 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUIVITON: Learned Universal Interoperable VIrtual Try-ON
Sep 05, 2025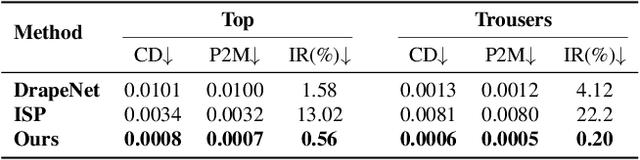
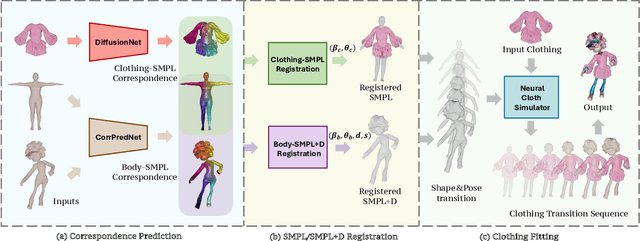
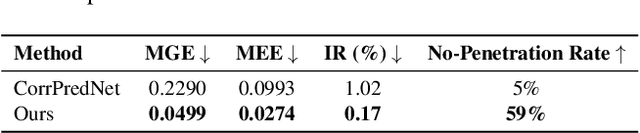
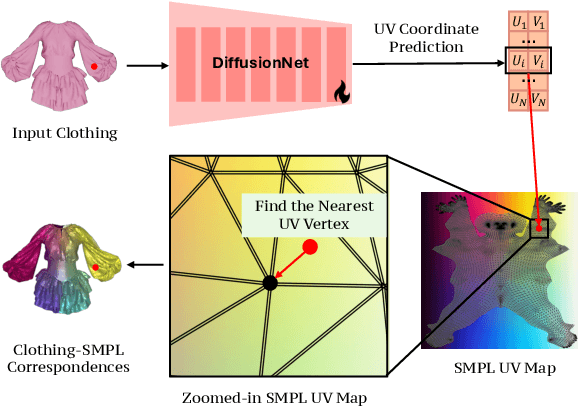
We present LUIVITON, an end-to-end system for fully automated virtual try-on, capable of draping complex, multi-layer clothing onto diverse and arbitrarily posed humanoid characters. To address the challenge of aligning complex garments with arbitrary and highly diverse body shapes, we use SMPL as a proxy representation and separate the clothing-to-body draping problem into two correspondence tasks: 1) clothing-to-SMPL and 2) body-to-SMPL correspondence, where each has its unique challenges. While we address the clothing-to-SMPL fitting problem using a geometric learning-based approach for partial-to-complete shape correspondence prediction, we introduce a diffusion model-based approach for body-to-SMPL correspondence using multi-view consistent appearance features and a pre-trained 2D foundation model. Our method can handle complex geometries, non-manifold meshes, and generalizes effectively to a wide range of humanoid characters -- including humans, robots, cartoon subjects, creatures, and aliens, while maintaining computational efficiency for practical adoption. In addition to offering a fully automatic fitting solution, LUIVITON supports fast customization of clothing size, allowing users to adjust clothing sizes and material properties after they have been draped. We show that our system can produce high-quality 3D clothing fittings without any human labor, even when 2D clothing sewing patterns are not available.
SOAP: Style-Omniscient Animatable Portraits
May 08, 2025
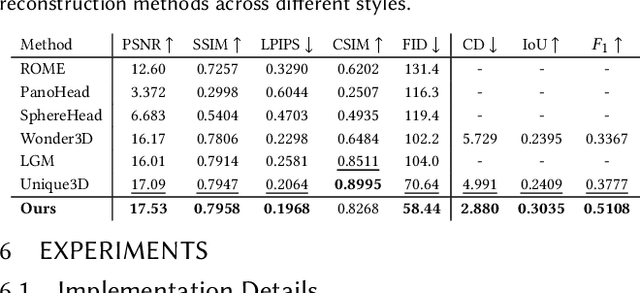
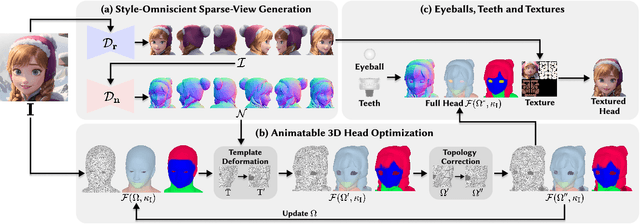
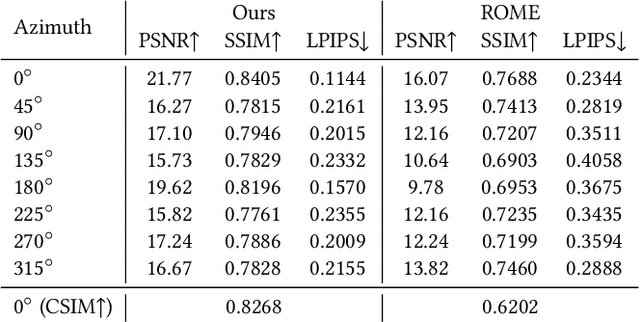
Creating animatable 3D avatars from a single image remains challenging due to style limitations (realistic, cartoon, anime) and difficulties in handling accessories or hairstyles. While 3D diffusion models advance single-view reconstruction for general objects, outputs often lack animation controls or suffer from artifacts because of the domain gap. We propose SOAP, a style-omniscient framework to generate rigged, topology-consistent avatars from any portrait. Our method leverages a multiview diffusion model trained on 24K 3D heads with multiple styles and an adaptive optimization pipeline to deform the FLAME mesh while maintaining topology and rigging via differentiable rendering. The resulting textured avatars support FACS-based animation, integrate with eyeballs and teeth, and preserve details like braided hair or accessories. Extensive experiments demonstrate the superiority of our method over state-of-the-art techniques for both single-view head modeling and diffusion-based generation of Image-to-3D. Our code and data are publicly available for research purposes at https://github.com/TingtingLiao/soap.
DiffPortrait360: Consistent Portrait Diffusion for 360 View Synthesis
Mar 19, 2025



