 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePack it in: Packing into Partially Filled Containers Through Contact
Feb 15, 2026The automation of warehouse operations is crucial for improving productivity and reducing human exposure to hazardous environments. One operation frequently performed in warehouses is bin-packing where items need to be placed into containers, either for delivery to a customer, or for temporary storage in the warehouse. Whilst prior bin-packing works have largely been focused on packing items into empty containers and have adopted collision-free strategies, it is often the case that containers will already be partially filled with items, often in suboptimal arrangements due to transportation about a warehouse. This paper presents a contact-aware packing approach that exploits purposeful interactions with previously placed objects to create free space and enable successful placement of new items. This is achieved by using a contact-based multi-object trajectory optimizer within a model predictive controller, integrated with a physics-aware perception system that estimates object poses even during inevitable occlusions, and a method that suggests physically-feasible locations to place the object inside the container.
Realistic adversarial scenario generation via human-like pedestrian model for autonomous vehicle control parameter optimisation
Jan 05, 2026Autonomous vehicles (AVs) are rapidly advancing and are expected to play a central role in future mobility. Ensuring their safe deployment requires reliable interaction with other road users, not least pedestrians. Direct testing on public roads is costly and unsafe for rare but critical interactions, making simulation a practical alternative. Within simulation-based testing, adversarial scenarios are widely used to probe safety limits, but many prioritise difficulty over realism, producing exaggerated behaviours which may result in AV controllers that are overly conservative. We propose an alternative method, instead using a cognitively inspired pedestrian model featuring both inter-individual and intra-individual variability to generate behaviourally plausible adversarial scenarios. We provide a proof of concept demonstration of this method's potential for AV control optimisation, in closed-loop testing and tuning of an AV controller. Our results show that replacing the rule-based CARLA pedestrian with the human-like model yields more realistic gap acceptance patterns and smoother vehicle decelerations. Unsafe interactions occur only for certain pedestrian individuals and conditions, underscoring the importance of human variability in AV testing. Adversarial scenarios generated by this model can be used to optimise AV control towards safer and more efficient behaviour. Overall, this work illustrates how incorporating human-like road user models into simulation-based adversarial testing can enhance the credibility of AV evaluation and provide a practical basis to behaviourally informed controller optimisation.
Realistic pedestrian-driver interaction modelling using multi-agent RL with human perceptual-motor constraints
Oct 31, 2025Modelling pedestrian-driver interactions is critical for understanding human road user behaviour and developing safe autonomous vehicle systems. Existing approaches often rely on rule-based logic, game-theoretic models, or 'black-box' machine learning methods. However, these models typically lack flexibility or overlook the underlying mechanisms, such as sensory and motor constraints, which shape how pedestrians and drivers perceive and act in interactive scenarios. In this study, we propose a multi-agent reinforcement learning (RL) framework that integrates both visual and motor constraints of pedestrian and driver agents. Using a real-world dataset from an unsignalised pedestrian crossing, we evaluate four model variants, one without constraints, two with either motor or visual constraints, and one with both, across behavioural metrics of interaction realism. Results show that the combined model with both visual and motor constraints performs best. Motor constraints lead to smoother movements that resemble human speed adjustments during crossing interactions. The addition of visual constraints introduces perceptual uncertainty and field-of-view limitations, leading the agents to exhibit more cautious and variable behaviour, such as less abrupt deceleration. In this data-limited setting, our model outperforms a supervised behavioural cloning model, demonstrating that our approach can be effective without large training datasets. Finally, our framework accounts for individual differences by modelling parameters controlling the human constraints as population-level distributions, a perspective that has not been explored in previous work on pedestrian-vehicle interaction modelling. Overall, our work demonstrates that multi-agent RL with human constraints is a promising modelling approach for simulating realistic road user interactions.
Online state vector reduction during model predictive control with gradient-based trajectory optimisation
Aug 21, 2024
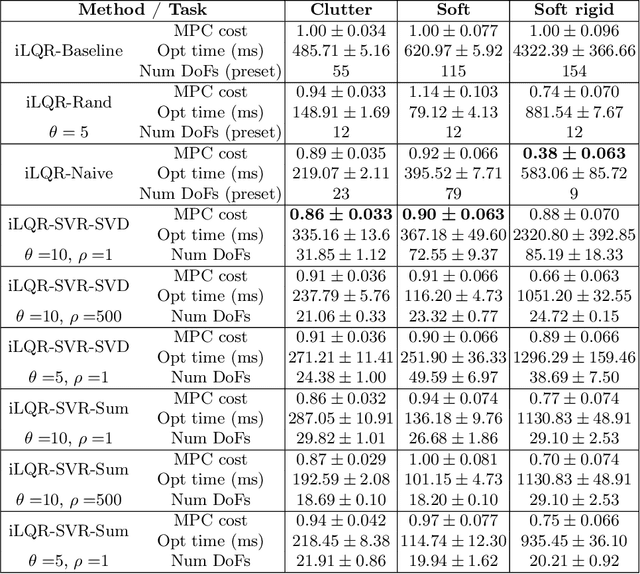


