA, a popular parameter-efficient method, reduces memory usage, it often suffers from suboptimal performance due to the constraints of low-rank updates. Low-rank gradient projection methods (e.g., GaLore, Flora) reduce optimizer memory by projecting gradients and moment estimates into low-rank spaces via singular value decomposition or random projection. However, they fail to account for inter-projection correlation, causing performance degradation, and their projection strategies often incur high computational costs. In this paper, we present COAP (Correlation-Aware Gradient Projection), a memory-efficient method that minimizes computational overhead while maintaining training performance. Evaluated across various vision, language, and multimodal tasks, COAP outperforms existing methods in both training speed and model performance. For LLaMA-1B, it reduces optimizer memory by 61% with only 2% additional time cost, achieving the same PPL as AdamW. With 8-bit quantization, COAP cuts optimizer memory by 81% and achieves 4x speedup over GaLore for LLaVA-v1.5-7B fine-tuning, while delivering higher accuracy.
ID-Patch: Robust ID Association for Group Photo Personalization
Nov 20, 2024



The ability to synthesize personalized group photos and specify the positions of each identity offers immense creative potential. While such imagery can be visually appealing, it presents significant challenges for existing technologies. A persistent issue is identity (ID) leakage, where injected facial features interfere with one another, resulting in low face resemblance, incorrect positioning, and visual artifacts. Existing methods suffer from limitations such as the reliance on segmentation models, increased runtime, or a high probability of ID leakage. To address these challenges, we propose ID-Patch, a novel method that provides robust association between identities and 2D positions. Our approach generates an ID patch and ID embeddings from the same facial features: the ID patch is positioned on the conditional image for precise spatial control, while the ID embeddings integrate with text embeddings to ensure high resemblance. Experimental results demonstrate that ID-Patch surpasses baseline methods across metrics, such as face ID resemblance, ID-position association accuracy, and generation efficiency. Project Page is: https://byteaigc.github.io/ID-Patch/
Learning Feature-Preserving Portrait Editing from Generated Pairs
Jul 29, 2024Portrait editing is challenging for existing techniques due to difficulties in preserving subject features like identity. In this paper, we propose a training-based method leveraging auto-generated paired data to learn desired editing while ensuring the preservation of unchanged subject features. Specifically, we design a data generation process to create reasonably good training pairs for desired editing at low cost. Based on these pairs, we introduce a Multi-Conditioned Diffusion Model to effectively learn the editing direction and preserve subject features. During inference, our model produces accurate editing mask that can guide the inference process to further preserve detailed subject features. Experiments on costume editing and cartoon expression editing show that our method achieves state-of-the-art quality, quantitatively and qualitatively.
FG-Net: Facial Action Unit Detection with Generalizable Pyramidal Features
Aug 23, 2023



Automatic detection of facial Action Units (AUs) allows for objective facial expression analysis. Due to the high cost of AU labeling and the limited size of existing benchmarks, previous AU detection methods tend to overfit the dataset, resulting in a significant performance loss when evaluated across corpora. To address this problem, we propose FG-Net for generalizable facial action unit detection. Specifically, FG-Net extracts feature maps from a StyleGAN2 model pre-trained on a large and diverse face image dataset. Then, these features are used to detect AUs with a Pyramid CNN Interpreter, making the training efficient and capturing essential local features. The proposed FG-Net achieves a strong generalization ability for heatmap-based AU detection thanks to the generalizable and semantic-rich features extracted from the pre-trained generative model. Extensive experiments are conducted to evaluate within- and cross-corpus AU detection with the widely-used DISFA and BP4D datasets. Compared with the state-of-the-art, the proposed method achieves superior cross-domain performance while maintaining competitive within-domain performance. In addition, FG-Net is data-efficient and achieves competitive performance even when trained on 1000 samples. Our code will be released at \url{https://github.com/ihp-lab/FG-Net}
ActorsNeRF: Animatable Few-shot Human Rendering with Generalizable NeRFs
Apr 27, 2023



