 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifelong LERF: Local 3D Semantic Inventory Monitoring Using FogROS2
Mar 15, 2024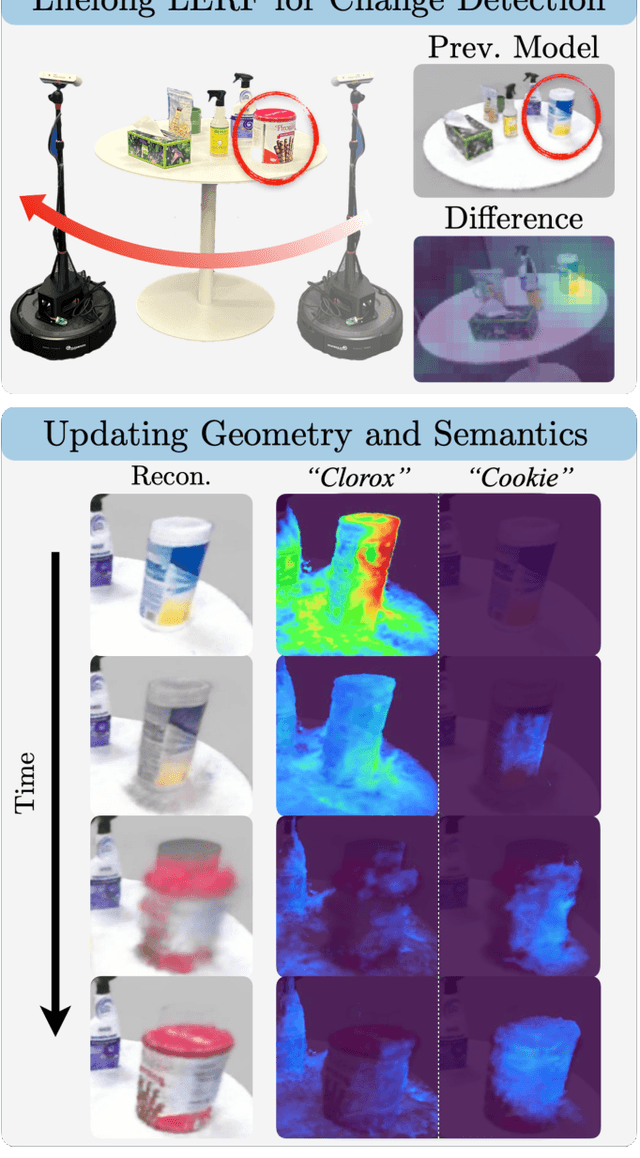
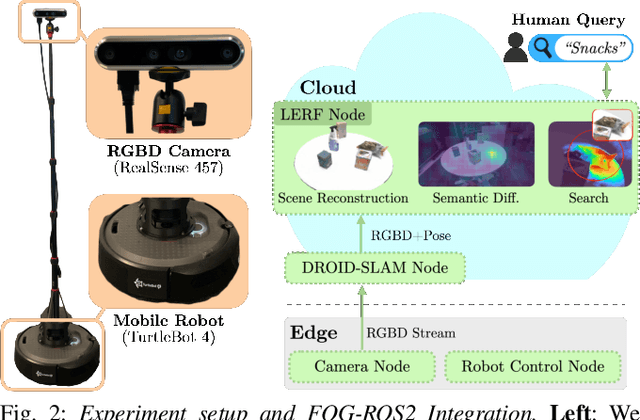
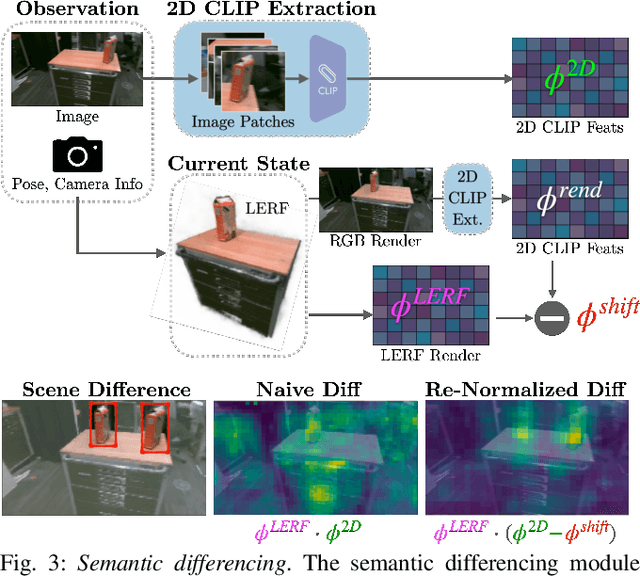