Non-prehensile manipulation in high-dimensional systems is challenging for a variety of reasons, one of the main reasons is the computationally long planning times that come with a large state space. Trajectory optimisation algorithms have proved their utility in a wide variety of tasks, but, like most methods struggle scaling to the high dimensional systems ubiquitous to non-prehensile manipulation in clutter as well as deformable object manipulation. We reason that, during manipulation, different degrees of freedom will become more or less important to the task over time as the system evolves. We leverage this idea to reduce the number of degrees of freedom considered in a trajectory optimisation problem, to reduce planning times. This idea is particularly relevant in the context of model predictive control (MPC) where the cost landscape of the optimisation problem is constantly evolving. We provide simulation results under asynchronous MPC and show our methods are capable of achieving better overall performance due to the decreased policy lag whilst still being able to optimise trajectories effectively.
The Teenager's Problem: Efficient Garment Decluttering With Grasp Optimization
Oct 25, 2023



This paper addresses the ''Teenager's Problem'': efficiently removing scattered garments from a planar surface. As grasping and transporting individual garments is highly inefficient, we propose analytical policies to select grasp locations for multiple garments using an overhead camera. Two classes of methods are considered: depth-based, which use overhead depth data to find efficient grasps, and segment-based, which use segmentation on the RGB overhead image (without requiring any depth data); grasp efficiency is measured by Objects per Transport, which denotes the average number of objects removed per trip to the laundry basket. Experiments suggest that both depth- and segment-based methods easily reduce Objects per Transport (OpT) by $20\%$; furthermore, these approaches complement each other, with combined hybrid methods yielding improvements of $34\%$. Finally, a method employing consolidation (with segmentation) is considered, which manipulates the garments on the work surface to increase OpT; this yields an improvement of $67\%$ over the baseline, though at a cost of additional physical actions.
The Busboy Problem: Efficient Tableware Decluttering Using Consolidation and Multi-Object Grasps
Jul 08, 2023



We present the "Busboy Problem": automating an efficient decluttering of cups, bowls, and silverware from a planar surface. As grasping and transporting individual items is highly inefficient, we propose policies to generate grasps for multiple items. We introduce the metric of Objects per Trip (OpT) carried by the robot to the collection bin to analyze the improvement seen as a result of our policies. In physical experiments with singulated items, we find that consolidation and multi-object grasps resulted in an 1.8x improvement in OpT, compared to methods without multi-object grasps. See https://sites.google.com/berkeley.edu/busboyproblem for code and supplemental materials.
Real-Time Physics-Based Object Pose Tracking during Non-Prehensile Manipulation
Nov 24, 2022



We propose a method to track the 6D pose of an object over time, while the object is under non-prehensile manipulation by a robot. At any given time during the manipulation of the object, we assume access to the robot joint controls and an image from a camera looking at the scene. We use the robot joint controls to perform a physics-based prediction of how the object might be moving. We then combine this prediction with the observation coming from the camera, to estimate the object pose as accurately as possible. We use a particle filtering approach to combine the control information with the visual information. We compare the proposed method with two baselines: (i) using only an image-based pose estimation system at each time-step, and (ii) a particle filter which does not perform the computationally expensive physics predictions, but assumes the object moves with constant velocity. Our results show that making physics-based predictions is worth the computational cost, resulting in more accurate tracking, and estimating object pose even when the object is not clearly visible to the camera.
Learning to Efficiently Plan Robust Frictional Multi-Object Grasps
Oct 13, 2022

