 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember to be Curious: Episodic Context and Persistent Worlds for 3D Exploration
May 21, 2026Exploration is a prerequisite for learning useful behaviors in sparse-reward, long-horizon tasks, particularly within 3D environments. Curiosity-driven reinforcement learning addresses this via intrinsic rewards derived from the mismatch between the agent's predictive model of the world and reality. However, translating this intrinsic motivation to complex, photorealistic environments remains difficult, as agents can become trapped in local loops and receive fresh rewards for revisiting forgotten states. In this work, we demonstrate that this failure stems from a lack of spatial persistence and episodic context. We show that effective curiosity requires a model of the world that is persistent and continuously updated, paired with an agent that maintains an episodic trajectory history to navigate toward novel regions. We achieve this using an online 3D reconstruction as a persistent model of the world, while the agent policy is parameterized as a sequence model over RGB observations to maintain episodic context. This design enables effective exploration during training while allowing the agent to navigate using solely RGB frames at deployment. Trained purely via curiosity on HM3D, our agent outperforms RL-based active mapping baselines and generalizes zero-shot to Gibson and AI-generated worlds. Our end-to-end policy enables efficient adaptation to downstream tasks, such as apple picking and image-goal navigation, outperforming from-scratch baselines. Please see video results at https://recuriosity.github.io/.
Omni-Scan: Creating Visually-Accurate Digital Twin Object Models Using a Bimanual Robot with Handover and Gaussian Splat Merging
Aug 01, 20253D Gaussian Splats (3DGSs) are 3D object models derived from multi-view images. Such "digital twins" are useful for simulations, virtual reality, marketing, robot policy fine-tuning, and part inspection. 3D object scanning usually requires multi-camera arrays, precise laser scanners, or robot wrist-mounted cameras, which have restricted workspaces. We propose Omni-Scan, a pipeline for producing high-quality 3D Gaussian Splat models using a bi-manual robot that grasps an object with one gripper and rotates the object with respect to a stationary camera. The object is then re-grasped by a second gripper to expose surfaces that were occluded by the first gripper. We present the Omni-Scan robot pipeline using DepthAny-thing, Segment Anything, as well as RAFT optical flow models to identify and isolate objects held by a robot gripper while removing the gripper and the background. We then modify the 3DGS training pipeline to support concatenated datasets with gripper occlusion, producing an omni-directional (360 degree view) model of the object. We apply Omni-Scan to part defect inspection, finding that it can identify visual or geometric defects in 12 different industrial and household objects with an average accuracy of 83%. Interactive videos of Omni-Scan 3DGS models can be found at https://berkeleyautomation.github.io/omni-scan/
Viser: Imperative, Web-based 3D Visualization in Python
Jul 30, 2025We present Viser, a 3D visualization library for computer vision and robotics. Viser aims to bring easy and extensible 3D visualization to Python: we provide a comprehensive set of 3D scene and 2D GUI primitives, which can be used independently with minimal setup or composed to build specialized interfaces. This technical report describes Viser's features, interface, and implementation. Key design choices include an imperative-style API and a web-based viewer, which improve compatibility with modern programming patterns and workflows.
