 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifelong LERF: Local 3D Semantic Inventory Monitoring Using FogROS2
Mar 15, 2024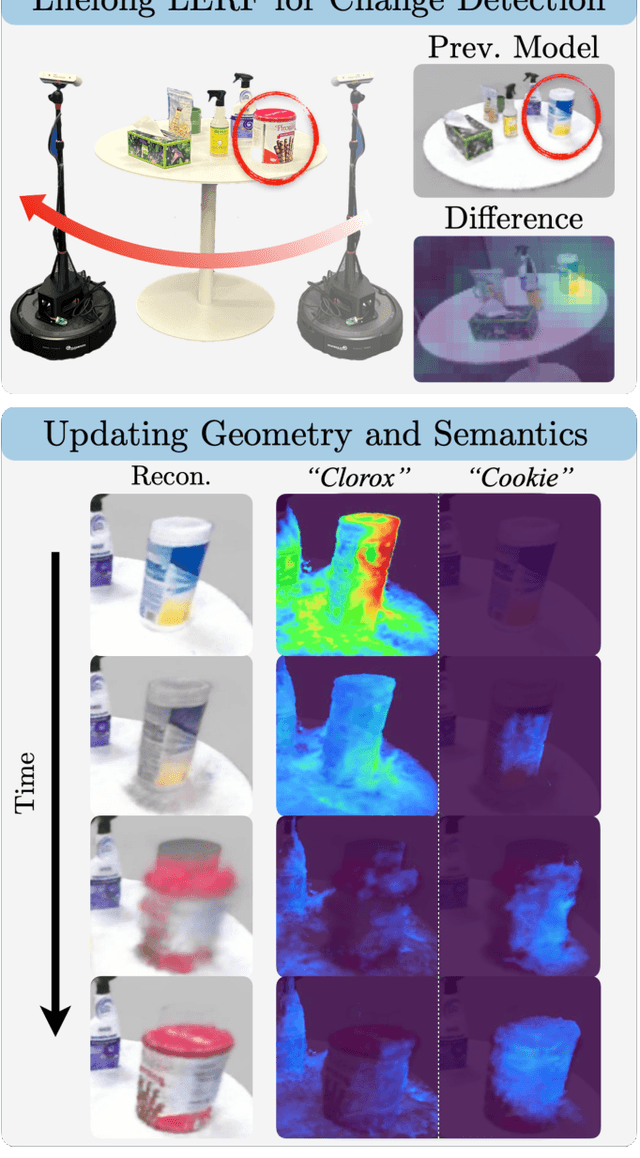
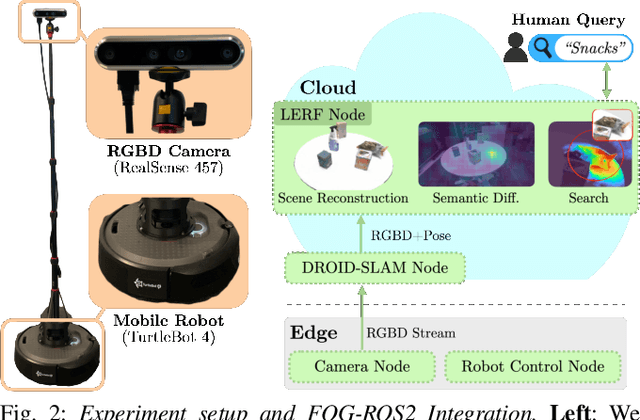
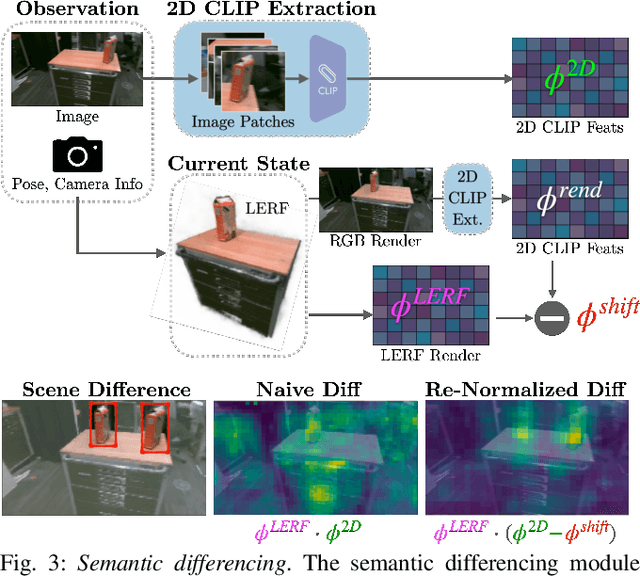