While NeRF-based human representations have shown impressive novel view synthesis results, most methods still rely on a large number of images / views for training. In this work, we propose a novel animatable NeRF called ActorsNeRF. It is first pre-trained on diverse human subjects, and then adapted with few-shot monocular video frames for a new actor with unseen poses. Building on previous generalizable NeRFs with parameter sharing using a ConvNet encoder, ActorsNeRF further adopts two human priors to capture the large human appearance, shape, and pose variations. Specifically, in the encoded feature space, we will first align different human subjects in a category-level canonical space, and then align the same human from different frames in an instance-level canonical space for rendering. We quantitatively and qualitatively demonstrate that ActorsNeRF significantly outperforms the existing state-of-the-art on few-shot generalization to new people and poses on multiple datasets. Project Page: https://jitengmu.github.io/ActorsNeRF/
AgileGAN3D: Few-Shot 3D Portrait Stylization by Augmented Transfer Learning
Mar 24, 2023
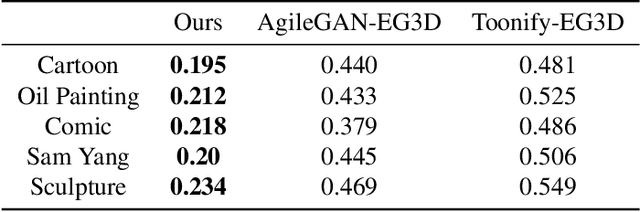
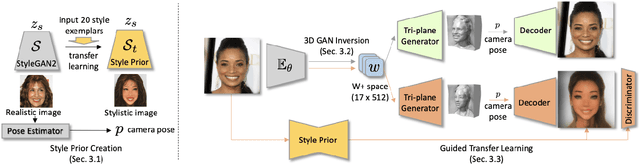

While substantial progresses have been made in automated 2D portrait stylization, admirable 3D portrait stylization from a single user photo remains to be an unresolved challenge. One primary obstacle here is the lack of high quality stylized 3D training data. In this paper, we propose a novel framework \emph{AgileGAN3D} that can produce 3D artistically appealing and personalized portraits with detailed geometry. New stylization can be obtained with just a few (around 20) unpaired 2D exemplars. We achieve this by first leveraging existing 2D stylization capabilities, \emph{style prior creation}, to produce a large amount of augmented 2D style exemplars. These augmented exemplars are generated with accurate camera pose labels, as well as paired real face images, which prove to be critical for the downstream 3D stylization task. Capitalizing on the recent advancement of 3D-aware GAN models, we perform \emph{guided transfer learning} on a pretrained 3D GAN generator to produce multi-view-consistent stylized renderings. In order to achieve 3D GAN inversion that can preserve subject's identity well, we incorporate \emph{multi-view consistency loss} in the training of our encoder. Our pipeline demonstrates strong capability in turning user photos into a diverse range of 3D artistic portraits. Both qualitative results and quantitative evaluations have been conducted to show the superior performance of our method. Code and pretrained models will be released for reproduction purpose.
Tag-based annotation creates better avatars
Feb 14, 2023


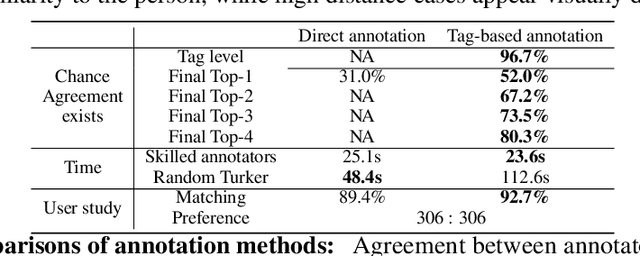
Avatar creation from human images allows users to customize their digital figures in different styles. Existing rendering systems like Bitmoji, MetaHuman, and Google Cartoonset provide expressive rendering systems that serve as excellent design tools for users. However, twenty-plus parameters, some including hundreds of options, must be tuned to achieve ideal results. Thus it is challenging for users to create the perfect avatar. A machine learning model could be trained to predict avatars from images, however the annotators who label pairwise training data have the same difficulty as users, causing high label noise. In addition, each new rendering system or version update requires thousands of new training pairs. In this paper, we propose a Tag-based annotation method for avatar creation. Compared to direct annotation of labels, the proposed method: produces higher annotator agreements, causes machine learning to generates more consistent predictions, and only requires a marginal cost to add new rendering systems.
AgileAvatar: Stylized 3D Avatar Creation via Cascaded Domain Bridging
Nov 15, 2022



Stylized 3D avatars have become increasingly prominent in our modern life. Creating these avatars manually usually involves laborious selection and adjustment of continuous and discrete parameters and is time-consuming for average users. Self-supervised approaches to automatically create 3D avatars from user selfies promise high quality with little annotation cost but fall short in application to stylized avatars due to a large style domain gap. We propose a novel self-supervised learning framework to create high-quality stylized 3D avatars with a mix of continuous and discrete parameters. Our cascaded domain bridging framework first leverages a modified portrait stylization approach to translate input selfies into stylized avatar renderings as the targets for desired 3D avatars. Next, we find the best parameters of the avatars to match the stylized avatar renderings through a differentiable imitator we train to mimic the avatar graphics engine. To ensure we can effectively optimize the discrete parameters, we adopt a cascaded relaxation-and-search pipeline. We use a human preference study to evaluate how well our method preserves user identity compared to previous work as well as manual creation. Our results achieve much higher preference scores than previous work and close to those of manual creation. We also provide an ablation study to justify the design choices in our pipeline.