Eye, Robot: Learning to Look to Act with a BC-RL Perception-Action Loop
Jun 12, 2025
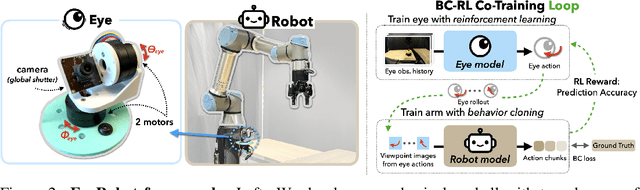


Humans do not passively observe the visual world -- we actively look in order to act. Motivated by this principle, we introduce EyeRobot, a robotic system with gaze behavior that emerges from the need to complete real-world tasks. We develop a mechanical eyeball that can freely rotate to observe its surroundings and train a gaze policy to control it using reinforcement learning. We accomplish this by first collecting teleoperated demonstrations paired with a 360 camera. This data is imported into a simulation environment that supports rendering arbitrary eyeball viewpoints, allowing episode rollouts of eye gaze on top of robot demonstrations. We then introduce a BC-RL loop to train the hand and eye jointly: the hand (BC) agent is trained from rendered eye observations, and the eye (RL) agent is rewarded when the hand produces correct action predictions. In this way, hand-eye coordination emerges as the eye looks towards regions which allow the hand to complete the task. EyeRobot implements a foveal-inspired policy architecture allowing high resolution with a small compute budget, which we find also leads to the emergence of more stable fixation as well as improved ability to track objects and ignore distractors. We evaluate EyeRobot on five panoramic workspace manipulation tasks requiring manipulation in an arc surrounding the robot arm. Our experiments suggest EyeRobot exhibits hand-eye coordination behaviors which effectively facilitate manipulation over large workspaces with a single camera. See project site for videos: https://www.eyerobot.net/
GrowSplat: Constructing Temporal Digital Twins of Plants with Gaussian Splats
May 16, 2025
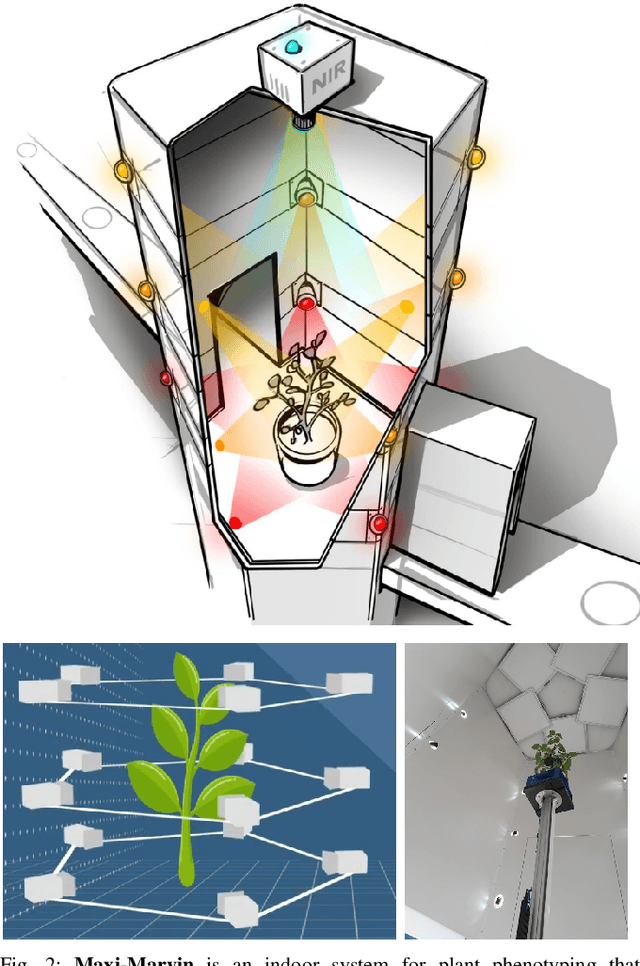


Accurate temporal reconstructions of plant growth are essential for plant phenotyping and breeding, yet remain challenging due to complex geometries, occlusions, and non-rigid deformations of plants. We present a novel framework for building temporal digital twins of plants by combining 3D Gaussian Splatting with a robust sample alignment pipeline. Our method begins by reconstructing Gaussian Splats from multi-view camera data, then leverages a two-stage registration approach: coarse alignment through feature-based matching and Fast Global Registration, followed by fine alignment with Iterative Closest Point. This pipeline yields a consistent 4D model of plant development in discrete time steps. We evaluate the approach on data from the Netherlands Plant Eco-phenotyping Center, demonstrating detailed temporal reconstructions of Sequoia and Quinoa species. Videos and Images can be seen at https://berkeleyautomation.github.io/GrowSplat/
Predict-Optimize-Distill: A Self-Improving Cycle for 4D Object Understanding