Inventory monitoring in homes, factories, and retail stores relies on maintaining data despite objects being swapped, added, removed, or moved. We introduce Lifelong LERF, a method that allows a mobile robot with minimal compute to jointly optimize a dense language and geometric representation of its surroundings. Lifelong LERF maintains this representation over time by detecting semantic changes and selectively updating these regions of the environment, avoiding the need to exhaustively remap. Human users can query inventory by providing natural language queries and receiving a 3D heatmap of potential object locations. To manage the computational load, we use Fog-ROS2, a cloud robotics platform, to offload resource-intensive tasks. Lifelong LERF obtains poses from a monocular RGBD SLAM backend, and uses these poses to progressively optimize a Language Embedded Radiance Field (LERF) for semantic monitoring. Experiments with 3-5 objects arranged on a tabletop and a Turtlebot with a RealSense camera suggest that Lifelong LERF can persistently adapt to changes in objects with up to 91% accuracy.
Pick-Place With Uncertain Object Instance Segmentation and Shape Completion
Oct 15, 2020


In this paper we consider joint perception and control of a pick-place system. It is important to consider perception and control jointly as some actions are more likely to succeed than others given non-uniform, perceptual uncertainty. Our approach is to combine 3D object instance segmentation and shape completion with classical regrasp planning. We use the perceptual modules to estimate their own uncertainty and then incorporate this uncertainty as a regrasp planning cost. We compare 7 different regrasp planning cost functions, 4 of which explicitly model probability of plan execution success. Results show uncertainty-aware costs improve performance for complex tasks, e.g., for a bin packing task, object placement success is 6.2% higher in simulation and 4.1% higher in the real world with an uncertainty-aware cost versus the commonly used minimum-number-of-grasps cost.
Learning Manipulation Skills Via Hierarchical Spatial Attention
Apr 19, 2019

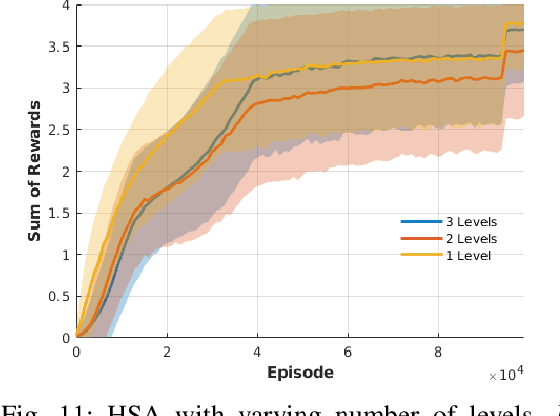
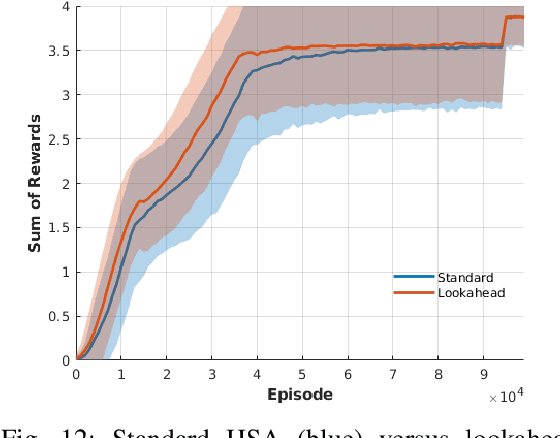
Learning generalizable skills in robotic manipulation has long been challenging due to real-world sized observation and action spaces. One method for addressing this problem is attention focus -- the robot learns where to attend its sensors and irrelevant details are ignored. However, these methods have largely not caught on due to the difficulty of learning a good attention policy and the added partial observability induced by a narrowed window of focus. This article addresses the first issue by constraining gazes to a spatial hierarchy. For the second issue, we identify a case where the partial observability induced by attention does not prevent Q-learning from finding an optimal policy. We conclude with real-robot experiments on challenging pick-place tasks demonstrating the applicability of the approach.
Learning 6-DoF Grasping and Pick-Place Using Attention Focus
Sep 27, 2018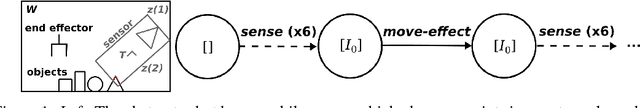