Inventory monitoring in homes, factories, and retail stores relies on maintaining data despite objects being swapped, added, removed, or moved. We introduce Lifelong LERF, a method that allows a mobile robot with minimal compute to jointly optimize a dense language and geometric representation of its surroundings. Lifelong LERF maintains this representation over time by detecting semantic changes and selectively updating these regions of the environment, avoiding the need to exhaustively remap. Human users can query inventory by providing natural language queries and receiving a 3D heatmap of potential object locations. To manage the computational load, we use Fog-ROS2, a cloud robotics platform, to offload resource-intensive tasks. Lifelong LERF obtains poses from a monocular RGBD SLAM backend, and uses these poses to progressively optimize a Language Embedded Radiance Field (LERF) for semantic monitoring. Experiments with 3-5 objects arranged on a tabletop and a Turtlebot with a RealSense camera suggest that Lifelong LERF can persistently adapt to changes in objects with up to 91% accuracy.
The Teenager's Problem: Efficient Garment Decluttering With Grasp Optimization
Oct 25, 2023



This paper addresses the ''Teenager's Problem'': efficiently removing scattered garments from a planar surface. As grasping and transporting individual garments is highly inefficient, we propose analytical policies to select grasp locations for multiple garments using an overhead camera. Two classes of methods are considered: depth-based, which use overhead depth data to find efficient grasps, and segment-based, which use segmentation on the RGB overhead image (without requiring any depth data); grasp efficiency is measured by Objects per Transport, which denotes the average number of objects removed per trip to the laundry basket. Experiments suggest that both depth- and segment-based methods easily reduce Objects per Transport (OpT) by $20\%$; furthermore, these approaches complement each other, with combined hybrid methods yielding improvements of $34\%$. Finally, a method employing consolidation (with segmentation) is considered, which manipulates the garments on the work surface to increase OpT; this yields an improvement of $67\%$ over the baseline, though at a cost of additional physical actions.
The Busboy Problem: Efficient Tableware Decluttering Using Consolidation and Multi-Object Grasps
Jul 08, 2023



We present the "Busboy Problem": automating an efficient decluttering of cups, bowls, and silverware from a planar surface. As grasping and transporting individual items is highly inefficient, we propose policies to generate grasps for multiple items. We introduce the metric of Objects per Trip (OpT) carried by the robot to the collection bin to analyze the improvement seen as a result of our policies. In physical experiments with singulated items, we find that consolidation and multi-object grasps resulted in an 1.8x improvement in OpT, compared to methods without multi-object grasps. See https://sites.google.com/berkeley.edu/busboyproblem for code and supplemental materials.
Bagging by Learning to Singulate Layers Using Interactive Perception
Mar 29, 2023Many fabric handling and 2D deformable material tasks in homes and industry require singulating layers of material such as opening a bag or arranging garments for sewing. In contrast to methods requiring specialized sensing or end effectors, we use only visual observations with ordinary parallel jaw grippers. We propose SLIP: Singulating Layers using Interactive Perception, and apply SLIP to the task of autonomous bagging. We develop SLIP-Bagging, a bagging algorithm that manipulates a plastic or fabric bag from an unstructured state, and uses SLIP to grasp the top layer of the bag to open it for object insertion. In physical experiments, a YuMi robot achieves a success rate of 67% to 81% across bags of a variety of materials, shapes, and sizes, significantly improving in success rate and generality over prior work. Experiments also suggest that SLIP can be applied to tasks such as singulating layers of folded cloth and garments. Supplementary material is available at https://sites.google.com/view/slip-bagging/.