 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline state vector reduction during model predictive control with gradient-based trajectory optimisation
Paper and Code

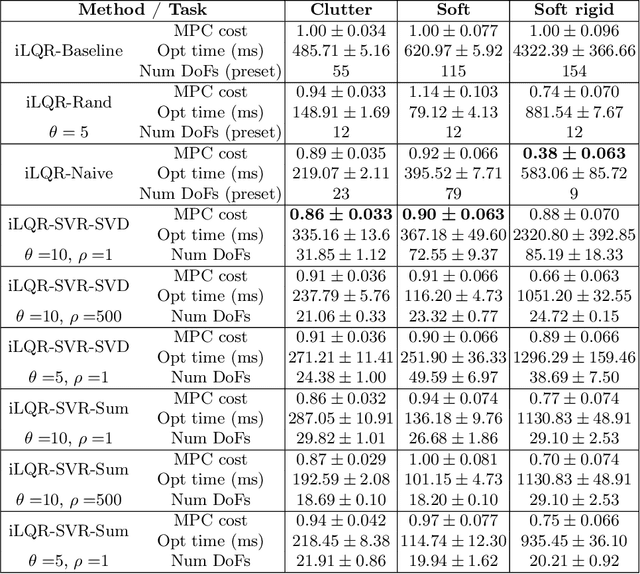


Non-prehensile manipulation in high-dimensional systems is challenging for a variety of reasons, one of the main reasons is the computationally long planning times that come with a large state space. Trajectory optimisation algorithms have proved their utility in a wide variety of tasks, but, like most methods struggle scaling to the high dimensional systems ubiquitous to non-prehensile manipulation in clutter as well as deformable object manipulation. We reason that, during manipulation, different degrees of freedom will become more or less important to the task over time as the system evolves. We leverage this idea to reduce the number of degrees of freedom considered in a trajectory optimisation problem, to reduce planning times. This idea is particularly relevant in the context of model predictive control (MPC) where the cost landscape of the optimisation problem is constantly evolving. We provide simulation results under asynchronous MPC and show our methods are capable of achieving better overall performance due to the decreased policy lag whilst still being able to optimise trajectories effectively.