We address a class of manipulation problems where the robot perceives the scene with a depth sensor and can move its end effector in a space with six degrees of freedom -- 3D position and orientation. Our approach is to formulate the problem as a Markov decision process (MDP) with abstract yet generally applicable state and action representations. Finding a good solution to the MDP requires adding constraints on the allowed actions. We develop a specific set of constraints called hierarchical $\text{SE}(3)$ sampling (HSE3S) which causes the robot to learn a sequence of gazes to focus attention on the task-relevant parts of the scene. We demonstrate the effectiveness of our approach on three challenging pick-place tasks (with novel objects in clutter and nontrivial places) both in simulation and on a real robot, even though all training is done in simulation.
Deictic Image Maps: An Abstraction For Learning Pose Invariant Manipulation Policies
Sep 17, 2018


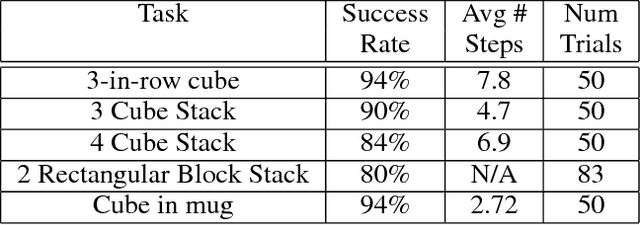
In applications of deep reinforcement learning to robotics, it is often the case that we want to learn pose invariant policies: policies that are invariant to changes in the position and orientation of objects in the world. For example, consider a peg-in-hole insertion task. If the agent learns to insert a peg into one hole, we would like that policy to generalize to holes presented in different poses. Unfortunately, this is a challenge using conventional methods. This paper proposes a novel state and action abstraction that is invariant to pose shifts called \textit{deictic image maps} that can be used with deep reinforcement learning. We provide broad conditions under which optimal abstract policies are optimal for the underlying system. Finally, we show that the method can help solve challenging robotic manipulation problems.
Pick and Place Without Geometric Object Models
Feb 22, 2018
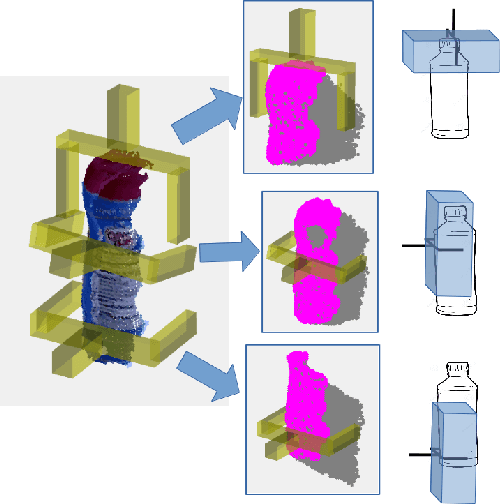
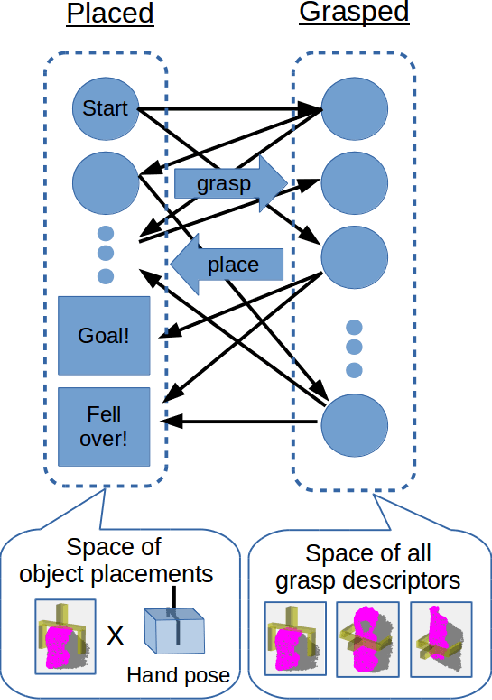
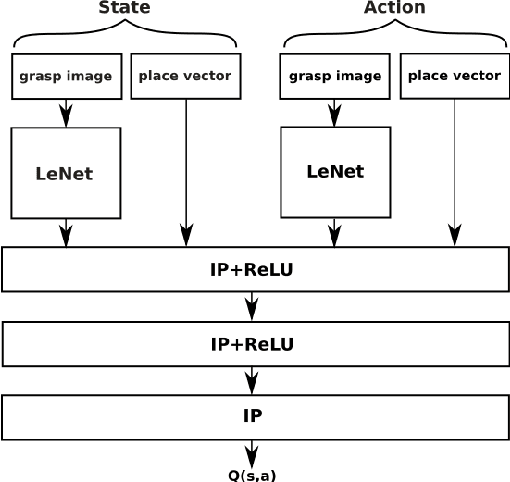
We propose a novel formulation of robotic pick and place as a deep reinforcement learning (RL) problem. Whereas most deep RL approaches to robotic manipulation frame the problem in terms of low level states and actions, we propose a more abstract formulation. In this formulation, actions are target reach poses for the hand and states are a history of such reaches. We show this approach can solve a challenging class of pick-place and regrasping problems where the exact geometry of the objects to be handled is unknown. The only information our method requires is: 1) the sensor perception available to the robot at test time; 2) prior knowledge of the general class of objects for which the system was trained. We evaluate our method using objects belonging to two different categories, mugs and bottles, both in simulation and on real hardware. Results show a major improvement relative to a shape primitives baseline.
Viewpoint Selection for Grasp Detection
Jul 31, 2017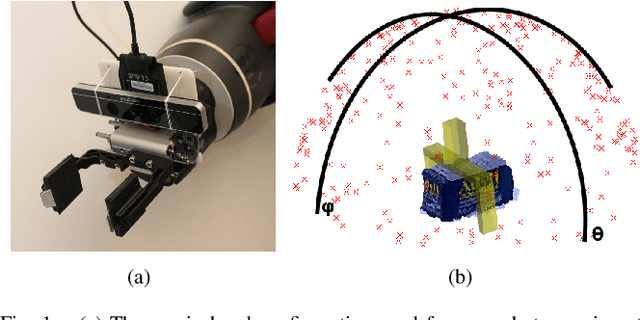



