 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetric Models for Visual Force Policy Learning
Aug 28, 2023



While it is generally acknowledged that force feedback is beneficial to robotic control, applications of policy learning to robotic manipulation typically only leverage visual feedback. Recently, symmetric neural models have been used to significantly improve the sample efficiency and performance of policy learning across a variety of robotic manipulation domains. This paper explores an application of symmetric policy learning to visual-force problems. We present Symmetric Visual Force Learning (SVFL), a novel method for robotic control which leverages visual and force feedback. We demonstrate that SVFL can significantly outperform state of the art baselines for visual force learning and report several interesting empirical findings related to the utility of learning force feedback control policies in both general manipulation tasks and scenarios with low visual acuity.
Visual Foresight With a Local Dynamics Model
Jun 29, 2022



Model-free policy learning has been shown to be capable of learning manipulation policies which can solve long-time horizon tasks using single-step manipulation primitives. However, training these policies is a time-consuming process requiring large amounts of data. We propose the Local Dynamics Model (LDM) which efficiently learns the state-transition function for these manipulation primitives. By combining the LDM with model-free policy learning, we can learn policies which can solve complex manipulation tasks using one-step lookahead planning. We show that the LDM is both more sample-efficient and outperforms other model architectures. When combined with planning, we can outperform other model-based and model-free policies on several challenging manipulation tasks in simulation.
BulletArm: An Open-Source Robotic Manipulation Benchmark and Learning Framework
May 28, 2022

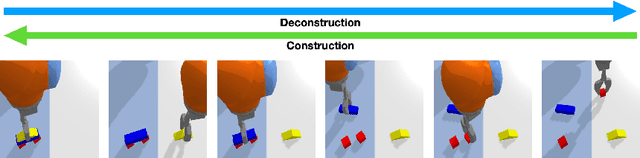

We present BulletArm, a novel benchmark and learning-environment for robotic manipulation. BulletArm is designed around two key principles: reproducibility and extensibility. We aim to encourage more direct comparisons between robotic learning methods by providing a set of standardized benchmark tasks in simulation alongside a collection of baseline algorithms. The framework consists of 31 different manipulation tasks of varying difficulty, ranging from simple reaching and picking tasks to more realistic tasks such as bin packing and pallet stacking. In addition to the provided tasks, BulletArm has been built to facilitate easy expansion and provides a suite of tools to assist users when adding new tasks to the framework. Moreover, we introduce a set of five benchmarks and evaluate them using a series of state-of-the-art baseline algorithms. By including these algorithms as part of our framework, we hope to encourage users to benchmark their work on any new tasks against these baselines.
Policy learning in SE(3) action spaces
Oct 06, 2020
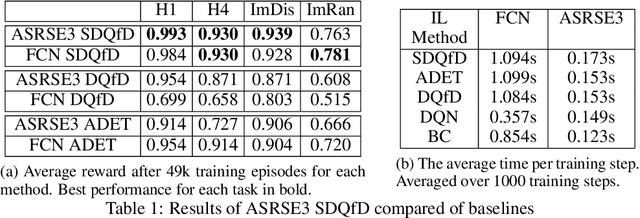

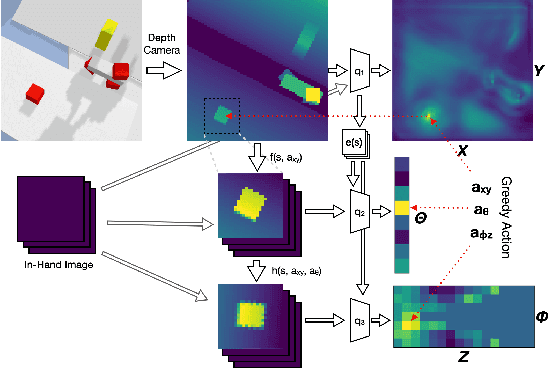
In the spatial action representation, the action space spans the space of target poses for robot motion commands, i.e. SE(2) or SE(3). This approach has been used to solve challenging robotic manipulation problems and shows promise. However, the method is often limited to a three dimensional action space and short horizon tasks. This paper proposes ASRSE3, a new method for handling higher dimensional spatial action spaces that transforms an original MDP with high dimensional action space into a new MDP with reduced action space and augmented state space. We also propose SDQfD, a variation of DQfD designed for large action spaces. ASRSE3 and SDQfD are evaluated in the context of a set of challenging block construction tasks. We show that both methods outperform standard baselines and can be used in practice on real robotics systems.
A Scooter-Mounted Robot Arm to Assist with Activities of Daily Life
Sep 25, 2018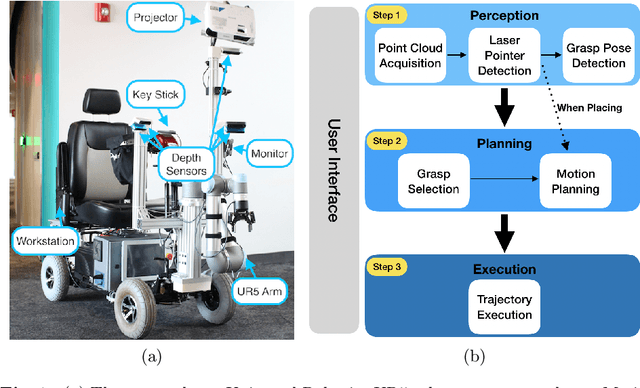


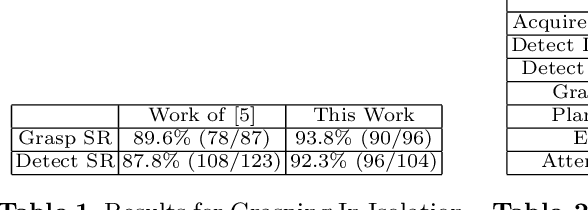
Many people with motor disabilities struggle with activities of daily life (ADLs), limiting their ability to live independently. This paper details a robotic mobility scooter developed to assist with manipulation-based ADLs to increase independence. We present a system comprised of a Universal Robotics UR5 robotic arm, a mobility scooter, five depth sensors, and a user interface which utilizes laser pointers. The system provides pick-and-drop and pick-and-place functionality in open world environments without modeling the objects or environment. We evaluate our system over several experimental scenarios and show an improvement relative to a baseline established for a similar system.
Deictic Image Maps: An Abstraction For Learning Pose Invariant Manipulation Policies
Sep 17, 2018


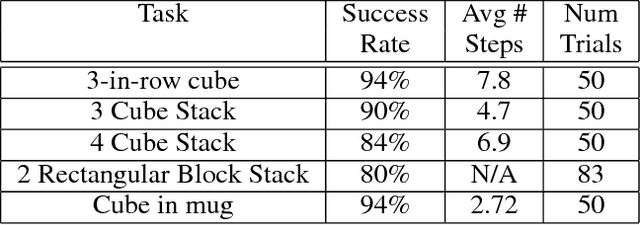
In applications of deep reinforcement learning to robotics, it is often the case that we want to learn pose invariant policies: policies that are invariant to changes in the position and orientation of objects in the world. For example, consider a peg-in-hole insertion task. If the agent learns to insert a peg into one hole, we would like that policy to generalize to holes presented in different poses. Unfortunately, this is a challenge using conventional methods. This paper proposes a novel state and action abstraction that is invariant to pose shifts called \textit{deictic image maps} that can be used with deep reinforcement learning. We provide broad conditions under which optimal abstract policies are optimal for the underlying system. Finally, we show that the method can help solve challenging robotic manipulation problems.