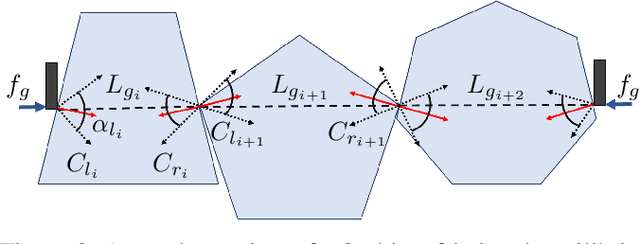

We consider a decluttering problem where multiple rigid convex polygonal objects rest in randomly placed positions and orientations on a planar surface and must be efficiently transported to a packing box using both single and multi-object grasps. Prior work considered frictionless multi-object grasping. In this paper, we introduce friction to increase picks per hour. We train a neural network using real examples to plan robust multi-object grasps. In physical experiments, we find an 11.7% increase in success rates, a 1.7x increase in picks per hour, and an 8.2x decrease in grasp planning time compared to prior work on multi-object grasping. Videos are available at https://youtu.be/pEZpHX5FZIs.
How accurate models of human behavior are needed for human-robot interaction? For automated driving?
Feb 12, 2022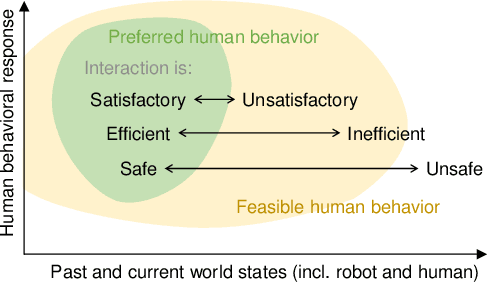
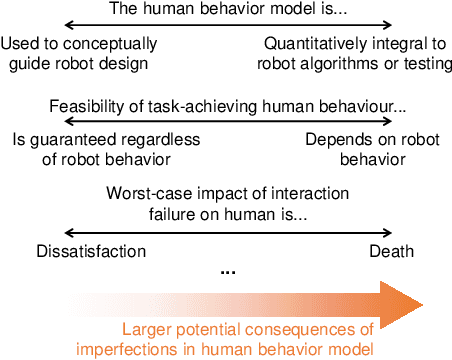

There are many examples of cases where access to improved models of human behavior and cognition has allowed creation of robots which can better interact with humans, and not least in road vehicle automation this is a rapidly growing area of research. Human-robot interaction (HRI) therefore provides an important applied setting for human behavior modeling - but given the vast complexity of human behavior, how complete and accurate do these models need to be? Here, we outline some possible ways of thinking about this problem, starting from the suggestion that modelers need to keep the right end goal in sight: A successful human-robot interaction, in terms of safety, performance, and human satisfaction. Efforts toward model completeness and accuracy should be focused on those aspects of human behavior to which interaction success is most sensitive. We emphasise that identifying which those aspects are is a difficult scientific objective in its own right, distinct for each given HRI context. We propose and exemplify an approach to formulating a priori hypotheses on this matter, in cases where robots are to be involved in interactions which currently take place between humans, such as in automated driving. Our perspective also highlights some possible risks of overreliance on machine-learned models of human behavior in HRI, and how to mitigate against those risks.
Parareal with a Learned Coarse Model for Robotic Manipulation
Dec 12, 2019


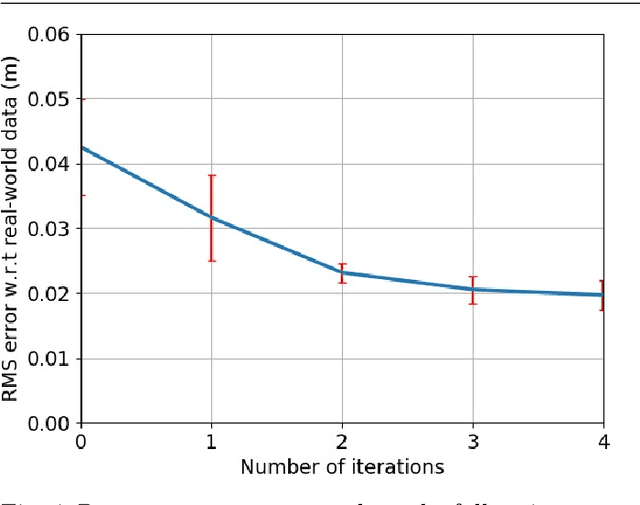
A key component of many robotics model-based planning and control algorithms is physics predictions, that is, forecasting a sequence of states given an initial state and a sequence of controls. This process is slow and a major computational bottleneck for robotics planning algorithms. Parallel-in-time integration methods can help to leverage parallel computing to accelerate physics predictions and thus planning. The Parareal algorithm iterates between a coarse serial integrator and a fine parallel integrator. A key challenge is to devise a coarse level model that is computationally cheap but accurate enough for Parareal to converge quickly. Here, we investigate the use of a deep neural network physics model as a coarse model for Parareal in the context of robotic manipulation. In simulated experiments using the physics engine Mujoco as fine propagator we show that the learned coarse model leads to faster Parareal convergence than a coarse physics-based model. We further show that the learned coarse model allows to apply Parareal to scenarios with multiple objects, where the physics-based coarse model is not applicable. Finally, We conduct experiments on a real robot and show that Parareal predictions are close to real-world physics predictions for robotic pushing of multiple objects. Some real robot manipulation plans using Parareal can be found at https://www.youtube.com/watch?v=wCh2o1rf-gA .