In grasp detection, the robot estimates the position and orientation of potential grasp configurations directly from sensor data. This paper explores the relationship between viewpoint and grasp detection performance. Specifically, we consider the scenario where the approximate position and orientation of a desired grasp is known in advance and we want to select a viewpoint that will enable a grasp detection algorithm to localize it more precisely and with higher confidence. Our main findings are that the right viewpoint can dramatically increase the number of detected grasps and the classification accuracy of the top-n detections. We use this insight to create a viewpoint selection algorithm and compare it against a random viewpoint selection strategy and a strategy that views the desired grasp head-on. We find that the head-on strategy and our proposed viewpoint selection strategy can improve grasp success rates on a real robot by 8% and 4%, respectively. Moreover, we find that the combination of the two methods can improve grasp success rates by as much as 12%.
Grasp Pose Detection in Point Clouds
Jun 29, 2017

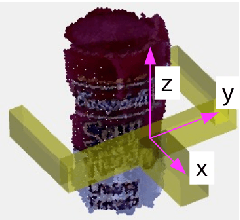

Recently, a number of grasp detection methods have been proposed that can be used to localize robotic grasp configurations directly from sensor data without estimating object pose. The underlying idea is to treat grasp perception analogously to object detection in computer vision. These methods take as input a noisy and partially occluded RGBD image or point cloud and produce as output pose estimates of viable grasps, without assuming a known CAD model of the object. Although these methods generalize grasp knowledge to new objects well, they have not yet been demonstrated to be reliable enough for wide use. Many grasp detection methods achieve grasp success rates (grasp successes as a fraction of the total number of grasp attempts) between 75% and 95% for novel objects presented in isolation or in light clutter. Not only are these success rates too low for practical grasping applications, but the light clutter scenarios that are evaluated often do not reflect the realities of real world grasping. This paper proposes a number of innovations that together result in a significant improvement in grasp detection performance. The specific improvement in performance due to each of our contributions is quantitatively measured either in simulation or on robotic hardware. Ultimately, we report a series of robotic experiments that average a 93% end-to-end grasp success rate for novel objects presented in dense clutter.