Generating high-quality 360-degree views of human heads from single-view images is essential for enabling accessible immersive telepresence applications and scalable personalized content creation. While cutting-edge methods for full head generation are limited to modeling realistic human heads, the latest diffusion-based approaches for style-omniscient head synthesis can produce only frontal views and struggle with view consistency, preventing their conversion into true 3D models for rendering from arbitrary angles. We introduce a novel approach that generates fully consistent 360-degree head views, accommodating human, stylized, and anthropomorphic forms, including accessories like glasses and hats. Our method builds on the DiffPortrait3D framework, incorporating a custom ControlNet for back-of-head detail generation and a dual appearance module to ensure global front-back consistency. By training on continuous view sequences and integrating a back reference image, our approach achieves robust, locally continuous view synthesis. Our model can be used to produce high-quality neural radiance fields (NeRFs) for real-time, free-viewpoint rendering, outperforming state-of-the-art methods in object synthesis and 360-degree head generation for very challenging input portraits.
Towards Unified 3D Hair Reconstruction from Single-View Portraits
Sep 25, 2024



Single-view 3D hair reconstruction is challenging, due to the wide range of shape variations among diverse hairstyles. Current state-of-the-art methods are specialized in recovering un-braided 3D hairs and often take braided styles as their failure cases, because of the inherent difficulty to define priors for complex hairstyles, whether rule-based or data-based. We propose a novel strategy to enable single-view 3D reconstruction for a variety of hair types via a unified pipeline. To achieve this, we first collect a large-scale synthetic multi-view hair dataset SynMvHair with diverse 3D hair in both braided and un-braided styles, and learn two diffusion priors specialized on hair. Then we optimize 3D Gaussian-based hair from the priors with two specially designed modules, i.e. view-wise and pixel-wise Gaussian refinement. Our experiments demonstrate that reconstructing braided and un-braided 3D hair from single-view images via a unified approach is possible and our method achieves the state-of-the-art performance in recovering complex hairstyles. It is worth to mention that our method shows good generalization ability to real images, although it learns hair priors from synthetic data.
EMS: 3D Eyebrow Modeling from Single-view Images
Sep 22, 2023Eyebrows play a critical role in facial expression and appearance. Although the 3D digitization of faces is well explored, less attention has been drawn to 3D eyebrow modeling. In this work, we propose EMS, the first learning-based framework for single-view 3D eyebrow reconstruction. Following the methods of scalp hair reconstruction, we also represent the eyebrow as a set of fiber curves and convert the reconstruction to fibers growing problem. Three modules are then carefully designed: RootFinder firstly localizes the fiber root positions which indicates where to grow; OriPredictor predicts an orientation field in the 3D space to guide the growing of fibers; FiberEnder is designed to determine when to stop the growth of each fiber. Our OriPredictor is directly borrowing the method used in hair reconstruction. Considering the differences between hair and eyebrows, both RootFinder and FiberEnder are newly proposed. Specifically, to cope with the challenge that the root location is severely occluded, we formulate root localization as a density map estimation task. Given the predicted density map, a density-based clustering method is further used for finding the roots. For each fiber, the growth starts from the root point and moves step by step until the ending, where each step is defined as an oriented line with a constant length according to the predicted orientation field. To determine when to end, a pixel-aligned RNN architecture is designed to form a binary classifier, which outputs stop or not for each growing step. To support the training of all proposed networks, we build the first 3D synthetic eyebrow dataset that contains 400 high-quality eyebrow models manually created by artists. Extensive experiments have demonstrated the effectiveness of the proposed EMS pipeline on a variety of different eyebrow styles and lengths, ranging from short and sparse to long bushy eyebrows.
HairStep: Transfer Synthetic to Real Using Strand and Depth Maps for Single-View 3D Hair Modeling
Mar 05, 2023