Apr 24, 2025Humans can resort to long-form inspection to build intuition on predicting the 3D configurations of unseen objects. The more we observe the object motion, the better we get at predicting its 3D state immediately. Existing systems either optimize underlying representations from multi-view observations or train a feed-forward predictor from supervised datasets. We introduce Predict-Optimize-Distill (POD), a self-improving framework that interleaves prediction and optimization in a mutually reinforcing cycle to achieve better 4D object understanding with increasing observation time. Given a multi-view object scan and a long-form monocular video of human-object interaction, POD iteratively trains a neural network to predict local part poses from RGB frames, uses this predictor to initialize a global optimization which refines output poses through inverse rendering, then finally distills the results of optimization back into the model by generating synthetic self-labeled training data from novel viewpoints. Each iteration improves both the predictive model and the optimized motion trajectory, creating a virtuous cycle that bootstraps its own training data to learn about the pose configurations of an object. We also introduce a quasi-multiview mining strategy for reducing depth ambiguity by leveraging long video. We evaluate POD on 14 real-world and 5 synthetic objects with various joint types, including revolute and prismatic joints as well as multi-body configurations where parts detach or reattach independently. POD demonstrates significant improvement over a pure optimization baseline which gets stuck in local minima, particularly for longer videos. We also find that POD's performance improves with both video length and successive iterations of the self-improving cycle, highlighting its ability to scale performance with additional observations and looped refinement.
Persistent Object Gaussian Splat (POGS) for Tracking Human and Robot Manipulation of Irregularly Shaped Objects
Mar 07, 2025
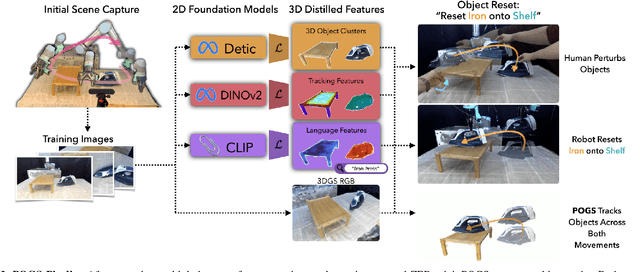


Tracking and manipulating irregularly-shaped, previously unseen objects in dynamic environments is important for robotic applications in manufacturing, assembly, and logistics. Recently introduced Gaussian Splats efficiently model object geometry, but lack persistent state estimation for task-oriented manipulation. We present Persistent Object Gaussian Splat (POGS), a system that embeds semantics, self-supervised visual features, and object grouping features into a compact representation that can be continuously updated to estimate the pose of scanned objects. POGS updates object states without requiring expensive rescanning or prior CAD models of objects. After an initial multi-view scene capture and training phase, POGS uses a single stereo camera to integrate depth estimates along with self-supervised vision encoder features for object pose estimation. POGS supports grasping, reorientation, and natural language-driven manipulation by refining object pose estimates, facilitating sequential object reset operations with human-induced object perturbations and tool servoing, where robots recover tool pose despite tool perturbations of up to 30{\deg}. POGS achieves up to 12 consecutive successful object resets and recovers from 80% of in-grasp tool perturbations.