High precision grasp pose detection in dense clutter
Jun 22, 2017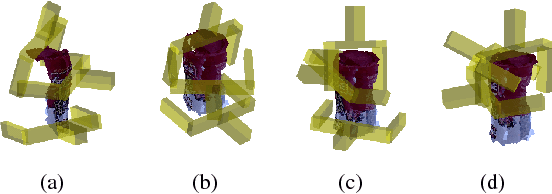
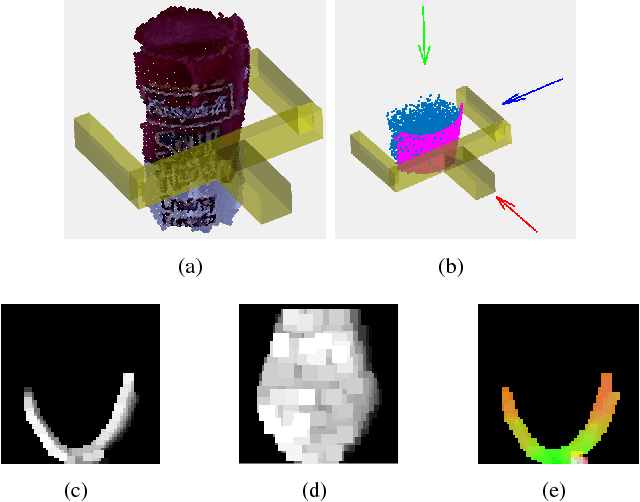
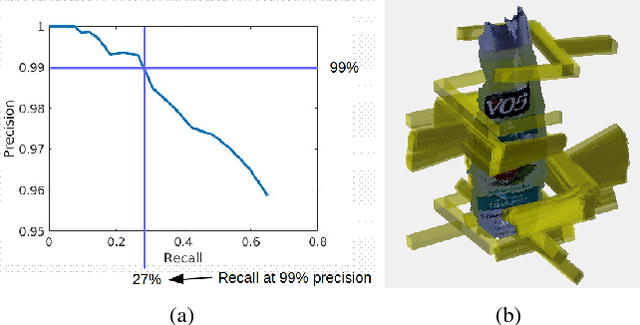
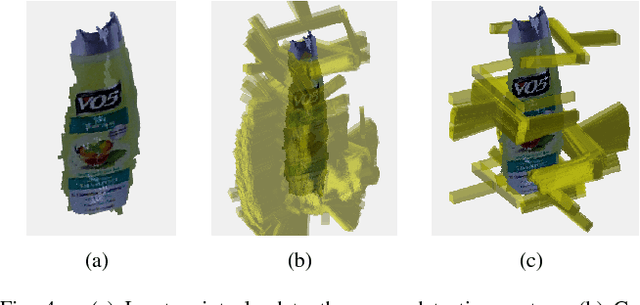
This paper considers the problem of grasp pose detection in point clouds. We follow a general algorithmic structure that first generates a large set of 6-DOF grasp candidates and then classifies each of them as a good or a bad grasp. Our focus in this paper is on improving the second step by using depth sensor scans from large online datasets to train a convolutional neural network. We propose two new representations of grasp candidates, and we quantify the effect of using prior knowledge of two forms: instance or category knowledge of the object to be grasped, and pretraining the network on simulated depth data obtained from idealized CAD models. Our analysis shows that a more informative grasp candidate representation as well as pretraining and prior knowledge significantly improve grasp detection. We evaluate our approach on a Baxter Research Robot and demonstrate an average grasp success rate of 93% in dense clutter. This is a 20% improvement compared to our prior work.
Open World Assistive Grasping Using Laser Selection
Jun 21, 2017


Many people with motor disabilities are unable to complete activities of daily living (ADLs) without assistance. This paper describes a complete robotic system developed to provide mobile grasping assistance for ADLs. The system is comprised of a robot arm from a Rethink Robotics Baxter robot mounted to an assistive mobility device, a control system for that arm, and a user interface with a variety of access methods for selecting desired objects. The system uses grasp detection to allow previously unseen objects to be picked up by the system. The grasp detection algorithms also allow for objects to be grasped in cluttered environments. We evaluate our system in a number of experiments on a large variety of objects. Overall, we achieve an object selection success rate of 88% and a grasp detection success rate of 90% in a non-mobile scenario, and success rates of 89% and 72% in a mobile scenario.