 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePick and Place Without Geometric Object Models
Paper and Code

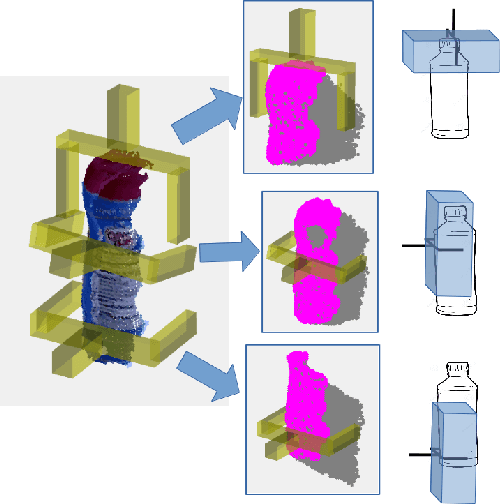
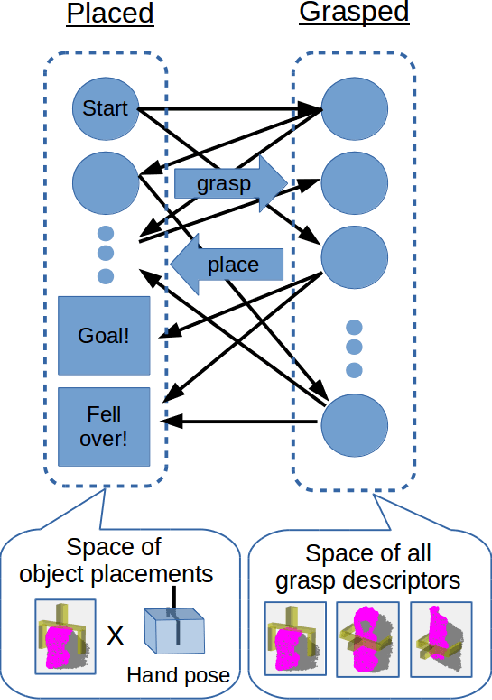
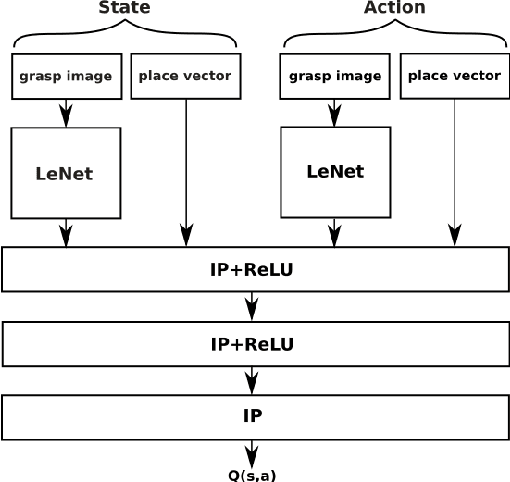
We propose a novel formulation of robotic pick and place as a deep reinforcement learning (RL) problem. Whereas most deep RL approaches to robotic manipulation frame the problem in terms of low level states and actions, we propose a more abstract formulation. In this formulation, actions are target reach poses for the hand and states are a history of such reaches. We show this approach can solve a challenging class of pick-place and regrasping problems where the exact geometry of the objects to be handled is unknown. The only information our method requires is: 1) the sensor perception available to the robot at test time; 2) prior knowledge of the general class of objects for which the system was trained. We evaluate our method using objects belonging to two different categories, mugs and bottles, both in simulation and on real hardware. Results show a major improvement relative to a shape primitives baseline.