Robot See Robot Do: Imitating Articulated Object Manipulation with Monocular 4D Reconstruction
Sep 26, 2024



Humans can learn to manipulate new objects by simply watching others; providing robots with the ability to learn from such demonstrations would enable a natural interface specifying new behaviors. This work develops Robot See Robot Do (RSRD), a method for imitating articulated object manipulation from a single monocular RGB human demonstration given a single static multi-view object scan. We first propose 4D Differentiable Part Models (4D-DPM), a method for recovering 3D part motion from a monocular video with differentiable rendering. This analysis-by-synthesis approach uses part-centric feature fields in an iterative optimization which enables the use of geometric regularizers to recover 3D motions from only a single video. Given this 4D reconstruction, the robot replicates object trajectories by planning bimanual arm motions that induce the demonstrated object part motion. By representing demonstrations as part-centric trajectories, RSRD focuses on replicating the demonstration's intended behavior while considering the robot's own morphological limits, rather than attempting to reproduce the hand's motion. We evaluate 4D-DPM's 3D tracking accuracy on ground truth annotated 3D part trajectories and RSRD's physical execution performance on 9 objects across 10 trials each on a bimanual YuMi robot. Each phase of RSRD achieves an average of 87% success rate, for a total end-to-end success rate of 60% across 90 trials. Notably, this is accomplished using only feature fields distilled from large pretrained vision models -- without any task-specific training, fine-tuning, dataset collection, or annotation. Project page: https://robot-see-robot-do.github.io
Language-Embedded Gaussian Splats (LEGS): Incrementally Building Room-Scale Representations with a Mobile Robot
Sep 26, 2024
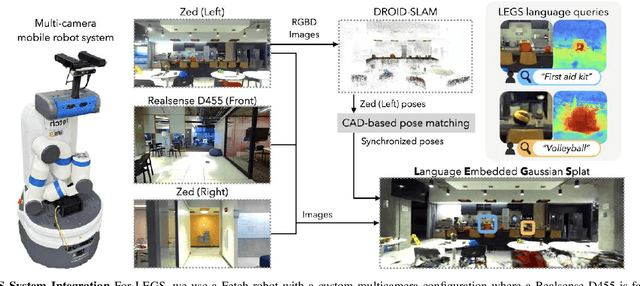


Building semantic 3D maps is valuable for searching for objects of interest in offices, warehouses, stores, and homes. We present a mapping system that incrementally builds a Language-Embedded Gaussian Splat (LEGS): a detailed 3D scene representation that encodes both appearance and semantics in a unified representation. LEGS is trained online as a robot traverses its environment to enable localization of open-vocabulary object queries. We evaluate LEGS on 4 room-scale scenes where we query for objects in the scene to assess how LEGS can capture semantic meaning. We compare LEGS to LERF and find that while both systems have comparable object query success rates, LEGS trains over 3.5x faster than LERF. Results suggest that a multi-camera setup and incremental bundle adjustment can boost visual reconstruction quality in constrained robot trajectories, and suggest LEGS can localize open-vocabulary and long-tail object queries with up to 66% accuracy.
Blox-Net: Generative Design-for-Robot-Assembly Using VLM Supervision, Physics Simulation, and a Robot with Reset
Sep 25, 2024
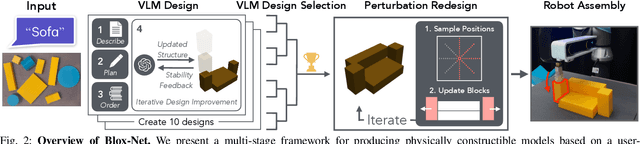


Generative AI systems have shown impressive capabilities in creating text, code, and images. Inspired by the rich history of research in industrial ''Design for Assembly'', we introduce a novel problem: Generative Design-for-Robot-Assembly (GDfRA). The task is to generate an assembly based on a natural language prompt (e.g., ''giraffe'') and an image of available physical components, such as 3D-printed blocks. The output is an assembly, a spatial arrangement of these components, and instructions for a robot to build this assembly. The output must 1) resemble the requested object and 2) be reliably assembled by a 6 DoF robot arm with a suction gripper. We then present Blox-Net, a GDfRA system that combines generative vision language models with well-established methods in computer vision, simulation, perturbation analysis, motion planning, and physical robot experimentation to solve a class of GDfRA problems with minimal human supervision. Blox-Net achieved a Top-1 accuracy of 63.5% in the ''recognizability'' of its designed assemblies (eg, resembling giraffe as judged by a VLM). These designs, after automated perturbation redesign, were reliably assembled by a robot, achieving near-perfect success across 10 consecutive assembly iterations with human intervention only during reset prior to assembly. Surprisingly, this entire design process from textual word (''giraffe'') to reliable physical assembly is performed with zero human intervention.