In this work, we tackle the challenging problem of learning-based single-view 3D hair modeling. Due to the great difficulty of collecting paired real image and 3D hair data, using synthetic data to provide prior knowledge for real domain becomes a leading solution. This unfortunately introduces the challenge of domain gap. Due to the inherent difficulty of realistic hair rendering, existing methods typically use orientation maps instead of hair images as input to bridge the gap. We firmly think an intermediate representation is essential, but we argue that orientation map using the dominant filtering-based methods is sensitive to uncertain noise and far from a competent representation. Thus, we first raise this issue up and propose a novel intermediate representation, termed as HairStep, which consists of a strand map and a depth map. It is found that HairStep not only provides sufficient information for accurate 3D hair modeling, but also is feasible to be inferred from real images. Specifically, we collect a dataset of 1,250 portrait images with two types of annotations. A learning framework is further designed to transfer real images to the strand map and depth map. It is noted that, an extra bonus of our new dataset is the first quantitative metric for 3D hair modeling. Our experiments show that HairStep narrows the domain gap between synthetic and real and achieves state-of-the-art performance on single-view 3D hair reconstruction.
Towards High-Fidelity Single-view Holistic Reconstruction of Indoor Scenes
Jul 18, 2022

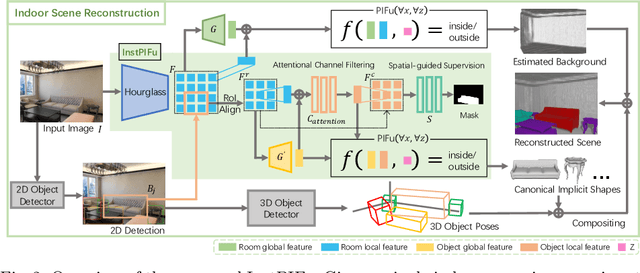
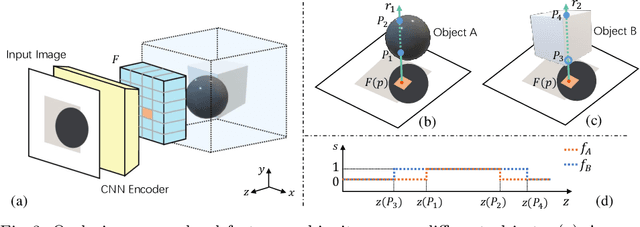
We present a new framework to reconstruct holistic 3D indoor scenes including both room background and indoor objects from single-view images. Existing methods can only produce 3D shapes of indoor objects with limited geometry quality because of the heavy occlusion of indoor scenes. To solve this, we propose an instance-aligned implicit function (InstPIFu) for detailed object reconstruction. Combining with instance-aligned attention module, our method is empowered to decouple mixed local features toward the occluded instances. Additionally, unlike previous methods that simply represents the room background as a 3D bounding box, depth map or a set of planes, we recover the fine geometry of the background via implicit representation. Extensive experiments on the e SUN RGB-D, Pix3D, 3D-FUTURE, and 3D-FRONT datasets demonstrate that our method outperforms existing approaches in both background and foreground object reconstruction. Our code and model will be made publicly available.
Total3DUnderstanding: Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes from a Single Image
Feb 27, 2020
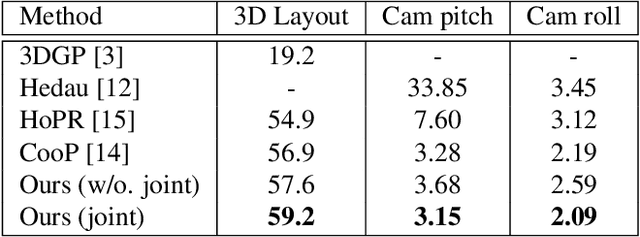
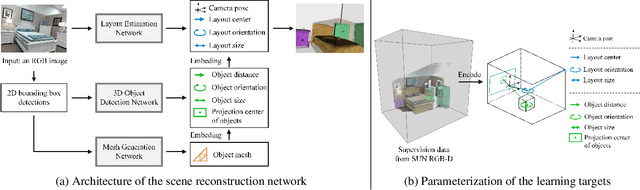

Semantic reconstruction of indoor scenes refers to both scene understanding and object reconstruction. Existing works either address one part of this problem or focus on independent objects. In this paper, we bridge the gap between understanding and reconstruction, and propose an end-to-end solution to jointly reconstruct room layout, object bounding boxes and meshes from a single image. Instead of separately resolving scene understanding and object reconstruction, our method builds upon a holistic scene context and proposes a coarse-to-fine hierarchy with three components: 1. room layout with camera pose; 2. 3D object bounding boxes; 3. object meshes. We argue that understanding the context of each component can assist the task of parsing the others, which enables joint understanding and reconstruction. The experiments on the SUN RGB-D and Pix3D datasets demonstrate that our method consistently outperforms existing methods in indoor layout estimation, 3D object detection and mesh reconstruction.